因为疫情推迟开学,在家把以前看的论文又看了一遍,每重新看一次都有新的收获,在此整理下。
- 1. 流量/速度预测
- 1.1. Deep Spatio-Temporal Residual Networks for Citywide Crowd Flows Prediction(AAAI2017)
- 1.2. DeepSTN+: Context-aware Spatial-Temporal Neural Network for Crowd Flow Prediction in Metropolis(AAAI2019)
- 1.3. UrbanFM: Inferring Fine-Grained Urban Flows(KDD2019)
- 1.4. Attention Based Spatial-Temporal Graph Convolutional Networks for Traffic Flow Forecasting(AAAI2019)
- 1.5. Spatial-Temporal Synchronous Graph Convolutional Networks: A New Framework for Spatial-Temporal Network Data Forecasting(AAAI2020)
- 1.6. HyperST-Net: Hypernetworks for Spatio-Temporal Forecasting(2019AAAI)
- 1.7. Urban Traffic Prediction from Spatio-Temporal Data Using Deep Meta Learning(2019KDD)
- 1.8. StepDeep: A Novel Spatial-temporal Mobility Event Prediction Framework based on Deep Neural Network(KDD2018)
- 1.9. STGRAT: A Spatio-Temporal Graph Attention Network for Traffic Forecasting(AAAI2020)
