该论文发表于2005年IEEE TKDE,是推荐系统经典的综述论文。该论文主要对当时的技术进行总结。
1. 引言
推荐系统可以帮助用户处理信息过载,提供个性化的推荐服务。
在下面的章节中,作者首先对当前的推荐算法进行总结,并列出他们的limitation。
2. 推荐算法综述
推荐系统问题通常被定义为对用户未看到的东西进行排序。直观上,通常是基于用户对其他物品的评价或额外信息,来对这些未见过的东西进行排序,根据排序结果,我们就可以将排在前面的东西推荐给用户。
推荐系统的形式化定义:$C$表示用户集合,$S$表示被推荐的物品集合,集合$C,S$中元素个数可能会非常多。我们要学习一个效益函数$u$,$u:X \times S \rArr R$,$R$是有序集合,对于用户$c \in C$,我们想选出物品$s’ \in S$,使得用户的效益最大
在推荐系统中,一个物品的效益通常用排名表示,表示这个用户喜欢这个物品的程度。
对于每个用户,可以使用年龄,性别,收入,婚姻状态等特征表描述用户,最简单的情况,可以仅适用用户ID来表示用户特征。类似,一个物品可以使用一些特征来描述。例如电影可以使用名字,导演,主演等特征。
推荐系统的中心问题是效益函数$u$通常不是定义在整个$C \times S$集合空间上,而是定义在它们的子集上,这意味着$u$需要外推到整个$C \times S$空间上。
根据推荐的方式,推荐算法被分为以下3类:
- 基于内容的推荐:向用户推荐其以前偏好的物品
- 协同过滤:找和用户有相似喜好的人,向该用户推荐他们喜欢的物品
- 混合推荐:结合基于内容推荐和协同过滤
2.1. 基于内容的推荐
2.1.1. 介绍
$u(c,s)$用户$c$对物品$s$的喜爱程度,基于用户对与$s$相似的物品$s’$的喜爱程度来评估。例如电影推荐系统中,推荐算法会找出用户$c$以前看过的电影,对其评分高的那些电影间的共性(导演,演员,主题等),然后向用户推荐和这些电影相似的电影。
基于内容的推荐源自信息检索和信息过滤的研究。许多基于内容的推荐基本都是基于文本信息的推荐,例如文档,URL,或新闻等。
形式化定义:$Content(s)$表示物品$s$的特征,基于内容的推荐很多都是基于文本的推荐,所以物品的特征基本使用关键词表示。例如网页推荐中,通常推荐包含100个最重要单词的网页给用户。$w_{i,j}$表示单词$k_i$在文档$d_j$中的重要性,最常用的是使用$IT-IDF$来评估。
基于内容的推荐就是推荐与用户以前喜欢的物品相似的物品,因此我们需要评估候选物品和以前物品的相似性,然后推荐最匹配的物品给用户。
形式化定义:$ContentBasedProfile(c)$表示用户$c$过去的喜好,例如可以用关键词的权重来表示$ContentBasedProfile(c)=(w_{c1,,…,w_{ck}})$,$w_{ci}$表示关键词$k_i$对用户$c$的重要程度。计算用户$c$对物品$s$的喜爱程度为:
在文本信息中,可以分别使用TF-IDF计算词向量权重$\vec{w}_{c},\vec{w}_{s}$,然后计算这2个向量的相似性,使用cos函数:
$K$表示字典中所有的关键词个数
除了使用cos计算相似度,还有一些其他方法,例如贝叶斯分类,深度神经网络也可以用来做基于内容的推荐。
2.1.2. 限制
