最近去给甲方安装CDH集群,对于集群的搭建和测试在这里总结一下。
- 1. 版本控制
- 2. Linux目录介绍
- 3. 安装前说明
- 4. 小常识
- 5. 安装CDH集群
- 5.1. 关闭所有机器的防火墙
- 5.2. 修改机器的hosts
- 5.3. 查看网络是否连通
- 5.4. 生成主节点的ssh密钥并分发
- 5.5. 安装ntp服务
- 5.6. 卸载机器自带的openjdk
- 5.7. 安装JDK
- 5.8. 安装MySQL
- 5.9. 创建MySQL数据库
- 5.10. 安装Cloudera Manager Server和Agent
- 5.11. 打开网页配置
- 5.12. HDFS的HA安装
- 5.13. 安装Anaconda
- 5.14. 安装Spark(standalone)
- 5.15. 修改hdfs权限
- 5.16. 安装python三方库
- 5.17. 安装kafka
- 5.18. yarn
1. 版本控制
| 组件 | 版本 |
|---|---|
| CenOS | CenOS7 |
| JDK | JDK1.8 |
| CDH集群 | CDH5.7.2 |
| CDH-kafka | CDH-kafka1.2.0 |
| Python | Python3.5 |
现在实验室的cdh集群版本是CDH5.7.2,其中每个组件的版本是
| 组件 | CDH5.7.2 | CDH5.16.1 |
|---|---|---|
| Hadoop | 2.6.0 | 2.6.0 |
| HDFS | 2.6.0 | 2.6.0 |
| HBase | 1.2.0 | 1.2.0 |
| Hive | 1.1.0 | 1.1.0 |
| Spark | 1.6.0 | 1.6.0 |
| Kafka | 0.10.0 | 0.10.0 |
| Zookeeper | 3.4.5 | 3.4.5 |
以后安装CDH集群,应该安装CDH5.16.1版本
2. Linux目录介绍
| 目录 | 说明 | 备注 |
|---|---|---|
| bin | 存储普通用户可执行的指令 | 即使在单用户模式下也能够执行处理 |
| dev | 设备目录 | 所有的硬件设备及周边均放置在这个设备目录中 |
| home | 主要存放用户的个人数据 | 每个用户在home中都有一个文件夹(除root外),存储每个用户的设置文件,用户的桌面文件夹、用户的数据 |
| etc | 各种配置文件目录 | 大部分配置属性均存放在这里 |
| lib/lib64 | 开机时常用的动态链接库 | bin及sbin指令也会调用对应的lib库 |
| opt | 第三方软件安装目录 | 现在习惯放在/usr/local中 |
| run | 系统运行所需的文件 | 重启后重新生成对一个的目录数据 |
| sbin | 只有root用户才能运行的管理指令 | 跟bin类似,但只属于root管理员 |
| tmp | 存储临时文件目录 | 所有用户对该目录均可读写 |
| usr | 应用程序放置目录 | /usr/local存储那些手动安装的软件,/usr/bin存储程序,/usr/share存储一些共享数据,例如音乐文件或者图标,/usr/lib存储那些不能直接运行的,但却是很多程序运行所必须的一些函数库文件 |
3. 安装前说明
- Zookeeper和Kafka不分主节点,要装3台
- HBase和HDFS分主从节点,都需要2个主节点,一个active主节点,一个standby主节点,剩下的机器作为从节点
- 关闭防火墙,安装ntp、jdk、mysql,anaconda可以同时进行。
- 本次以3个服务器为例安装CDH集群
- 192.168.1.201 node1
- 192.168.1.202 node2
- 192.168.1.203 node3
4. 小常识
- 使用vi命令编辑文件
- 键盘a———输入模式,编辑文件
- 键盘Esc——修改完之后按Esc退出输入模式
- :wq——-保存,并退出
- :q———不保存,退出
5. 安装CDH集群
5.1. 关闭所有机器的防火墙
每台机器都要执行
#关闭防火墙
systemctl stop firewalld.service
#禁止firewall开机启动
systemctl disable firewalld.service
#关闭selinux
vi /etc/selinux/config
将SELINUX设置为disabled
如下SELINUX=disabled
#重启
reboot
#重启机器后使用root用户查看Selinux状态
getenforce
5.2. 修改机器的hosts
每台机器都要执行
#使用ip addr查看每台机器的ip地址
#修改hosts文件
vi /etc/hosts
在最下面一行添加以下内容
192.168.1.201 node1
192.168.1.202 node2
