为什么Python是伪多线程
这是我在字节面试中,面试官问的一个问题。当时没有答出来。
进程和线程
我们先来解释下线程和进程的概念。
- 一个进程可以包含多个线程。在Linux中,我们使用
ps -ef来查看所有的进程,每个进程都有一个pid,且唯一。 - 线程可以利用进程所拥有的资源,操作系统中,通常把进程作为分配资源的基本单位,把线程作为独立运行和独立调度的基本单位。即进程有用独立的内存空间,而线程没有单独的内存空间,多个线程是共享内存的,同一进程中多个线程之间数据是共享的。
- 进程一般有3个状态:就绪、运行、阻塞。
- 就绪:程序获取了除CPU外的所有资源,只要处理器分配资源,就可以马上执行。
- 运行:进程得到了处理器分配的资源,程序开始执行。
- 阻塞:当程序条件不够时,需要等待条件满足的时候才可以执行。比如等待I/O操作
- 当一个进程启动后,会默认产生一个主线程,如果你的程序设置的是多线程,那主线程就会创建多个子线程。
- 多线程是为了同一时间完成多项任务,并不是为了提高运行效率,而是为了提高资源的使用率,从而来提高系统的效率。
- 最简单的比喻是:进程是一个火车,而线程是每一节车厢。
【总结】
进程和线程的关系:
- 一个线程只能属于一个进程,而一个进程可以有多个线程,至少有一个线程。
- 资源分配给进程,同一进程的所有线程共享该进程的所有资源。
- 处理器分给线程,即真正在处理机上运行的是线程。
- 线程在执行过程中,需要协作同步。不同进程的线程间要利用消息通信的办法实现同步。线程是指进程内的一个执行单元,也是进程内的可调度实体.
进程与线程的区别:
- 调度:线程作为调度和分配的基本单位,进程作为拥有资源的基本单位
- 并发性:不仅进程之间可以并发执行,同一个进程的多个线程之间也可并发执行
- 拥有资源:进程是拥有资源的一个独立单位,线程不拥有系统资源,但可以访问隶属于进程的资源.
- 系统开销:在创建或撤消进程时,由于系统都要为之分配和回收资源,导致系统的开销明显大于创建或撤消线程时的开销。
并行
在一个进程中,多个线程可以同时进行。此时的“同时”,在原先的单核架构中,其实是“伪并行”,即让线程以极短的时间间隔交替执行,在人看来就向它们在同时执行一样。但由于只有一个核(计算单元),当线程都是计算密集型任务时,多线程的优势就没有那么大。
而“真正的并行”执行在多核架构上实现。对于计算密集型任务,巧妙的使用多线程将任务分配到多个CPU上。
- 并发:只有一个CPU时,同一时间只有1个线程在执行。当有多个线程时,每个线程在很小间隔内交替执行。
- 并行:当有多个CPU时,一个CPU执行一个线程,另一个CPU可以执行另一个线程。2个线程互不抢占CPU资源,可以同时进行。
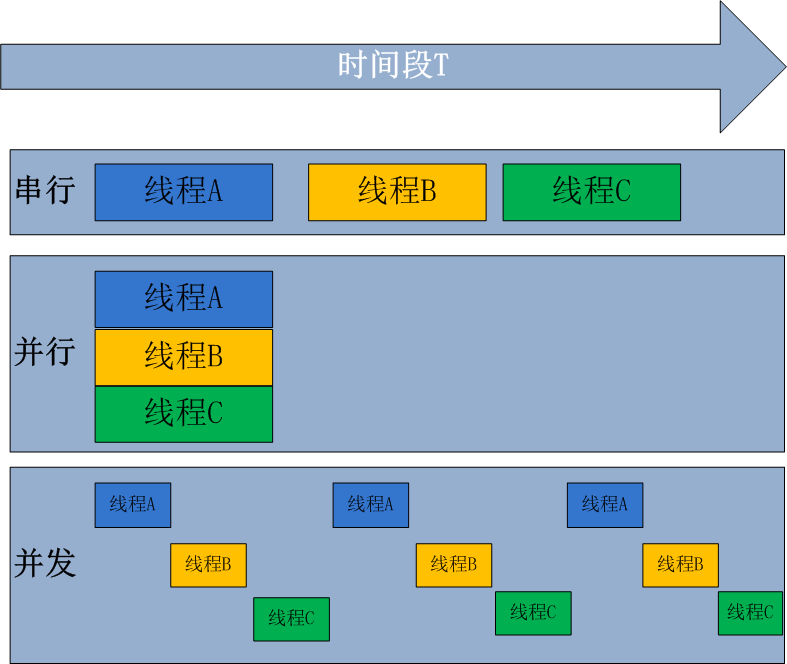
Python伪多线程
GIL (Global Interpreter Lock)全局解释锁是Python解释器中的核心部件。
每个进程都有自己的GIL,一个进程只有1个GIL,用来保护Python的内部对象在进程中是唯一的。对Python解释器的访问由全局解释器锁来控制。由于全局解释器锁的存在,同时只有一个线程运行。
GIL的作用:
- 为了线程间数据的一致性。例如线程2需要线程1的结果,然后线程2的执行时间又比线程1短,必须保证线程1执行完之后,线程2才能开始执行。
GIL保证了线程安全,但是也带来一个问题,每个时刻只有一个线程在执行。即使你的电脑有多个CPU,由于GIL的存在,Python中同一时间下也只有1个线程在执行,无法利用多核优势。
