今天看到今日头条的推荐算法原理介绍,非常感兴趣,在此记录下。
1. 推荐系统概述
推荐系统就是需要去拟合一个用户对内容满意度的函数,这个函数需要输入三个维度的变量:
- 内容维度。头条中有图片,视频,新闻等信息,每种内容都有自己的特征。
- 用户特征。包括用户的兴趣标签,职业,年龄,性别等,还有很多表示用户喜好的隐式特征
- 环境特征。用户随时随地移动,在工作场合,通勤,旅游三个不同的环境中,喜好会发生偏移。
结合以上三个维度,模型会给出一个预估,在这个场景下用户对这个内容是否感兴趣。
2. 评价指标
推荐模型中,点击率,阅读时间,点赞(离散指标),评论等都是可以量化的目标,能够用模型进行预测。但当用户过多时,不能完全由指标进行评估,引入数据指标以外的要素也很重要。
3. 典型推荐算法
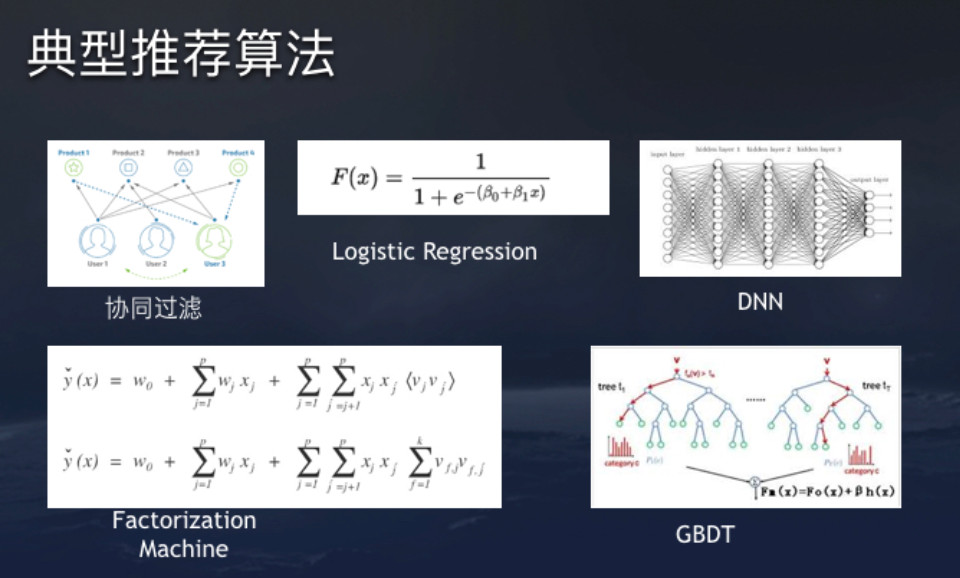
4. 典型的推荐特征
看完典型推荐模型,我们再看看典型的推荐模型中用到的特征,主要有4类特征。

