Netflix是一家提供在线视频流媒体服务和DVD租赁业务的公司,用户只需要每月支付8,9美元,就可以无限制的观赏视频、电影和电视。
2006年,Netflix大奖赛开始,Netflix拿出100万美元让开发者为他们优化电影推荐算法。
个性化推荐是Netflix最先开始的,他们从最开始就十分重视数据,开始收集用户数据,他们会在邮寄的信封里附上问卷让用户对电影评分,这些打分是Netflix推荐系统的重要基石之一。
2012年,Netflix的推荐系统经历一次重大的策略变化,官方技术博客(下面2篇)阐述了这种变化的前因后果。
在邮寄租赁DVD的时代,Netflix能够获得用户的评分,但是用户观看电影的过程对平台是隐形的。但是随着流媒体业务的开展,Netflix终于有机会看到用户的更多方面,于是他们认识到:一切都是推荐。
转型流媒体后,用户的所有行为全部在平台内完成,Netflix可以通过平台观察用户,可以知道用户看过什么电影,什么时候看的,看了多长时间,这些行为都可以体现用户的喜好。通过分析这些数据,让Netflix的推荐系统更准确。
Netflix的牛人Xavier Amatriain写的介绍Netflix推荐系统的一篇博客
原文链接:
Netflix Recommendations: Beyond the 5 stars (Part 1)
Netflix Recommendations: Beyond the 5 stars (Part 2)
在这2篇博客中,我们将介绍Netflix最重要资产:推荐系统。
- 1. Netflix Recommendations: Beyond the 5 stars (Part 1)
- 2. Netflix Recommendations: Beyond the 5 stars (Part 2)
1. Netflix Recommendations: Beyond the 5 stars (Part 1)
1.1. Netflix大赛和推荐问题
在2006年,我们发起Netflix大赛,是一个电影评分预测的比赛,我们提供1百万奖金给评价指标提升10%的团队。推荐算法是Netflix的关键,我们使用RMSE作为评价指标,我们的系统RMSE=0.9525,获胜的团队需要降低到0.8572或更低。