那Python中多线程怎么使用多核?
- 换Python解释器
- 调用C语言的链接库。
Python中什么时候用多线程?
I/O密集型任务比计算密集型任务,更能发挥多线程的优势。
- 计算密集型任务就是进行大量的计算,消耗CPU资源。比如计算圆周率,对视频进行解码等,全靠CPU的运算能力。这种计算密集型任务虽然也可以多线程完成,但是线程越多,任务切换的时间就越多,CPU的执行效率就越低。所以为了高效的利用CPU,计算密集型任务同时进行的数量应该等于CPU的核心数。
- I/O密集型任务,涉及到网络,磁盘I/O的任务都是I/O密集型任务。这类任务CPU消耗少,任务的大部分时间都在等待I/O操作完成。对于I/O密集型任务,任务越多,CPU效率越高,但也有一个限度。常见的大部分任务都是I/O密集型任务,比如Web应用。
为什么Python比C/C++慢
这是我在字节面试中,面试官问的一个问题。当时没有答出来。
- Python使用的是动态类型,一个变量可以是任何类型。那么在执行的时候需要不断地判断数据类型,带来很大的开销。
- Python是解释性语言,而C/C++是编译型语言。C++所有代码都会在编译阶段翻译成机器码,机器码就是系统能直接理解的码,实际执行中只需要调用就可以了,只翻译一次机器码,所以很快。Python是解释性语言,没运行一次都要翻译一次,相对较慢。
- 但是Python开发效率高,人生苦短,我用Python。
而C/C++是先编译成可执行的二进制代码在运行。并且C/C++没有动态类型。
1. 规范
- 运算符的左右加空格,例如a + b
- 如果有多行赋值,将上下赋值的=对齐
num = 1
secNum = 2 - 变量的所有字母小写,单词之间用下划线连接,table_name=’test’
2. 序列
序列是一种容器,是有顺序的数据集合。序列有两种:元组(Tuple)和列表(List)。列表是可变的,元组是不可变的。所以经常会创建空的列表,a=[],而不会创建一个空的元组。
对序列(元组和列表)范围引用,a[起始,结束,步长],包含起始,不包含结束。循环获取序列的值:for i in list,这里的a就是值,而不是下标
3. 词典
词典中的数据是无序的,不能通过位置下标来获取
4. ndarray和list
list是Python的内置数据类型,list中的数据类型不必相同。例如:[1,2,'a',3.9]。
首先需要明确的一点是array和ndarray是什么。ndarray是一种类型,array不是一种数据类型,可以通过np.array()来创建一个ndarray的对象。ndarray是numpy的一种数据类型,ndarray中的元素类型必须相同,例如:[1,2,3,4]
4.1. 创建ndarray
4.1.1. 通过np.array
通过np.array()来创建,传入的参数可以是list,也可以是tuple,使用ndarray的shape属性来获取ndarray的形状1
2
3
4
a = np.array([1,2,3])
b = np.array(('a','b','c'))
c = np.array([[1,2,3],[4,5,6]])
使用reshape改变ndarray的形状c.reshape((3,-1)),reshape传入的形状是可以是
reshape((3,-1)),
reshape([3,1]),
reshape(3,-1)
4.1.2. 通过np.arange
numpy提供了很多方法直接创建一个ndarray对象.