- 相关性特征。就是评估内容的属性和用户是否匹配。显性的匹配包括关键词匹配、来源匹配、分类匹配、主题匹配等。向FM模型中也有一些隐式匹配,从用户向量和物品向量的距离得出。
- 环境特征。地理位置和时间
- 热度特征。包括全局热度,分类热度,主题热度,以及关键词热度。其中内容热度信息在推荐系统冷启动问题非常有效。
- 协同特征。可以在部分程度上帮助解决算法越推越窄的问题。协同过滤并非考虑用户已有的历史,而是通过用户行为分析不同用户间的相似性,比如点击相似性,兴趣分类相似等,从而扩展模型的探索能力
5. 大规模模型训练
头条大部分推荐产品采用实时训练。实时训练省资源并且反馈快。用户的行为信息可以被模型快速捕捉并反馈给下一刷的推荐结果。头条线上目前基于storm集群实时处理样本数据,包括点击收藏等动作。
整体的训练过程是线上服务器记录实时特征,导入到kafka文件队列中,然后进一步导入storm集群消费kafka数据,客户端回传推荐的label构造训练样本,随后根据最新样本进行在线训练更新模型参数,最终线上模型得到更新。这个过程主要的延迟在用户的动作反馈延时,因为文章推荐后用户不一定马上看,不考虑这部分时间,整个系统几乎是实时的。
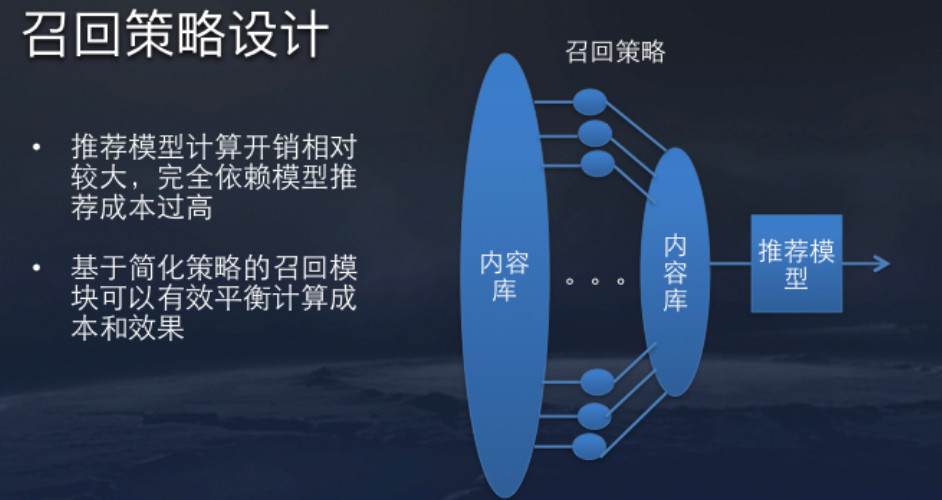
头条的内容量非常大,推荐系统不可能所有的内容全部由模型预测,所以需要设计一些召回策略,每次推荐时从海量内容中筛选出千级别的内容库。召回策略最重要的要求是性能要极致,一般超时不能超过50毫秒。
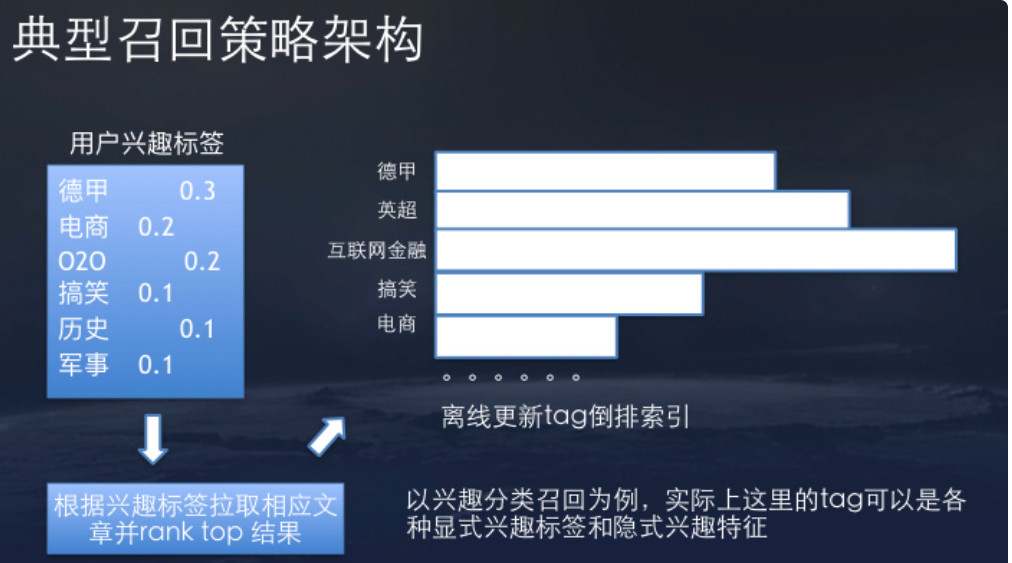
召回策略有很多,头条采用的是倒排的思想。离线维护一个倒排,根据用户标签或topic,来源等,拉去对应的文章并对其排序。线上召回可以迅速的从倒排中根据用户兴趣标签对内容做截断,高效的从很大的内容库中筛选比较靠谱的一小部分内容。
6. 内容分析
内容分析包括文本分析、图片分析和视频分析。这里主要将文本分析,文本分析在推荐系统中很重要的作用是用户兴趣建模。没有内容和文本标签,无法得知用户兴趣标签。举个例子,只有知道文档标签是互联网,用户看了互联网标签的文章,才能知道用户有互联网标签。所以内容分析和用户标签是推荐系统的基石。
下面是今日头条一个实际文本的例子,可以看到这篇文章有分类,关键词,topic等文本特征。
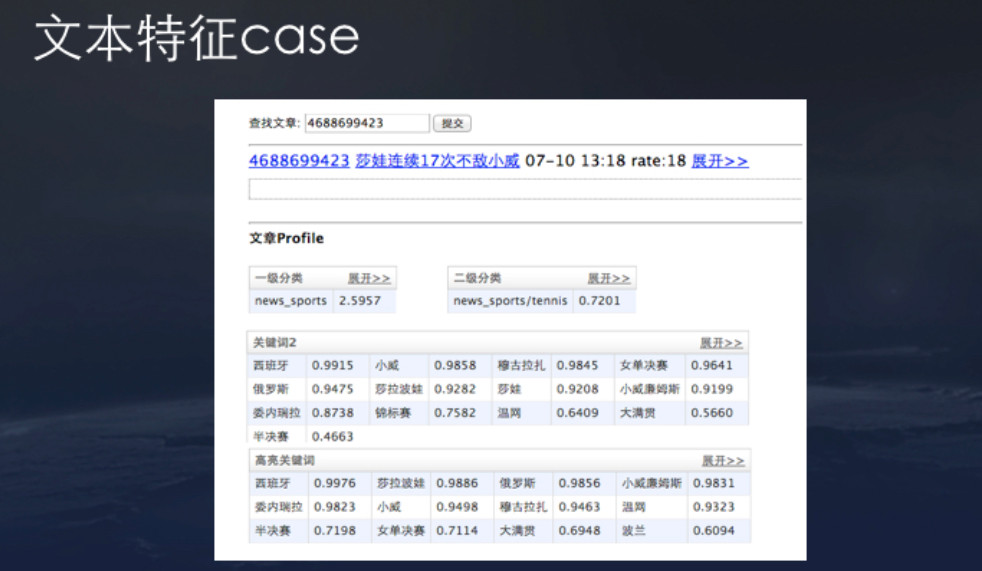
今日头条推荐系统文本的特征主要有以下几类:
- 语义标签类特征:显示为文章打上语义标签。这部分标签是人定义的特征,每个标签有明确的意义,标签体系是预定义的。
- topic特征和关键词特征:隐式语义特征。其中topic特征描述词概率分布,无明确意义;关键词特征会基于一些统一的特征描述,无明确集合。
下面是头条语义标签的特征和使用场景。他们之间层级不同,要求不同。
分层是为了每个层级粒度不同,要求也有区别。
- 分类:要求覆盖全,希望每篇文章都有分类,精确性要求不高。
- 概念:表达比较精确,但又属于抽象概念的语义,也不要求覆盖全。
- 实体:不要求覆盖全,只要覆盖每个领域热门的人物、机构、作品即可。