第一年,Korbell团队以8.43%的提升获得了大奖,他们融合了107种算法,并把源代码提供给我们,我们发现其中2种最有效的方法:矩阵分解(SVD)和受限玻尔兹曼机(RBM)。为了将这两种方法用到实际中,我们需要克服一些限制,比如他们的算法是基于一亿评分,但我们实际上有50亿评分,并且他们没考虑用户不断产生新评分的情况。最终我们克服了这个挑战,将这2个算法用在实际中,现在仍作为我们推荐系统的一部分。
1.2. 从DVD到流媒体
在推荐算法中,我们的关注点发生转换的一个原因是Netflix在2007年发布了流媒体服务,流媒体服务不仅改变了用户与系统的交互方式,也改变了推荐算法的数据来源。对DVD租赁,我们的目标是帮助用户找到电影,并在接下来的几天或几周中发到他们邮箱,从选择到观看到反馈的时间比较长。然而对于流媒体服务,用户选好一部电影之后就可以马上观看,甚至可以在短时间观看多部电影,同时,我们也直到用户是否完整观看了电影还是只看了一部分。
另一个巨大的变化是网站从单纯的web端扩展到成百上千的不同设备。
下面我们将介绍我们使用的推荐算法。
1.3. 一切都是推荐
我们发现尽可能的集成个性化推荐对我们的订阅者产生巨大的价值。我们主页上有个性化推荐,每一行有个主题,主题揭示了这行视频的内在联系,大多数的个性化都是基于挑选行视频的方法,包括哪些行该放哪些视频,以及如何对视频排序。
以前10行为例,这是我们猜测你最可能喜欢的10个主题,这里的“你”指的是你和家人。Netflix的个性化推荐需要解决一个家庭中可能有不同的人,有不同的喜好。这也是为什么当你看到top10,可能会发现有针对爸爸,妈妈,小孩的推荐,即使只有一个人的家庭,我们也要兼顾这个用户不同的兴趣和情绪。正因为如此,我们的系统不仅仅追求准确性,还要保证多样性。

Netflix个性化系统的另一个重要元素是awareness。我们想让用户直到我们是怎么掌握他们的喜好的。这不仅能使用户信任我们的系统,而且鼓励用户提交更多的反馈来帮助我们更好的推荐。提升用户信任度的一个方式是向用户说明为什么给他推荐这个电影,并不是满足我们的商业需求,而是基于用户的评分,观看记录,朋友的推荐等。
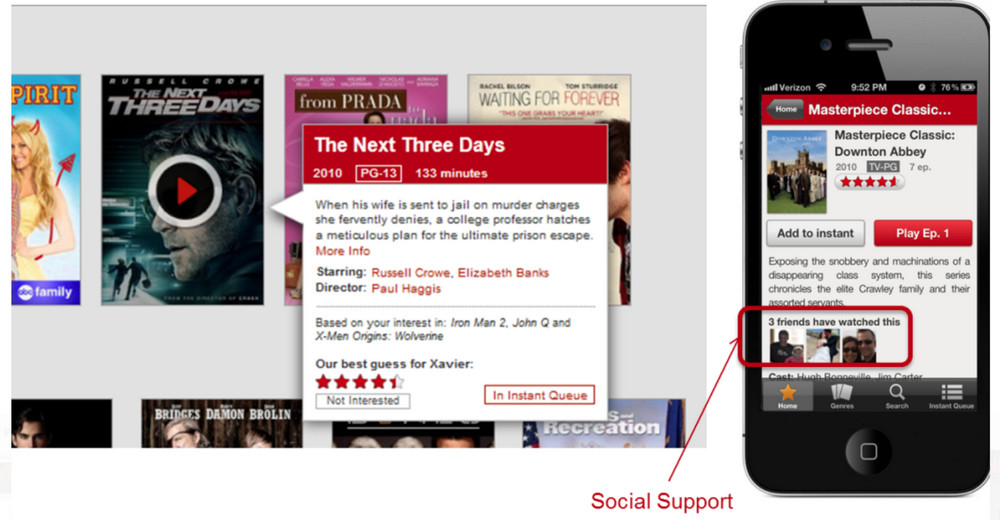
我们的推荐系统中还有以“风格”为主题的几行推荐结果,每一行都需要考虑三方面:选择哪些风格,这个风格中选择哪些视频,这些视频如何排序。我们发现当把长尾的类别放在前面时,用户停留的时间增加了。个性化系统的另一个元素是:freshness新颖性