1 | arr1=np.arange(1,10,1) |
结果
1 | [1 2 3 4 5 6 7 8 9] int32 |
np.arange(a,b,c)表示产生从a~b,不包括b,间隔为c的一个ndarray,数据类型默认是int32。
np.linspace(a,b,c)表示把a~b(包括b),平均分成c份。
np.arange()和range都可以用来生成序列。注意arange是numpy的函数,range可以直接调用。arange和range不同的是:range只能生成int类型,写rang(1,10,0.1)是错误的,arange可以生成float类型,可以写成np.arange(1,10,0.1)

使用print输出时,list中的元素之间有逗号分开,ndarray元素之间没有逗号。

虽然有很多产生ndarray类型的方法,但是大部分情况下我们都是从list进行转换生成ndarray。因为我们从文件中读取数据存储在list中,然后转换成ndarray
比如定义一个list,a = [1,2,3,4],然后使用np.array(a)将list转换成ndarray类型
4.1.3. list和ndarray的索引
定义一个listlist1=[[1,2,3],[4,5,6],[7,8,9]]
定义一个ndarrayarr1 = np.array(list1)
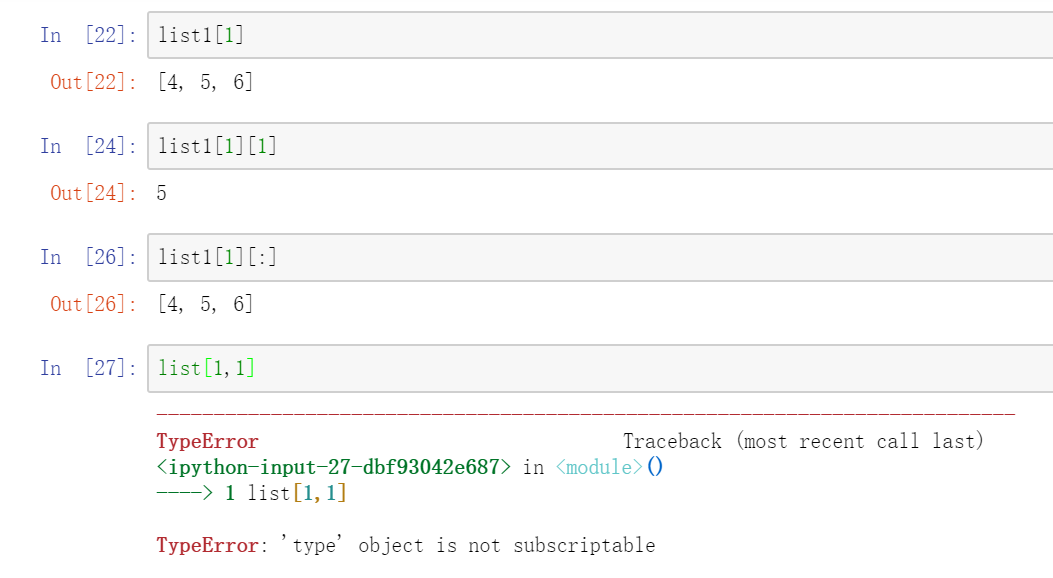

ndarray比list的索引方式更多,这也是两者经常遇到的区别。
因为list可以存储任意类型的数据,因为list中存储数据存放的地址,简单说就是指针,并非数据,这样保存一个list就太麻烦了,例如list1=[1,2,3,’a’]就需要4个指针和4个数据,增加了存储和CPU消耗
4.1.4. np.max()
numpy常用的统计函数如下:
- np.sum(),返回求和
- np.mean(),返回均值
- np.max(),返回最大值
- np.min(),返回最小值
- np.ptp(),数组沿指定轴返回最大值减去最小值,即(max-min)
- np.std(),返回标准偏差(standard deviation)
- np.var(),返回方差(variance)