192.168.1.203 node3
5.3. 查看网络是否连通
每台机器都要执行
#在node1上执行
ping node2
ping node3
#在其余两个节点分别ping
按Ctrl+C中断ping命令
5.4. 生成主节点的ssh密钥并分发
生成主节点root账户的ssh密钥,分发至其他机器,要实现免密码登录其他机器的root账户
只在node1上执行
#生成ssh密钥(node1上)
ssh-keygen -t rsa
然后一路回车
接下来分发密钥,请仔细观察显示的内容,会让你输入yes和密码
ssh-copy-id node1
ssh-copy-id node2
ssh-copy-id node3
5.5. 安装ntp服务
每台机器都要执行
yum install ntpdate
在执行这条命令时我的电脑出现以下错误:
问题:Could not resolve host: mirrorlist.centos.org Centos 7
解决方案:https://serverfault.com/questions/904304/could-not-resolve-host-mirrorlist-centos-org-centos-7
只在node1上执行yum install ntp
只在node1上执行
vi /etc/ntp.conf
注释以下4行,在前面加#
server 0.centos.pool.ntp.org iburst
server 1.centos.pool.ntp.org iburst
server 2.centos.pool.ntp.org iburst
server 3.centos.pool.ntp.org iburst
在最下面加上
restrict default ignore
restrict 192.168.1.0 mask 255.255.255.0
nomodify notrap
server 127.127.1.0
注意:192.168.1.0是这3台机器ip地址的前3位,最后一位是0
#重启ntp服务
service ntpd restart
#设置ntp服务器开机自动启动
chkconfig ntpd on
只在node2和node3执行
#以下为客户端的配置(除node1外的node2和node3),设定每天00:00向服务器(node1)同步时间,并写入日志
crontab -e
#输入以下内容后保存并退出
0 0 /usr/sbin/ntpdate *node1>> /root/ntpd.log
只在node2和node3执行
ntpdate node1
5.6. 卸载机器自带的openjdk
!!!!!!!一定要卸载
5.7. 安装JDK
安装自己的jdk到/opt/java/下面,如/opt/java/jdk1.8.0_90
只在node1上执行
首先使用filezilla把cdh_deployment压缩包上传到/usr下面,然后再opt下面创建一个java文件夹。
将jdk的安装包拷贝到/opt/java/下面
cp /usr/CDH_deployment/jdk-8u11-linux-x64.tar.gz /opt/java/
#解压
tar -zxvf jdk-8u11-linux-x64.tar.gz
#修改环境变量
vi /etc/profile
// 添加以下内容
export JAVA_HOME=/opt/java/jdk1.8.0_11/
export JRE_HOME=/opt/java/jdk1.8.0_11/jre
export CLASSPATH=.:\$JAVA_HOME/lib:\$JRE_HOME/lib:\$CLASSPATH
export PATH=\$JAVA_HOME/bin:\$JRE_HOME/bin:\$JAVA_HOME:\$PATH
#刷新配置文件
source /etc/profile
#复制jdk到其他服务器上
scp -r /opt/java/jdk1.8.0_11/ node2:/opt/java/
scp -r /opt/java/jdk1.8.0_11/ node3:/opt/java/
在node2执行
// WangBeibei-DC-2 上
vi /etc/profile
// 添加以下内容
export JAVA_HOME=/opt/java/jdk1.8.0_11/
export JRE_HOME=/opt/java/jdk1.8.0_11/jre
export CLASSPATH=.:\$JAVA_HOME/lib:\$JRE_HOME/lib:\$CLASSPATH
export PATH=\$JAVA_HOME/bin:\$JRE_HOME/bin:\$JAVA_HOME:\$PATH
在node3执行
vi /etc/profile
// 添加以下内容
export JAVA_HOME=/opt/java/jdk1.8.0_11/
export JRE_HOME=/opt/java/jdk1.8.0_11/jre