- 1.10. Connecting the Dots: Multivariate Time Series Forecasting with Graph Neural Networks(2020KDD)
- 2. ETA预测
- 3. 出租车需求预测
- 3.1. Deep Multi-View Spatial-Temporal Network for Taxi Demand Prediction(AAAI2018)
- 3.2. Revisiting Spatial-Temporal Similarity: A Deep Learning Framework for Traffic Prediction(AAAI2019)
- 3.3. Spatiotemporal Multi-Graph Convolution Network for Ride-hailing Demand Forecasting(AAAI2019)
- 3.4. Passenger Demand Forecasting with Multi-Task Convolutional Recurrent Neural Networks(PAKDD2019)
- 3.5. STG2Seq: Spatial-temporal Graph to Sequence Model for Multi-step Passenger Demand Forecasting(2019IJCAI)
- 4. 时间序列预测
- 5. 总结
1. 流量/速度预测
1.1. Deep Spatio-Temporal Residual Networks for Citywide Crowd Flows Prediction(AAAI2017)
张钧波(京东)
郑宇(京东)
https://github.com/lucktroy/DeepST Keras
- 给定所有区域历史T个时间段的inflow和outflow,预测下一个时间段所有区域的inflow和outflow
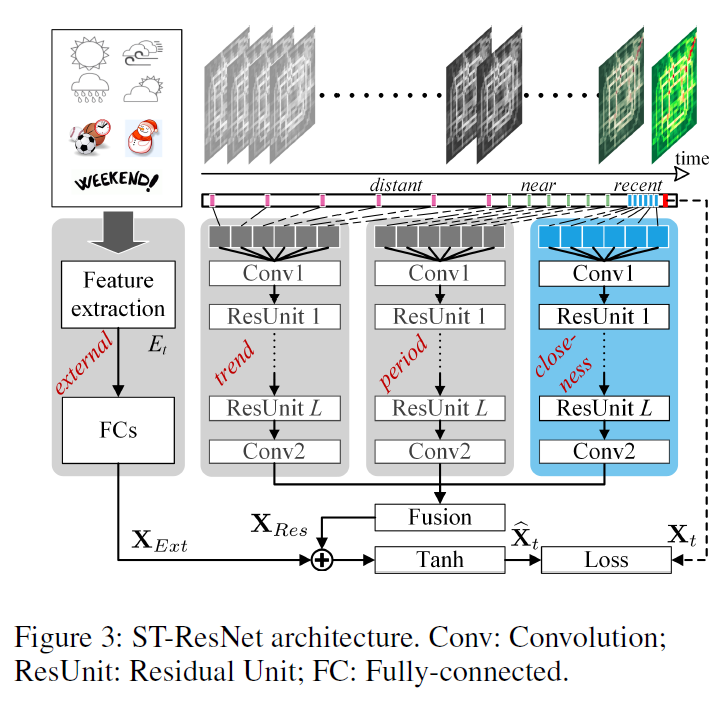
- 每个时间段所有区域的输入是$IJ2$,将输入分为recent,daily,weekly周期,预测第t个时间段的infow和outflow:
- recent:当天前r个时间段
- daily:前d天该时间段
- weekly:前w周该天该时间段