- np.cumsum(),返回累加值
- np.cumprod(),返回累乘积值
注意:在使用以上这些函数时,需要指定axis的方向,若不指定,默认统计整个数组。axis=0表示列,axis=1表示行。一般axis=0比较符合实际情况。

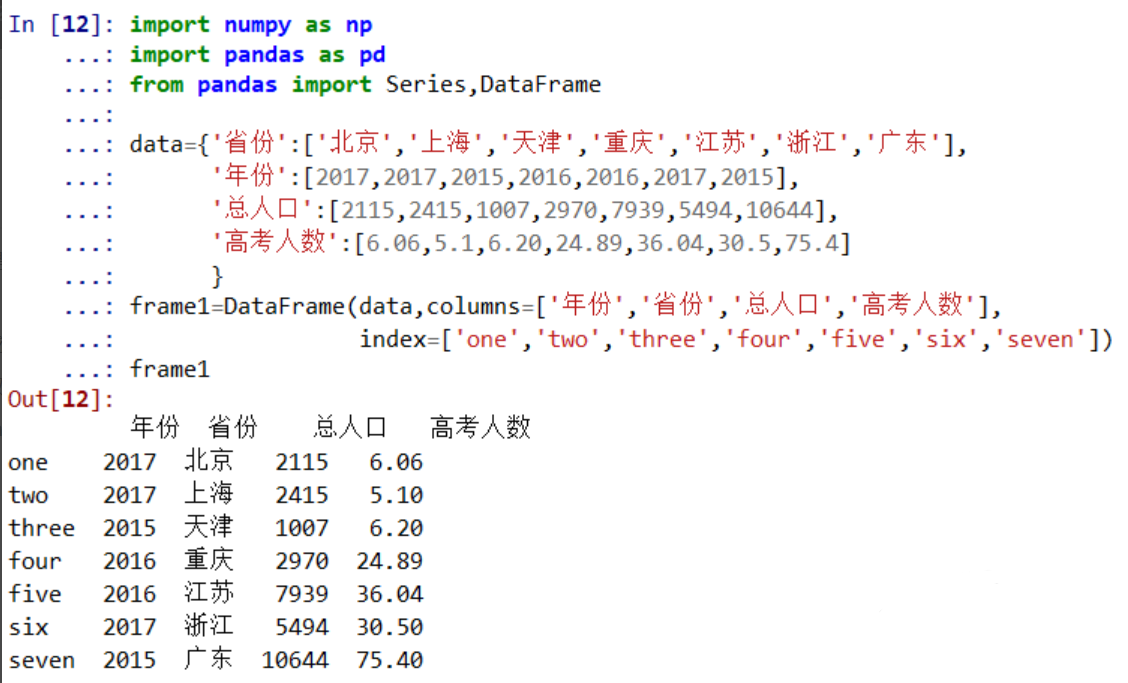
5. Pandas
DataFrame根据某一列排序,其中inplace=True表示修改df的值,默认是false,表示不修改df的值,会返回一个排好序的DataFrame。df.sort_values("数据时间",inplace=True)
排好序的dataframe的index列还是原先dataframe的index。比如下面的图是排序之间的dataframe
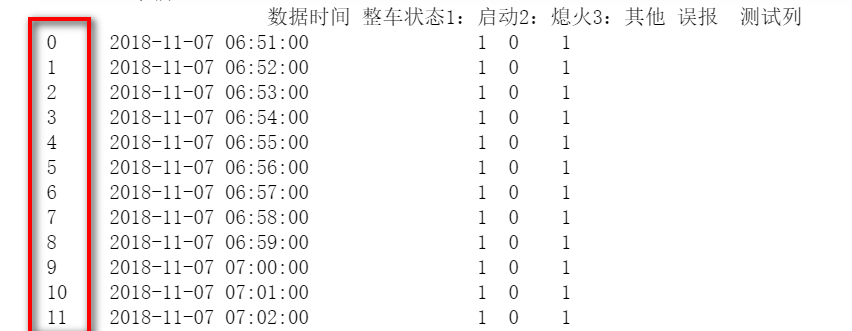
使用df.sort_values("数据时间",inplace=True)按照时间排序,但是index还是原先的index,我想让排序后的dataframe的index从0开始。
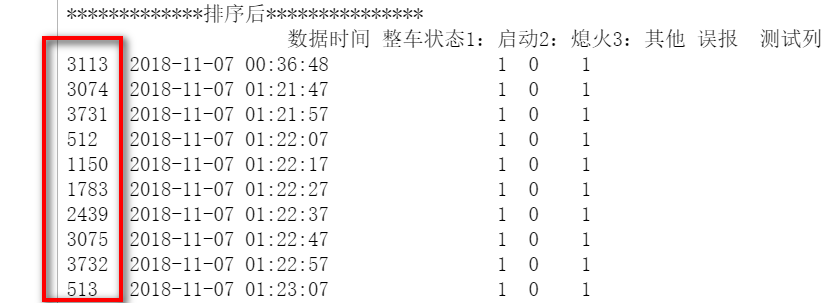
df[2:4]表示返回第3和4行的数据,即索引为3731,512这2行的数据,而不是返回索引为2和3的数据。
使用sort_df.reset_index(drop=True, inplace=True) 重新定义索引,使其从0开始。
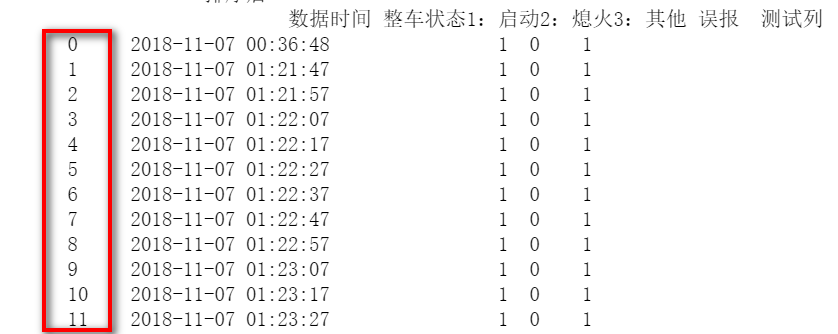
获取dataframe中的索引firstIndex = df.index.tolist() 返回一个list,存储的是dataframe中的索引列表。firstIndex = df.index.tolist()[0] 返回的是第一行数据的索引firstIndex = df.index.tolist()[-1] 返回的是最后一行数据的索引
获取dataframe中的数据
df[1:4]表示获取表的第2至4行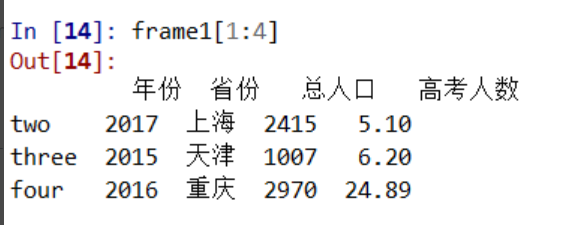
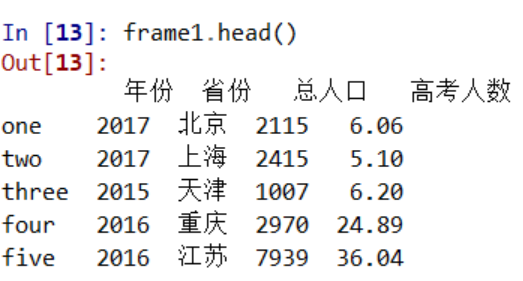