相似性在个性化系统中是非常重要的。相似性可以是用户之间,或电影之间,也可以是多维数据,例如元数据,评分,观看历史。基于相似性推荐用在多种场景之中,例如当用户搜索一个电影时或把一个电影放在观看列表中时,也可以用来生成动态风格的推荐结果。
个性化推荐最重要是排序,决定一行中电影排放的顺序。我们排序系统的目标是在一定的上下文中,为用户实时找到物品尽可能好的排序。我们将排序分解为:打分、排序、过滤,将用户最可能喜欢的电影尽可能打高分,排在前面。
2. Netflix Recommendations: Beyond the 5 stars (Part 2)
这一节我们将介绍推荐系统的技术细节,我们将讨论当前的模型,数据以及方法。
2.1. 排序
推荐系统的目标是为用户展示他可能喜欢的商品。通常是选择一些商品,然后对它们进行排序。
最简单的排序是根据热门程度,根据热门进行推荐,用户总是倾向于购买大家都喜欢的物品,但是热门推荐是个性化推荐的反义词,为用户生成千篇一律的推荐结果,我们的推荐还要考虑到新颖性、用户兴趣、多样性等。
排序的目标是为用户推荐他最可能喜欢的物品,最自然的方法是使用用户
对物品的评分表示物品的受欢迎程度。这样会导致可能会推荐一些那些评分高的小众电影,但用户可能更想看的是评分不高但更大众的电影。为了解决这个问题,最好的做法是兼顾视频的热门程度和用户的期望评分。
其中$u$表示用户,$v$表示物品,$p$表示热门函数,$r$表示期望评分。等式可以定义为2维空间,如下所示:
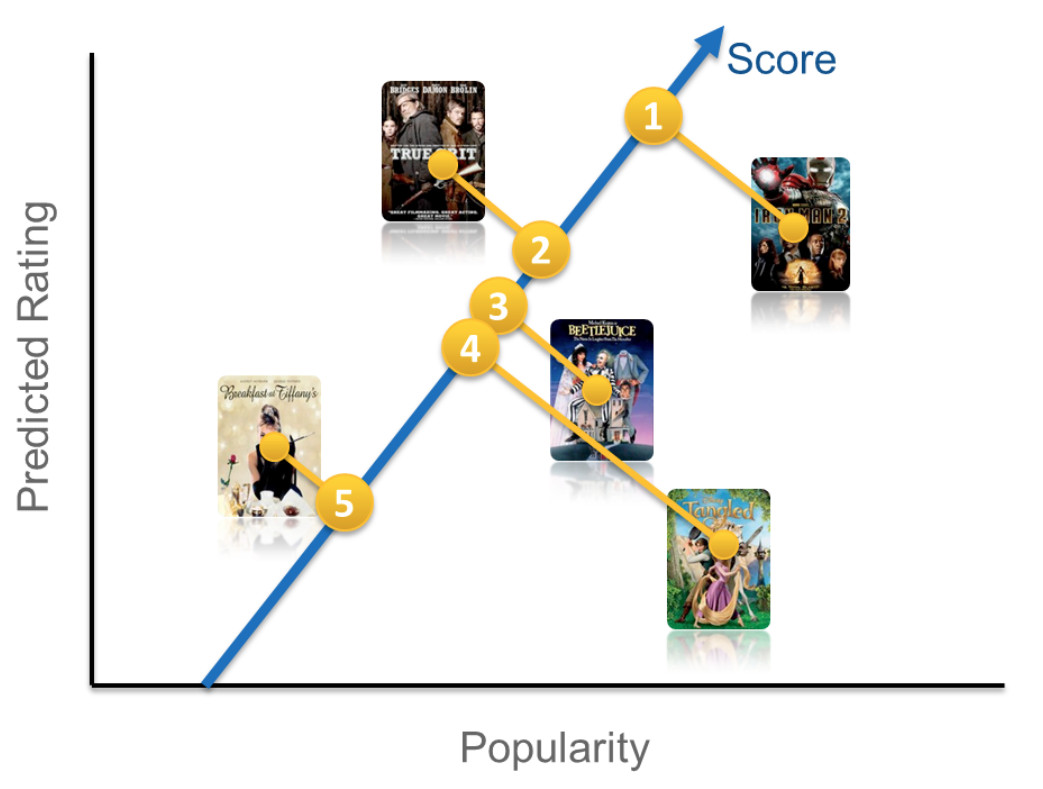
通过上述等式,我们可以得到一个评分,将评分降序排序,对用户进行推荐。其中$b$是偏差,是定值,不影响最终的排序结果。其中$w_1$和$w_2$用来决定在排序函数中,热门程度更重要,还是用户期望评分更重要。有2种方案来解决。你可以对$w_1$和$w_2$选一些候选值,放到线上A/B测试,让用户决定哪个更好。但是这种方法耗时。另一个方法是使用机器学习的方法,从历史数据中选择一些正样本和负样本,设计一个目标函数,让机器学习算法去学习这2个参数。
很多有监督分类方法可以用来排序。一般的选择有逻辑回归,SVM,GBDT。另一方面,现在也出现一些算法专门用来排序,例如RankSVM,RankBoost。对于一个排序问题,找到效果最好的算法并不容易。通常你的特征越简单,模型就越简单。但是,有时候一个特征不起作用,可能是选的模型不够好。或者一个很好的模型在系统中表现不好,可能是你用的特征和模型不匹配。
2.2. 数据和模型