基于内容的推荐算法依赖于物品的特征,为了有足够的特征,通常使用特征自动或人工提取特征,但是有些领域特征提取困难,例如音频和视频。
另外一个问题是如果2个物品的使用同一组特征表示,则无法区分它们。基于文本的文档通常使用关键字表示,如果这2篇文档恰巧使用了相同的关键字,则无法区分这2个文档写的好坏。
当系统只向用户推荐他以前喜欢的物品时,这个系统就过度专业化,那些用户没看过的物品将永远不会被推荐。为了解决这个问题,系统通常会引入一定的随机性。在推荐的时候通常会推荐和以前物品相似的内容,但是如果2个物品太相似,例如在新闻系统中,用户看了一个新闻,如果有个新闻和这个新闻相似,讲的是同一件事,这时候也不建议推荐。所以在信息过滤的时候不仅要过滤那些和用户喜好完全不同的内容,还要过滤和用户以前看过的内容太相似的东西。
冷启动问题:在推荐之前,用户必须要有对足够多的物品评分,如果一个用户对物品评分较少或者一个新用户,则推荐将会不准确
推荐系统的理想状态是多样性,为用户推荐一系列不同的内容,而不是全是同一系列的内容。
2.2. 协同过滤CF
协同过滤Collaborative Filtering
2.2.1. 介绍
协同过滤是根据与该用户相似用户的喜好物品来进行推荐。
形式化定义:效益函数$u(c,s)$基于$u(c_j,s)$,其中$c_j$表示和用户$c$相似的用户。
协同过滤算法可以分为2类:基于内存的、基于模型的。
2.2.1.1. 基于内存的协同过滤
基于内存的表示用户$c$对物品$s$的喜爱程度$r_{c,s}$基于系统中以前其他用户$c’$对物品$s$的评分$r_{c’,s}$,$c’$通常是与$c$最相似的$N$个用户$\hat{C}$,$r_{c,s}$通常是$r_{c’,s}$的聚合函数。
聚合函数主要有以下几种形式:
$($ a $) r_{c, s}=\frac{1}{N} \sum_{c^{\prime} \in \hat{C}} r_{c^{\prime}, s}$
$(\mathrm{b}) r_{c, s}=k \sum_{c^{\prime} \in \hat{C}} \operatorname{sim}\left(c, c^{\prime}\right) \times \mid r_{c^{\prime}, s}$
$(\mathrm{c}) r_{c, s}=\bar{r}_{c}+k \sum_{c^{\prime} \in \hat{C}} \operatorname{sim}\left(c, c^{\prime}\right) \times\left(r_{c^{\prime}, s}-\bar{r}_{c^{\prime}}\right)$
$\bar{r}_{c}$表示用户$c$的对物品的平均评分。
其中权重聚合(b)最常用。对不同的用户评分赋予不同的权重,最相似的用户的评分权重最大。但是不同的用户在评分的时候量级可能不一样,需要归一化,于是出现了公式(c),每个相似用户的评分需要先减去用户$c$的平均评分。
$sim(c,c’)$表示2个用户的相似性,相似性函数根据情况定义。通常情况下,相似性根据这2个用户对物品的评分来计算。其中最常用的2个相似性函数是皮尔森相关系数和余弦相似度:
皮尔森相关系数