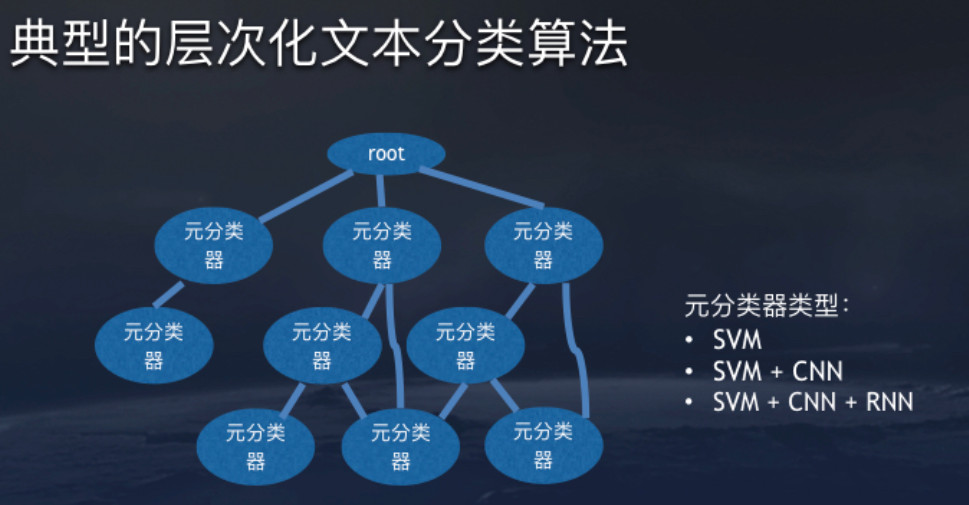
头条线上分类采用层次分类。最上面是root,下面第一层的分类像科技,体育,娱乐这样的大类,下面细分足球,篮球,网球等,足球再细分国际足球,中国足球,中国足球又分为中甲,中超,国家队等。相比单独的分类器,利用层次文本分类算法能更好地解决数据倾斜问题。
每个元分类器可以异构,像有些分类器SVM效果很好,有些要结合CNN,有些要结合RNN
7. 用户标签
用户分析和用户标签是推荐系统的两大基石。内容分析涉及到的机器学习多一些,相比而言,用户标签工程挑战更大。
用户标签包括:
用户感兴趣的类别和主题、关键词、来源。基于兴趣的用户聚类和各种垂直兴趣特征
性别、年龄、地点等信息。性别信息通过用户第三方社交账号登录得到。年龄信息通常由模型预测,通过机型、阅读时间分布预估。常驻地来自用户授权访问位置信息,在位置信息的基础上通过传统聚类方法拿到常驻点,常驻点结合其他信息,可以推断用户的工作地点、出差地点、旅游地点。这些用户标签非常有助于推荐。