df.head()默认返回dataframe中的前5行,如果返回前10行,使用head(10)
使用
df.iloc[]和df.loc[]获取数据。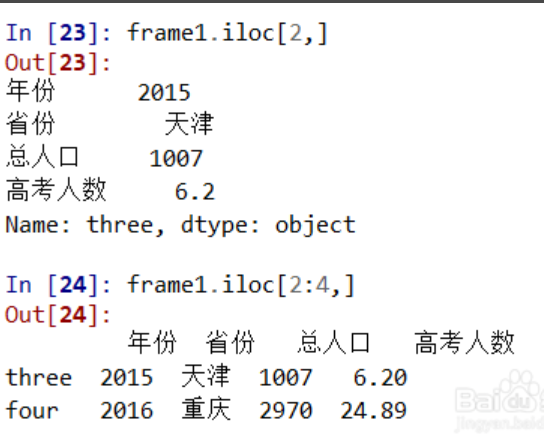
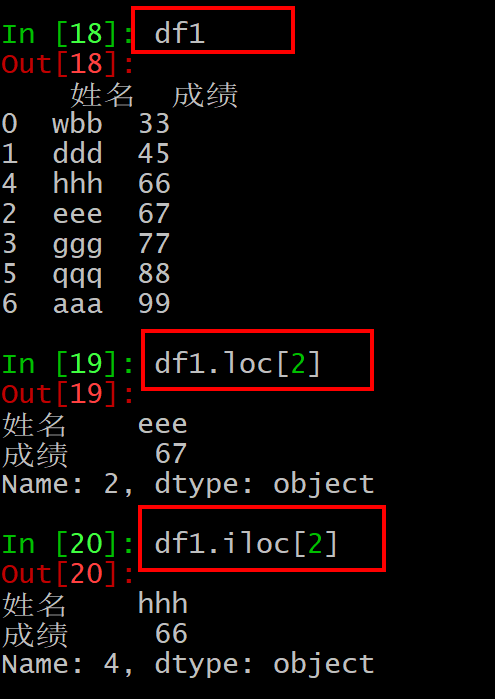
通过 df.iloc[]传入的参数是数据,而df.loc[]传入的参数是字符串索引,除非索引是数字,这时loc[]可以传入数字。
比如df1.loc[2]表示获取索引为’2’的那一行,而df.iloc[2]表示获取df1的第3行数据,是一个相对位置。
参考资料:
https://www.jb51.net/article/141665.htm
DateFrame常用方法
- 获取df中某一列特征值的个数
credit_df['Class'].value_counts()或credit_df['Class'].value_counts()[0] - 显示df中的详细信息
df.info()df.describe() - 获取df中的所有列名
col_names = list(df.columns.values) - 将df按照某一特征进行分组
df.groupby(['total_vol']).size()获取每个组中元素的个数df.groupby(['total_vol','soc']).size()按照多个属性分组 从df中获取样本的特征和标签
1
2
3
4#获取特征
X = df.drop("误报",axis = 1)
#获取标签
Y = df["误报"]获取df中的一列或多列
1
2
3one_col = df['total_vol']
multi_cols_name = ['total_vol','soc','cur']
multi_cols = df[multi_cols_name]查看df中为空的个数,输出每一列为nan的个数
df.isna().sum()
Dict
python创建一个字典有3中方式
1 | class dict(**kwarg) |
其中**kwarg是python中可变参数,代表关键字参数,允许你传入0个或任意多个含参数名的参数,这个关键字参数在函数内部自动组装成一个dict。