export CLASSPATH=.:\$JAVA_HOME/lib:\$JRE_HOME/lib:\$CLASSPATH
export PATH=\$JAVA_HOME/bin:\$JRE_HOME/bin:\$JAVA_HOME:\$PATH
测试java -version
看到java的版本说明安装成功
在每台上执行
mkdir /usr/java
ln -s /opt/java/jdk1.8.0_90/ /usr/java/default
5.8. 安装MySQL
只在node1上执行
yum remove mysql mysql-server mysql-libs compat-mysql51
rm -rf /var/lib/mysql
rm -rf /etc/my.cnf
将mysql.jar拷贝到/usr/local下面
解压
tar -zxvf /opt/mysql-5.6.37-linux-glibc2.12-x86_64.tar.gz
// 改名为mysql
mv mysql-5.6.37-linux-glibc2.12-x86_64 mysql
// 删除安装包
rm mysql-5.6.37-linux-glibc2.12-x86_64.tar.gz
// 修改环境变量
vi /etc/profile
在最下面添加
export MYSQL_HOME=/usr/lcoal/mysql
export PATH=\$MYSQL_HOME/bin:\$PATH
// 刷新环境变量
source /etc/profile
将服务文件mysql.server拷贝到init.d下
cp /usr/local/mysql/support-files/mysql.server /etc/init.d/mysql.server
MySQL开机自启,赋予可执行权限
chmod +x /etc/init.d/mysql.server
添加服务
chkconfig —add mysql.server
显示服务列表
chkconfig —list
如果看到mysql的服务,并且3、4、5都是on的话则成功。如果mysql.server的 3, 4, 5 不是on,使用下面的命令给他变成on:
chkconfig —level 345 mysql.server on
// 新建mysql 用户
groupadd mysql 在/etc/group 中可以看到
useradd -r -g mysql -s /bin/false mysql 在/etc/passwd 中可以看到
cd /usr/local/mysql
chown -R mysql:mysql .
scripts/mysql_install_db —user=mysql
// 修改当前目录拥有者为root 用户
chown -R root .
// 修改当前data 目录拥有者为mysql 用户
chown -R mysql data
// 新建一个虚拟窗口,叫mysql
screen -S mysql
bin/mysqld_safe —user=mysql &
// 退出虚拟窗口
Ctrl+A+D
cd /usr/local/mysql
// 登陆mysql
bin/mysql
// 登陆成功后退出即可
exit;
// 进行root 账户密码的修改等操作
bin/mysql_secure_installation
首先要求输入root 密码,由于我们没有设置过root 密码,括号里面说了,如果没有root 密码就直接按回车。
是否设定root 密码,选y,设定密码为cluster,是否移除匿名用户:y。然后有个是否关闭root 账户的远程
登录,选n,删除test 这个数据库?y,更新权限?y,然后ok。
cp support-files/mysql.server /etc/init.d/mysql.server
// 进入mysql 虚拟窗口
screen -r mysql
// 查看mysql 的进程号
ps -ef | grep mysql
// 如果有的话就kill 掉,保证mysql已经中断运行了,一般kill 掉/usr/local/mysql/bin/mysqld 开头的即可
kill 进程号
// 关闭虚拟窗口
exit
// 启动mysql
/etc/init.d/mysql.server start -user=mysql
exit
还需要配置一下访问权限,#授权root用户在主节点拥有所有数据库的访问权限:
$ mysql -u root -p
mysql> GRANT ALL PRIVILEGES ON . TO ‘root’@’%’ IDENTIFIED BY ‘cluster’ WITH GRANT OPTION;
mysql> FLUSH PRIVILEGES;
5.9. 创建MySQL数据库
MySQL中root账户执行:
create database hive DEFAULT CHARSET utf8 COLLATE utf8_general_ci;