- 外部特征包括:天气,节假日,dayOfWeek。用2层FCN对外部特征进行嵌入,第一层FCN作为嵌入层,第二层FCN转换维度和$X_{Res}$一致。
- 在融合阶段,先将3个时间周期的输出融合,再和外部因素拼接。
- 数据集:北京出租车和NYC自行车流量
- 将flow使用Max-Min归一化到[-1,1],FCN最后一层使用tanh激活函数
1.2. DeepSTN+: Context-aware Spatial-Temporal Neural Network for Crowd Flow Prediction in Metropolis(AAAI2019)
Ziqian Lin(清华大学)
Jie Feng(清华大学)
Ziyang Lu(清华大学)
Yong Li(清华大学)
Depeng Jin(清华大学)
https://github.com/FIBLAB/DeepSTN Keras
- crowd flow预测是给定历史T个时间段,预测区域的inflow和outflow
- 现有研究的缺点:
- 不能捕获长距离空间依赖
- 忽略区域功能对人流的影响(POI)
- 提出DeeoSTN+,有3个组件
- ConvPlus:解决长距离区域的空间依赖
- SemanticPlus:解决区域POI对人流的影响
- early-fusuion模块
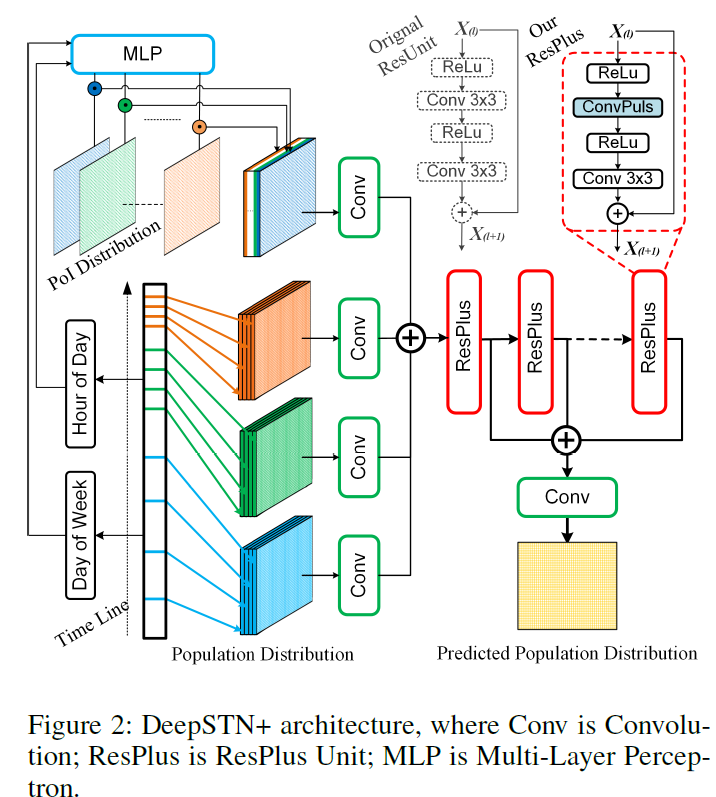
假设预测周四第5个时间段的flow,输入的数据有:
- recent:周四2,3,4个时间段
- day:周一,周二,周三第5个时间段
- week:上上上周四,上上周四,上周四第5个时间段
- time:周四第5个时间段的时间向量
- poi:(C,W,H)所有区域的poi信息
- 【ConvPlus】传统的Conv中kernel的大小远小于网格大小,通常是$3 \times 3$,然后在人流量预测中通常有一些长距离的依赖,例如人们去很远的地方上班。在ConvPlus中,假设原始输入维度是(C,W,H),其中plus维用来捕获长距离依赖
- 正常Conv2D:将原始输入(C,W,H)输入到正常Conv2D中,卷积核有C-plus个,输出维度(C-plus,W,H),