class dict(**kwarg)
通过关键字参数创建一个字典,例如1
2
3
4
5d = dict(name='Tom',age=23)
out: {'age': 23, 'name': 'Tom'}
d = dict(a = 12, b = 13, c = 15)
out: {'a': 12, 'b': 13, 'c': 15}class dict(mapping,kwarg)
通过从一个映射函数对象中构造一个新字典,与dict(kwarg)函数不一样的地方是参数输入是一个映射类型的函数对象,比如zip函数,map函数1
2
3#以映射函数方式来构造字典
d2 = dict(zip(['one', 'two', 'three'], [1, 2, 3]))
out: {'one': 1, 'three': 3, 'two': 2}class dict(iterable,**kwarg)
其中iterable表示可迭代对象,可迭代对象可以使用for…in…来遍历,在Pytohn中list,tuple,str,dict,set等都是可迭代对象。创建dict时如果传入的是可迭代对象,则可迭代对象中每一项自身必须是可迭代的,并且每一项只能由有2个对象,第一个对象称为字典的key,第二个对象为key对应的value。如果key有重复,其value为最后重复项的值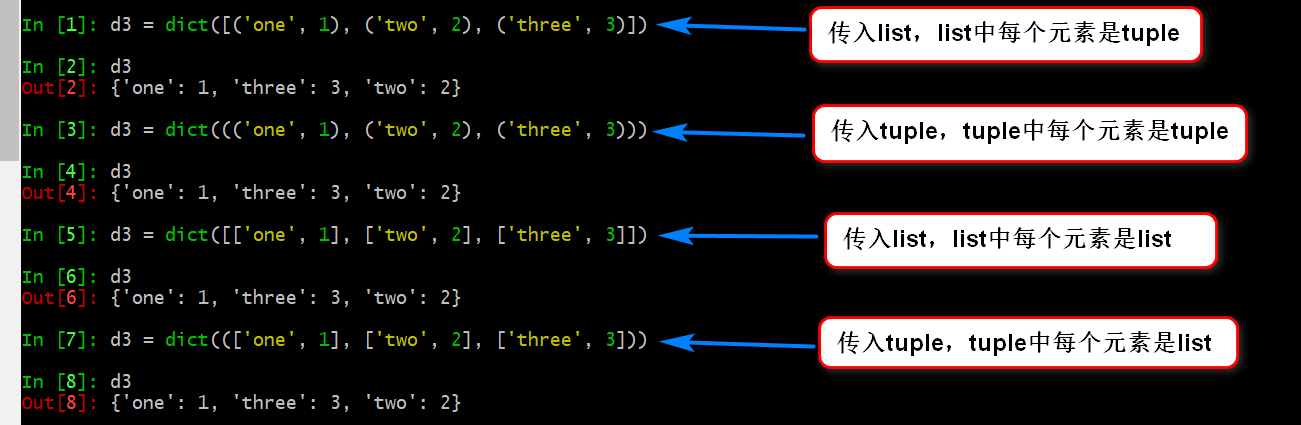
函数参数
在python中定义一个函数,可以传入4种参数:
位置参数,默认参数,关键字参数,可变参数
位置参数
普通的参数,参数之间是有顺序的, 顺序不能写错
1 | def power(x, n): |
关键字参数
函数调用时使用关键字参数来确定传入的参数值,使用关键字参数允许函数调用时参数的顺序和声明的顺序不一致,因为python解释器会根据参数名来匹配参数值。使用key=value格式来指定参数。
1 |
|
1 | 可写函数说明 |
注意:关键字参数必须写在位置参数之后,否则会报错
默认参数
在定义函数时,使用赋值运算符=就为参数设置了一个默认值,默认参数是可选的,就是说可以指定,也可以不指定。当不指定时就使用默认值,如果指定,会覆盖默认值。有了一个默认参数,这样即使传入调用power(5),这样就默认n=2,如果要计算的幂次大于2,就需要明确的指定n的值,power(5,3),这是n=3