create database amon DEFAULT CHARSET utf8 COLLATE utf8_general_ci;
create database oozie DEFAULT CHARSET utf8 COLLATE utf8_general_ci;
5.10. 安装Cloudera Manager Server和Agent
(1) 在node1执行
把cloudera-manager-centos7-cm5.7.2_x86_64.tar.gz的压缩包解压到/opt下面
(2)在node1执行
把mysql-connector-java-5.1.43-bin.jar复制到/opt/cm-5.7.2/share/cmf/lib/ 里面
(3)在node1执行
在主节点初始化CM5的数据库:
/opt/cm-5.7.2/share/cmf/schema/scm_prepare_database.sh
mysql cm -h[mysql数据库的主机名] -uroot -p[password] —scm-host [cm server的主机名] [cm的数据库] [cm数据库访问用户] [cm数据库访问用户的密码]
执行/opt/cm-5.7.2/share/cmf/schema/scm_prepare_database.sh mysql cm -hlocalhost -uroot -pcluster —scm-host localhost scm scm scm
(4)在node1执行
Agent配置
修改 vi /opt/cm-5.7.2/etc/cloudera-scm-agent/config.ini 这里面的server_host,改成自身的机器名node1,也就是指名主节点的机器名
(5)在node1执行
将cm-5.7.2的目录复制到其他机器上,同步Agent到其他节点
确保复制到所有的机器上
scp -r /opt/cm-5.7.2 root@node2:/opt/
scp -r /opt/cm-5.7.2 root@node3:/opt/
(6)在所有机器上
在所有节点创建cloudera-scm用户
执行
useradd —system —home=/opt/cm-5.7.2/run/cloudera-scm-server/ —no-create-home —shell=/bin/false —comment “Cloudera SCM User” cloudera-scm
(7)在node1执行
执行 mkdir -p /opt/cloudera/parcel-repo/
(8)在node1执行
把
CDH-5.7.2-1.cdh5.7.2.p0.18-el7.parcel,
CDH-5.7.2-1.cdh5.7.2.p0.18-el7.parcel.sha,
manifest.json
这三个文件,复制到/opt/cloudera/parcel-repo/这里面
(9)在node1执行
ssh node2
mkdir /usr/share/java
把mysql-connector-java-5.1.43-bin.jar复制到/usr/share/java下,并命名为mysql-connector-java.jar
cp /opt/cm-5.7.2/share/cmf/lib/ mysql-connector-java-5.1.43-bin.jar /usr/share/java/ mysql-connector-java.jar
其中machine2是第二台机器,把这个machine2改成其他机器的名字,分别执行一遍
(10)在node1执行
执行启动服务端:
/opt/cm-5.7.2/etc/init.d/cloudera-scm-server start
执行启动Agent服务端:
/opt/cm-5.7.2/etc/init.d/cloudera-scm-agent start
启动其他机器的Agent
执行:
ssh node2
/opt/cm-5.7.2/etc/init.d/cloudera-scm-agent start
ssh node3
/opt/cm-5.7.2/etc/init.d/cloudera-scm-agent start
用这个ssh命令将其他所有机器的agent都启动
问题:在启动时出错
/opt/cm-5.7.0/etc/init.d/cloudera-scm-server start
/opt/cm-5.7.0/etc/init.d/cloudera-scm-server: line 109: pstree: command not found
解决方案:因为系统是最小化安装,默认没有安装,运行下面的命令。
yum -y install psmisc
5.11. 打开网页配置
(1)打开浏览器,地址是:主节点的ip:7180,用户名和密码都是admin
(2)选第一个免费版!