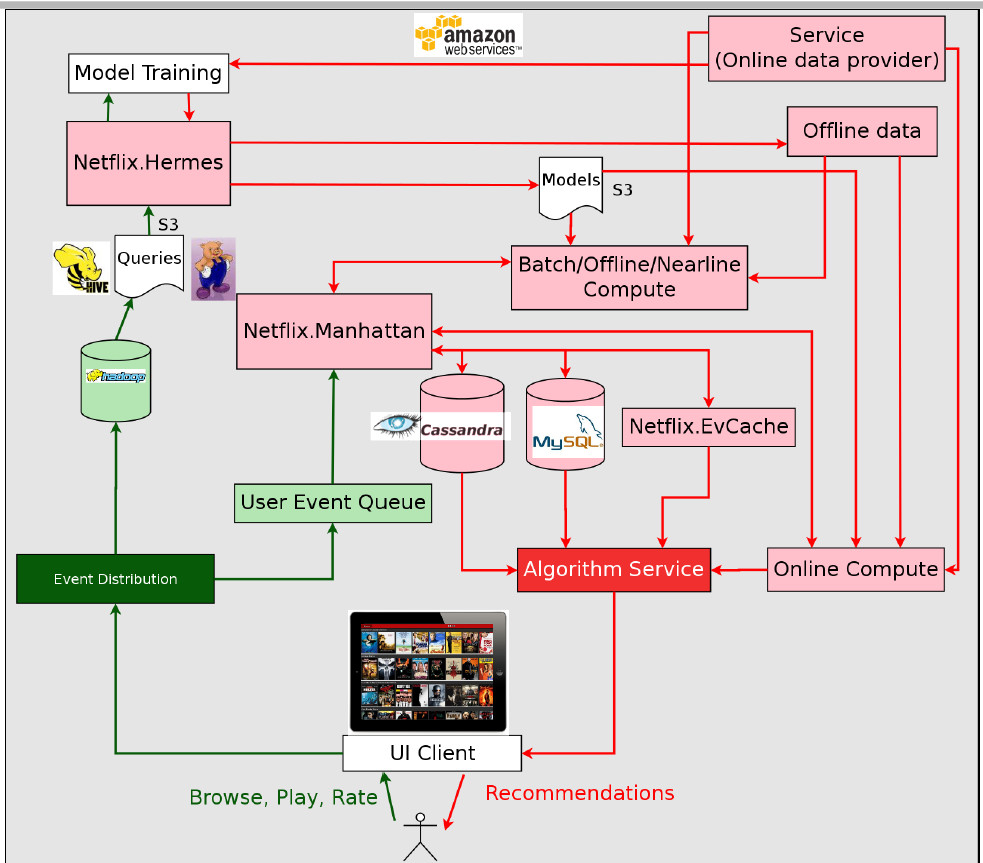
下面是Netflix推荐系统中可以用到的数据:
- 我们有几十亿的用户评分数据,并且每天几百万的规模在增长
- 我们以视频热度作为算法基准,但是我们可以用多种方式计算视频的热度。可以在不同的时间段内进行统计,例如最近一个小时、一天或者一周。可以将用户按照地域划分,计算视频在某部分用户的热度。
- 我们的视频每天有几百万的播放,包括上下问信息,例如看了多久,什么时候开始看,播放设备类型等
- 我们的会员每天添加几百万的视频到他们的播放列表中
- 每个视频有不同的属性,演员、导演、类别、评分
- 视频展现方式:我们知道推荐的视频什么时候,什么地方展示给用户,也可以看到这些因素如何影响用户的选择,也可以看到用户与系统交互的细节,比如滚动鼠标、点击等
- 社交数据已经成为我们的数据来源,我们知道用户的好友在看什么视频
- 用户每天进行几百万的搜索请求
- 外部数据:电影票房、影评家的评论
- 以上并不是全部数据,还有人口普查、位置、语言等数据
有这么多高质量的数据,单一的模型是不够的,我们必须做模型选择,训练和测试。我们用了很多机器学习算法
- 线性回归
- 逻辑回归
- 弹性网络
- SVD
- 受限玻尔兹曼机RBM
- 马尔科夫链
- LDA
- 关联规则
- GBDT
- 随机森林
- 聚类方法
- 矩阵分解
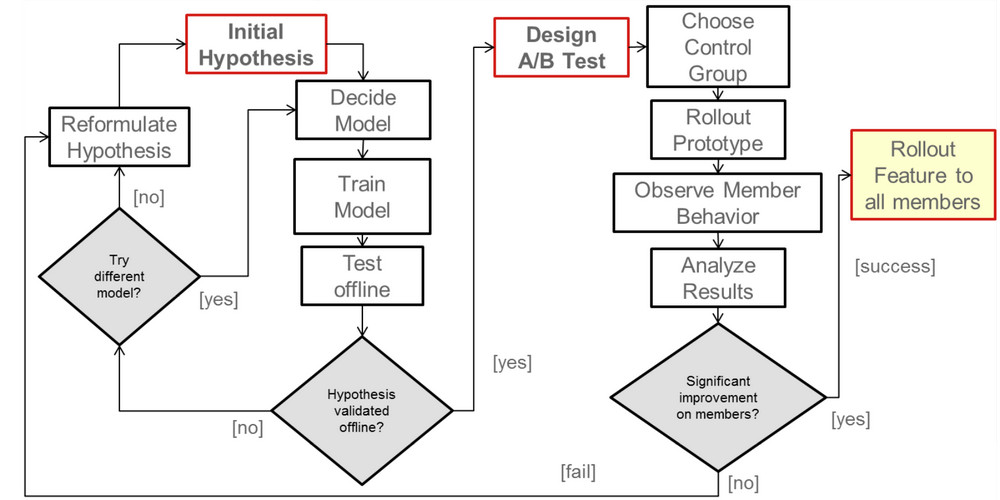
在实际工作中,我们通过线上A/B测试来验证方法的有效性
- 提出假设
- 待检测的算法/特征能够帮助提升视频播放时长,并且提升用户停留时间
- 设计实验
- 开发解决方案或原型系统
- 思考系统依赖和不依赖的变量
- 进行测试
- 让数据说话
当我们做了A/B测试时,有很多指标。最信任的还是视频播放时长和用户停留时间
一个有趣的问题是我们怎么整合我们的机器学习方法到A/B测试中,我们现在是做离线测试和在线。离线测试用在在线测试之前,用来测试和优化我们的算法。为了评估系统的离线系统,我们有很多指标,例如排序指标NDCG,MRR,分类指标accuracy/precision/recall/F1,回归指标RMSE等。我们跟踪这些离线指标和线上效果的吻合程度,发现他们趋势并不是完全一致,因此线下指标只能作为最终决定的参考。
一旦离线测试验证了假设,我们就准备做A/B测试,通过用户的反馈做进一步的验证。如果成功了,我们将加入到主要系统中,为所有用户服务。