- ConvPlus:再将原始(C,W,H)输入到ConvPlus中,卷积核有plusW\H个,卷积大小为W*H,则输出维度(plus*W*H,1,1),reshape为(plus,W,H)
- 将上面2个卷积的输出拼接成(C,W,H)
- 计算POI在时间上的分布权重
- POI维度$C \times W \times H$,表示每个网格有C类POI
- 时间维度$T \times W \times H$,T=24+7, 首先对时间进行嵌入,通过2D卷积,将31个数变成一个数$1 \times W \times H$,然后将时间repeat成$C \times W \times H$
- 时间和POI逐元素相乘,得到$C \times W \times H$
- 如果需要,还可以再通过K个2D卷积,变成$K \times W \times H$
- 将该张量和3个周期的输出在通道维上拼接。
- crowd flow使用Max-Min归一化到[-1,1],最后一层使用Tanh,范围[-1,1]
- POI使用Max-Min归一化到[0,1]
1.3. UrbanFM: Inferring Fine-Grained Urban Flows(KDD2019)
Yuxuan Liang(XiDian)
Kun Ouyang(新加坡国立)
张钧波(京东)
郑宇(京东)
https://github.com/yoshall/UrbanFM
- 基于粗粒度级的flow,实时推测整个城市细粒度级的flow,提出模型Urban Flow Magnifier (UrbanFM)
- 有2个挑战:粗粒度和细粒度的flow在空间上的相关性、复杂的外部因素。
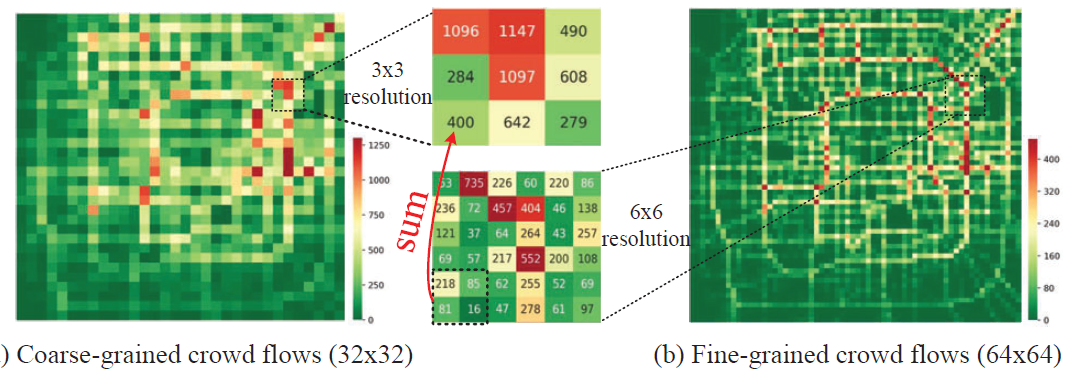
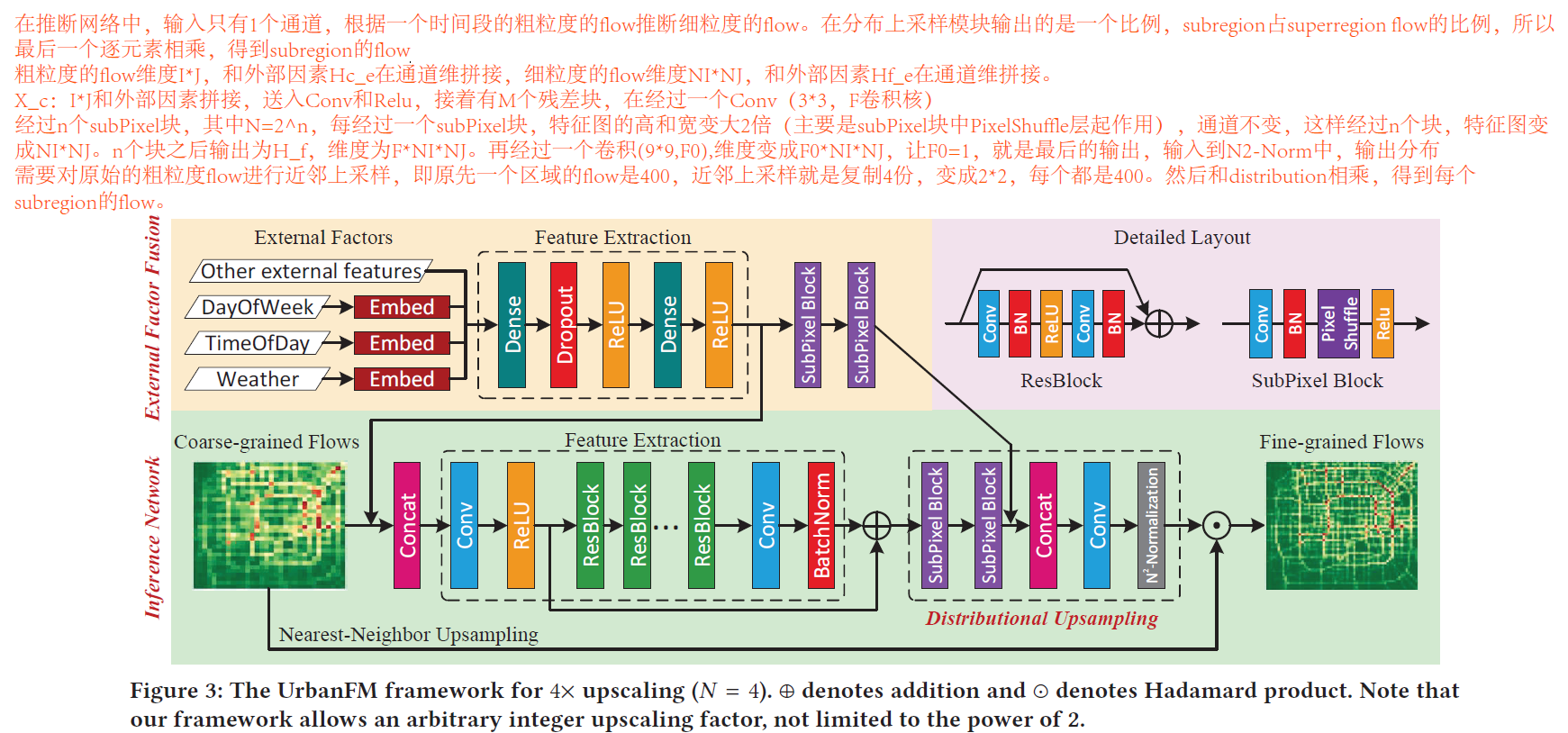
1.4. Attention Based Spatial-Temporal Graph Convolutional Networks for Traffic Flow Forecasting(AAAI2019)
郭晟楠(北京交通大学)
冯宁(北京交通大学)
宋超(北京交通大学)
万怀宇(北京交通大学)
https://github.com/Davidham3/ASTGCN Mxnet