1 | def power(x, n=2): |
设置默认参数时,需要注意以下几点:
- 必选参数在前面,默认参数在后面,否则Python的解释器会报错
使用默认参数的好处是:比如学生注册的时候,需要传入的参数为:姓名,性别,年龄。把年龄设置为默认参数19,这样大部分学生注册时不需要提供年龄,只需要提供2个必须的参数,只有与默认参数不符的学生才提供额外的信息。可见,使用默认参数降低了函数调用的难度
1 | def enroll(name, gender,age=19): |
可变参数
可变参数就是传入的参数个数是可变的,可以是1个、2个到任意个,还可以是0个。 当函数中有位置参数和可变参数时,位置参数始终在可变参数之前。通常情况下,可变参数会出现在形参的最后,因为它们会把传递给函数的所有剩余参数都收集起来。可变参数之后出现的任何参数都是“强制关键字”参数,也就是说,可变参数之后的参数必须是关键字参数,而不能是位置参数。
*args
我们以数学题为例子,给定一组数字a,b,c……,请计算a2 + b2 + c2 + ……。
1 | def calc(*numbers): |
在函数内部,参数number接收到的是一个tuple,例如calc(1,2)得出来的结果是5,也可以直接传入一个list或者tuple,在list或tuple前面加上一个*,把list或tuple的元素变成可变参数传进去。
1 | nums1 = [1, 2, 3] |
**args
可变参数允许传入0个或任意个参数,这些可变参数在函数调用时自动组装为一个tuple。而关键字参数允许你传入0个或任意个含参数名称的参数,这些关键字参数函数内部自动组装成一个dict
1 | def person(name, age, **kw): |
总结
在函数定义时,参数的顺序为:位置参数,默认参数,args,\*args
在函数调用时,参数的顺序为位置参数、关键字参数/默认参数,args,\*args
文件读取
当一个文件很大时,不能一次性读取所有的内容加载到内存中,需要使用生成器
1 | def read_file(filename): |