(3)http://www.cnblogs.com/jasondan/p/4011153.html,
然后按照那个博客里面的图片安装就行了
(4)安装服务的时候,错开机器,别把所有的服务都堆在前几台机器上,zookeeper要3个,安装的时候hive会报错,博客里面写了怎么解决,oozie也会报错,都是一样的解决方法,最好默认不要修改。
(5)按照博客可以完成CDH集群的安装
(6)问题: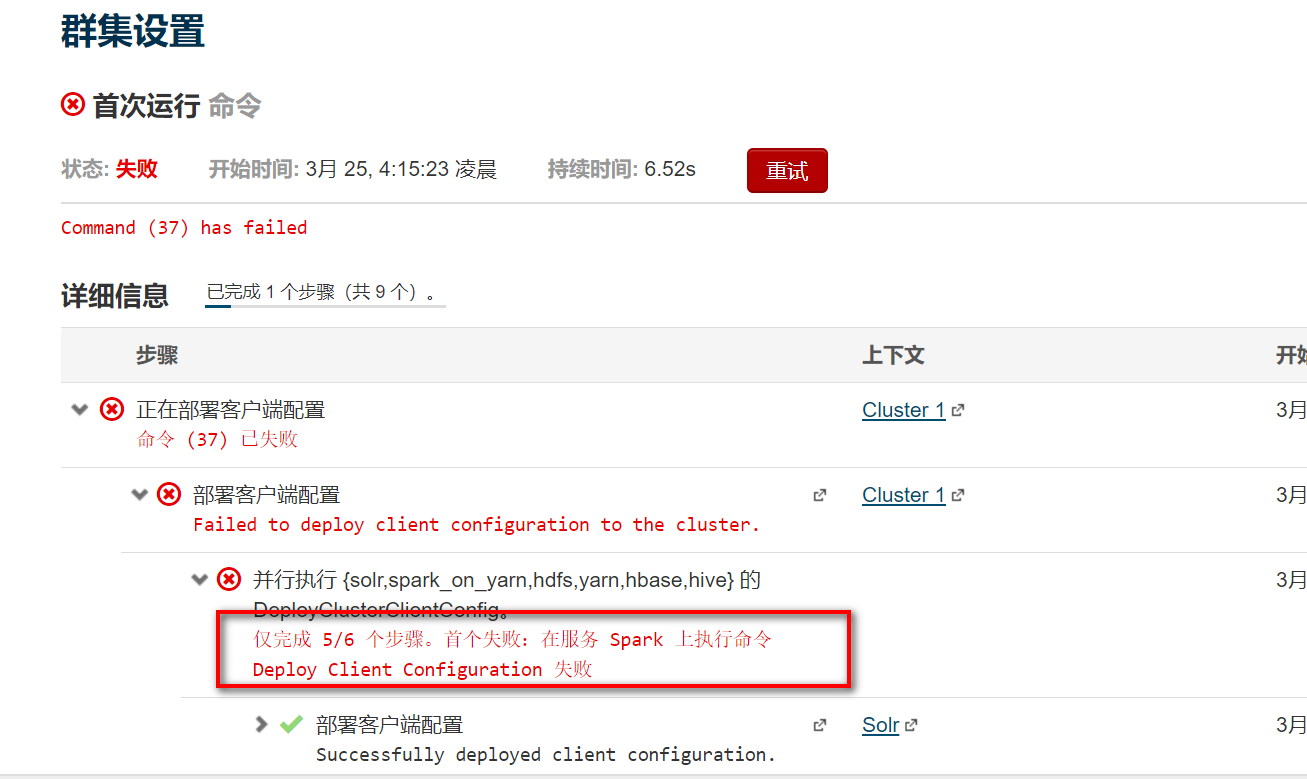
解决方案:这里需要强调一下CDH5默认识别的jdk路径为:/usr/java/default
没有往/usr/java中添加软链接,而这里默认是去/usr/java/default中找环境变量,才会报找不到java_home。安装jdk的方法:把jdk软连接到/usr/java/default首先查看是否有/usr/java目录,没有的话新建此目录:mkdir /usr/java。然后添加软连接到/usr/java/default,命令如下: ln -s /opt/java/jdk1.8.0_11 /usr/java/default
问题: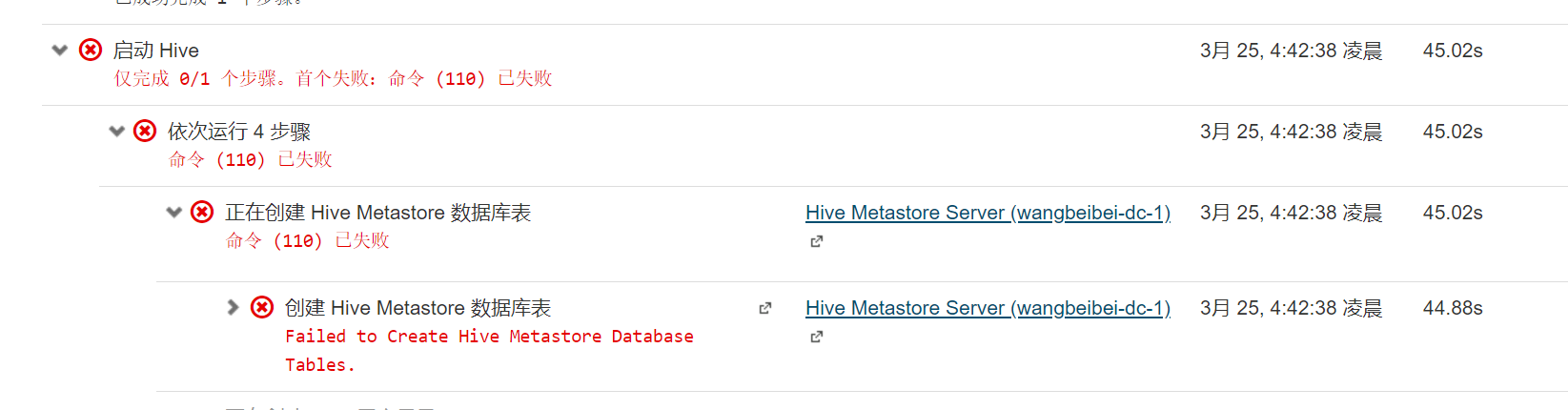
解决方案:这里安装Hive的时候可能会报错,因为我们使用了MySql作为hive的元数据存储,hive默认没有带mysql的驱动,通过以下命令拷贝一个就行了:
cp /opt/cm-5.7.2/share/cmf/lib/mysql-connector-java-5.1.43-bin.jar /opt/cloudera/parcels/CDH-5.7.2-1.cdh5.7.2.p0.18/lib/hive/lib/
5.12. HDFS的HA安装
HDFS HA的安装:
https://www.cloudera.com/documentation/enterprise/5-7-x/topics/cdh_hag_hdfs_ha_enabling.html#cmug_topic_5_12_1,
看里面的Enabling High Availability and Automatic Failover。按操作安装完后,https://www.cloudera.com/documentation/enterprise/5-7-x/topics/cdh_hag_hdfs_ha_cdh_components_config.html#concept_rj1_hsq_bp,
完成里面的Upgrading the Hive Metastore to Use HDFS HA和Configuring Hue to Work with HDFS HA
问题:Cloudera Manager (重新)部署集群报错:fail to format namenode
解决方案:https://www.jianshu.com/p/1e8b25e63ab9
5.13. 安装Anaconda
首先创建一个file0的目录,在这个目录下面运行下面的命令:
bash Anaconda3-4.1.1-Linux-x86_64.sh
这样Anaconda3就安装在file0下面。
https://blog.csdn.net/m0_37548423/article/details/81173678
在所有机器上安装anaconda4.2.0,结尾最后一步,是否添加至环境变量,选择no
使用which python查看使用的是哪个版本的python,运行程序的时候要用
/file0/anaconda3/bin/python user.py
5.14. 安装Spark(standalone)
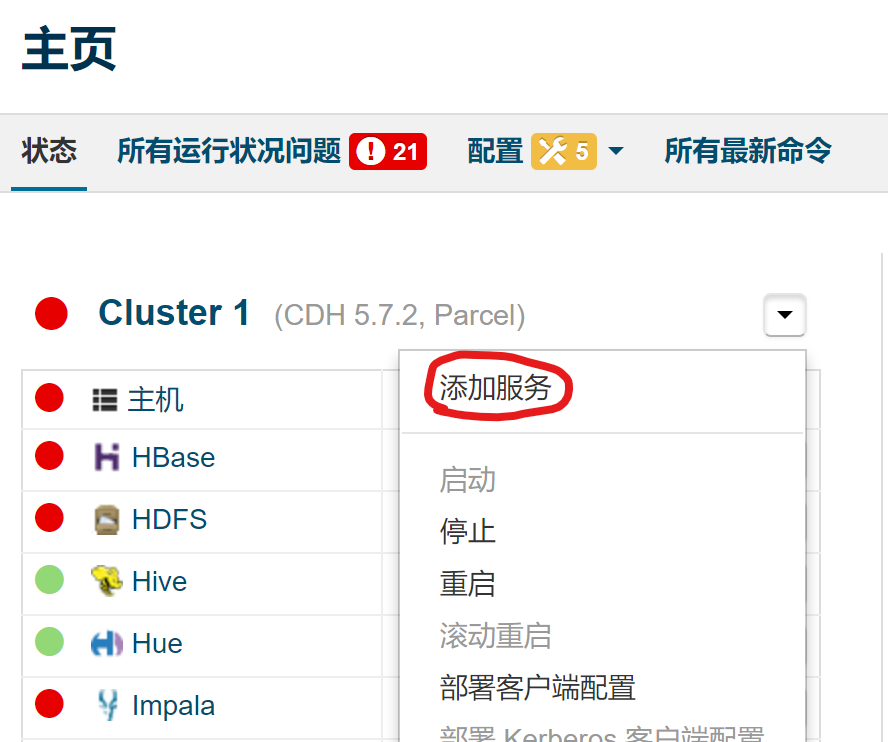
(1)选择这个添加服务,安装Spark (standalone)
(2)点击spark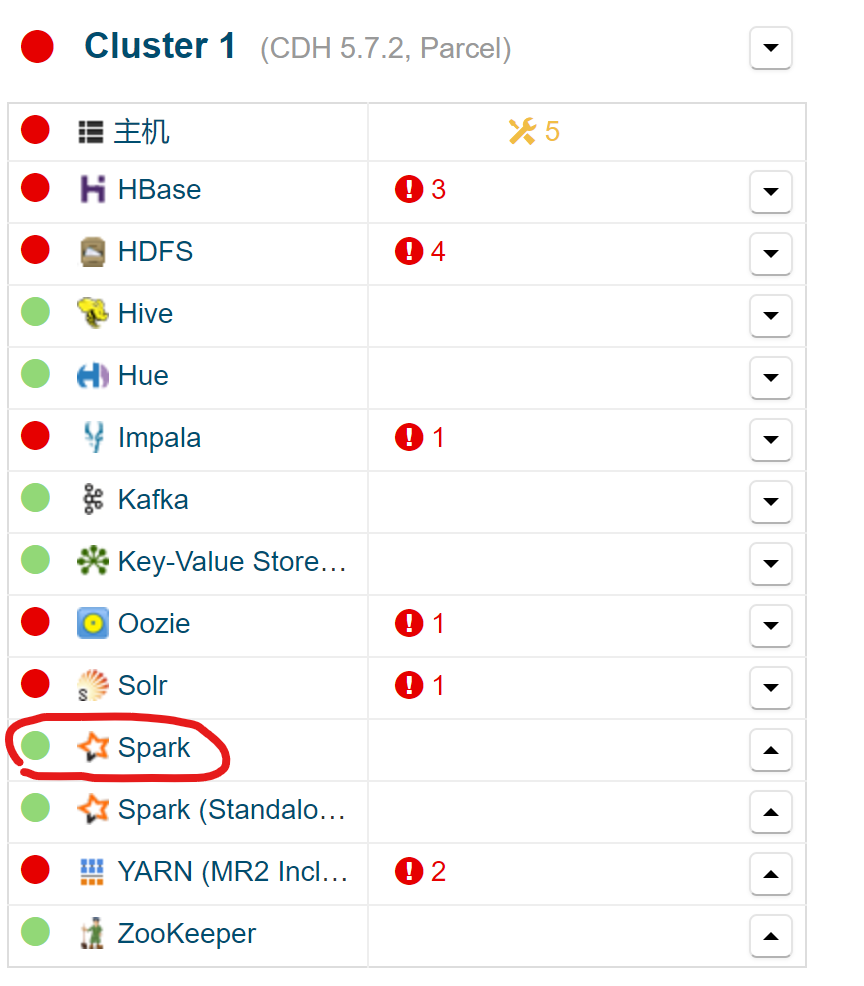
(3)点击配置
(4)搜索栏输入spark-env.sh
export PYSPARK_PYTHON=/file0/anaconda3/bin/python
export PYSPARK_DRIVER_PYTHON=/file0/anaconda3/bin/ipython
export PYTHONHASHSEED=0
找到这个服务高级配置的代码段,改成这个样子,把python的路径指名为anaconda的python路径
(5)按照上一步把 Spark (standalone) 的spark-env也改成上面的样子
5.15. 修改hdfs权限
主节点执行:
sudo -u hdfs hdfs dfs -mkdir /user/root
sudo -u hdfs hdfs dfs -chown root /user/root
sudo -u hdfs hdfs dfs -chmod -R 777 /user
5.16. 安装python三方库
主节点执行:
/file0/anaconda3/bin/pip install
—index-url=file:///file0/CDH_deployment/pypi/simple pymysql happybase pykafka
5.17. 安装kafka
Kafka的安装过程参照:
https://jingyan.baidu.com/article/e9fb46e139dead7521f7662e.html