最简单的用户标签是浏览过的内容标签,但这里涉及到一些数据处理的策略。主要包括:
- 过滤噪声。通过停留时间短的点击,过滤标题党。
- 热点惩罚。对用户在一些热门文章上的动作做降权处理。理论上,传播范围较大的内容,置信度会下降。
- 时间衰减。用户兴趣会发生偏移,因此策略更偏向新的用户行为。因此,随着用户动作的增加,老的特征权重会随时间衰减,新动作贡献的权重会更大。
- 惩罚展现。如果一篇推荐给用户的文章没有被点击,相关特征(类别、关键词、来源)权重会被惩罚。

用户标签总体相对简单,主要还是工程上的挑战。头条用户标签第一版是批量计算框架,流程比较简单,每天抽取昨天的日活用户过去两个月的动作数据,在Hadoop集群上批量计算结果。
但随着用户增加,兴趣模型种类和其他批量处理任务都在增加,计算量太大,集群计算资源紧张,集中写入分布式存储系统的压力也开始增大,用户兴趣标签更新延迟越来越高。

2014年,头条上线了用户标签storm集群流式计算系统,只要有用户动作更新,就更新标签,CPU代价较小,大大降低了计算资源开销,特征更新速度也很快

8. 评估分析
介绍了推荐系统的整体架构,怎么评估推荐效果好不好呢?
全面的评估推荐系统,需要完备的评估体系,并非单一的指标,不能只看点击率和停留时长,需要综合评估。

一个良好的评估体系需要遵循几个原则,首先是兼顾短期和长期指标,检录用户指标和生态指标。今日头条作为内容创作平台,既要为内容创作者提供价值,也有义务满足用户,这两者要平衡。还有广告主利益也要考虑,这是多方博弈和平衡的过程。