使用$S_{xy}$表示用户$x,y$都评分的物品集合。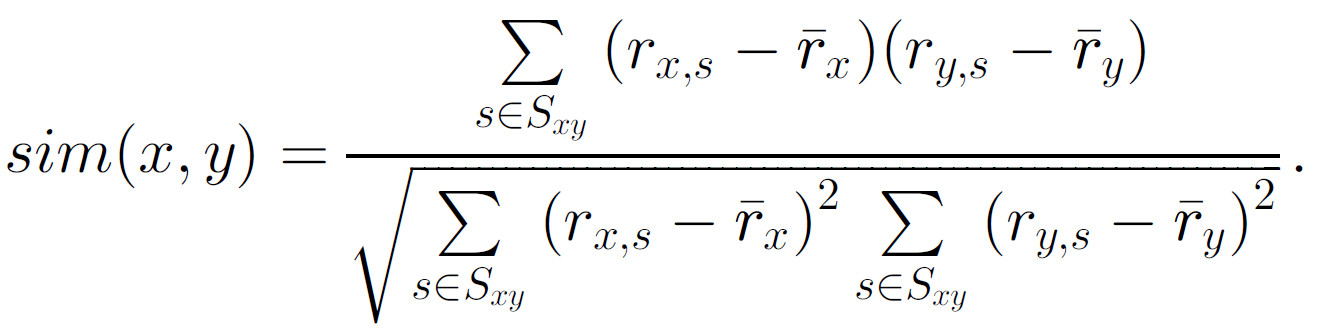
余弦相似度
余弦相似度使用2个m维向量表示2个用户,$m=|S_{xy}|$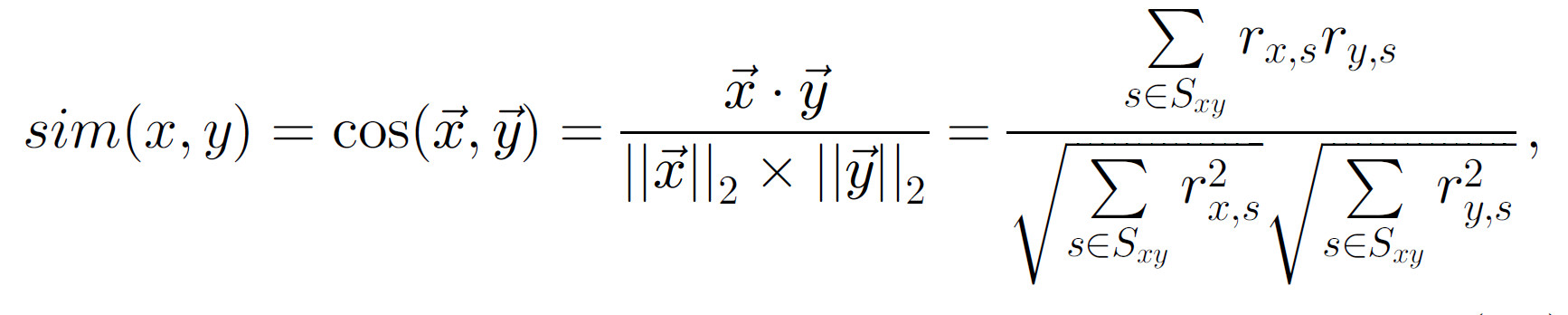
计算相似度的关键是找到2个用户都评价的物品交集
【注意】
基于内容的推荐和协同过滤都使用了cos计算相似性,基于内容的推荐是计算2个物品的关键词TF-IDF权重的相似性,协同过滤计算2个用户对用户的评分的相似性。
2.2.1.2. 基于模型的协同过滤
基于模型的协同过滤就是用收集的打分训练一个模型,然后模型预测出一个排名用于推荐。例如,一篇论文提出使用基于概率的协同过滤,其中打分函数为:
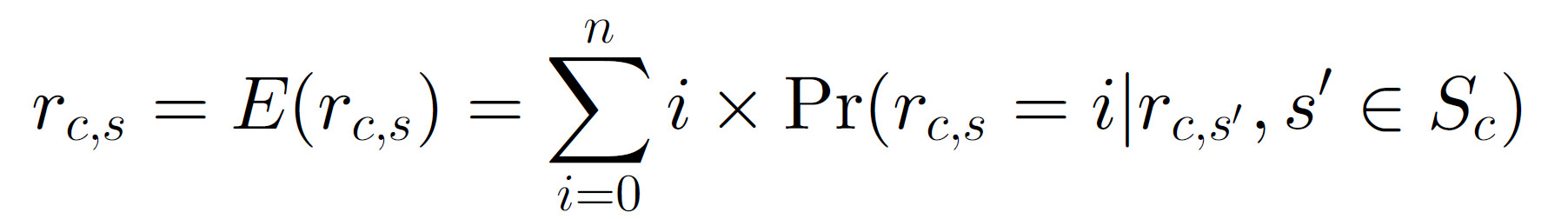
假设打分的数组在0~n之间,概率表达式为:在给定之前给物品打分的情况下,用户$c$对物品$s$打分。有2种概率模型:聚类模型和贝叶斯网络。聚类模型是将兴趣相同的用户放在一类中。如果已经给定每类的用户,并且用户打分是独立的,则就变成朴素贝叶斯网络。每个节点的状态表示每个物品的可能的打分值,网络的结构和条件概率通过数据学到。这个方法的限制是一个用户只能被聚到一类,但实际情况下,一个用户可能同时属于多类,即一个用户可能有多个兴趣。
同时,协同过滤也可以使用机器学习框架,例如LR等。
2.2.2. 限制
协同过滤主要有以下3个问题:
- 新用户问题(冷启动问题)对于一些新用户,没有评分数据,推荐往往不准。现在大部分使用混合推荐方法(基于内容推荐+协同过滤)
- 新物品问题:当系统中增加一些新物品,没有用户针对这个物品打分,通常也使用混合推荐解决
- 数据稀疏问题:用户对物品的打分矩阵是非常稀疏的,有些物品只被很少的用户打分,即使分数很高,这些物品也很少被推荐。解决这个问题的方法是计算用户相似度时,不仅仅使用打分数据,还可以使用用户的画像信息,例如性别,年龄,教育等信息。或者使用SVD进行降维。
2.3. 混合方法
一些推荐系统使用混合方法,结合基于内容的推荐和协同过滤。在这2种方法的结合方式上有以下几种:
- 分别使用这2种方法,然后把他们的预测结果结合在一起
使用线性组合或投票的方式将2个方法的输出结合在一起。 - 把基于内容的一些特征结合到协同过滤中
使用协同过滤进行推荐,但是保留用户画像信息,使用用户信息计算2个用户的相似性,而不是用历史打分来计算相似性。 - 把协同过滤的一些特征结合到基于内容的推荐中
在基于内容的用户画像上进行降维 - 构建一个综合模型,结合基于内容和协同过滤
3. 推荐算法扩展
丰富用户信息
以前的基于内容的推荐和协同过滤是基于用户和物品的画像信息,没有充分利用用户交易记录和其他有价值的信息,在推荐的时候应该使用更先进的用户画像技术。多维度推荐
现在的推荐都是基于用户和物品的,不考虑上下文信息。然而很多时候,用户对某物品的喜爱程度很大程度上和时间有关,也可能取决与和谁一起消费。在这种情况下,仅仅就需要考虑上下文信息,例如时间,地点,公司等。
多规则打分
现在的推荐系统很多是单一规则打分。然而在一些应用中,比如餐厅推荐,用户可能喜欢这个餐厅的事物,环境,价格,服务等,因此需要从不同的规则来对这个餐厅进行打分。评价指标
覆盖率,准确率,召回率,F1,ROC,MAE,MSE