里面要求下载的四个文件我已经下载好了,其中一个叫manifest.json的文件,我重命名为了manifest_kafka.json,这个重命名是因为防止和之前的那个manifest冲突,直接按照第18步,将两个kafka的parcel文件和这个manifest拷到那个目录里面就行,按照博客里面的要求安装即可。
注意:只设置kafka broker,不设置Kafka MirrorMaker
安装的时候会配置kafka,配置完后会启动kafka,kafka一定启动不了,右下角有个重试按钮,这时候需要再开一个管理界面,像上面配置spark一样,配置kafka,如下图 
分别点进三个超链接,选择左上角的配置,针对每个broker进行配置。
需要配置的是两项:
- Broker ID:可以机器顺序分别改成1,2,3
- Java Heap Size of Broker:改成1G
然后回到刚才安装的那个界面,点击重试。
5.18. yarn
CDH 5.9 以前的版本,如果使用 python3 且使用 yarn 作为master,需手动修复CDH 集群的bug。CDH 5.9 以前的版本在使用 yarn 作为 spark master 的时候,如果使用 python3,会出现 yarn 內部 topology.py 这个文件引发的 bug。这个文件是 python2 的语法,我们使用 python3 运行任务的时候,python3 的解释器在处理这个文件时会出错。
解决方案是:将这个文件重写为 python3 的版本,每次在重启 yarn 之后,将这个文件复制到所有机器
的 /etc/hadoop/conf.cloudera.yarn/ 目录下。
以下操作在所有机器上都要操作,并使用root用户,不可以使用普通用户。如果/etc/hadoop/conf.cloudera.yarn目录不存在,先创建一个同名目录,然后将topology.py复制到该目录下。