根据所有节点历史T个时间段traffic flow,occupy,speed,预测所有节点未来T_p个时间段的traffic flow。
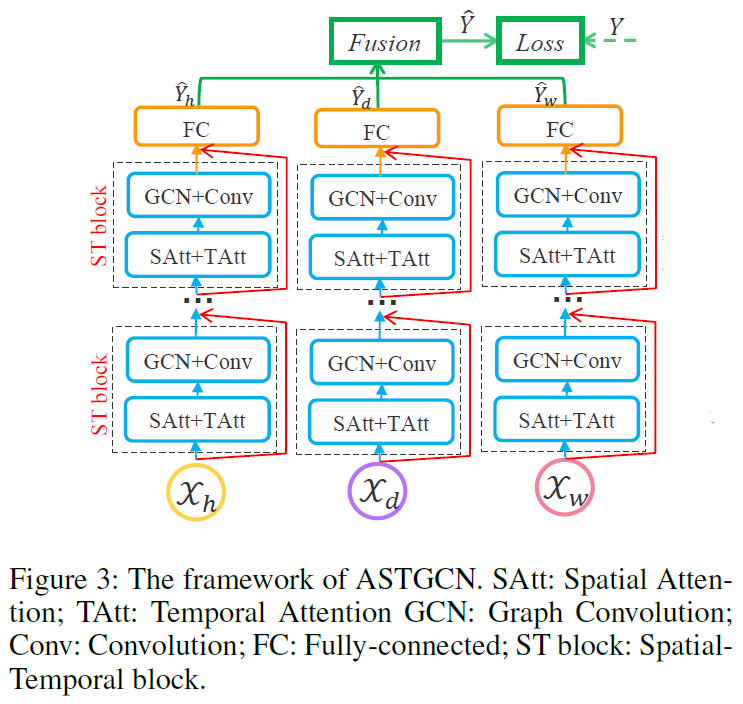
- 三个独立的组件,分别对recent,daily,weekly周期进行建模
- 比如说预测6.14 8:00-8:55的flow,传入的样本是
时:6.14号6:00~7:55(前2个小时)的数据,
天:6.13和6.12(前2天)的8:00-8:55,
周:上周6.17,上上周5.31(前2周)的8:00-8:55
1.5. Spatial-Temporal Synchronous Graph Convolutional Networks: A New Framework for Spatial-Temporal Network Data Forecasting(AAAI2020)
宋超(北京交通大学)
郭晟楠(北京交通大学)
万怀宇(北京交通大学)
https://github.com/Davidham3/STSGCN Mxnet
- 给定所有节点历史T个时间段的车流量,预测所有节点未来$T’$个时间段的车流量,
- 原先的研究通常使用分开的组件捕获时间和空间的相关性,并且忽略了时空数据的异构性。
- 提出Spatial-Temporal Synchronous Graph Convolutional Networks (STSGCN)
- 对于图中的每个节点,它的影响范围有3种,这是该文章提出的一个新观点,以前的研究中通常只考虑前2种。
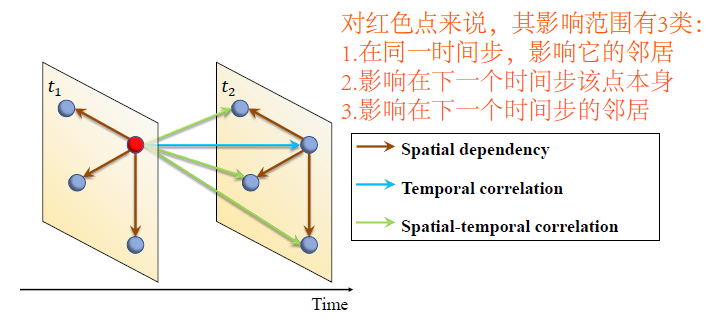
- 本文强调的内容有2点:
- 局部的时空关系,称作localized spatial-temporal correlations
- 时空数据的异质性,居住区和商业区,早上和晚上
- 使用连续3个时间步的图数据来构建localized spatial-temporal graph,local指的是在时间上局部
假设原先一个图中有N个节点,图信号矩阵为$N \times C$,邻接矩阵为$N \times N$,现在3个图来构建一个局部时空图,图信号矩阵为$3N \times C$,邻接矩阵为$3N \times 3N$,邻接矩阵中非0即1
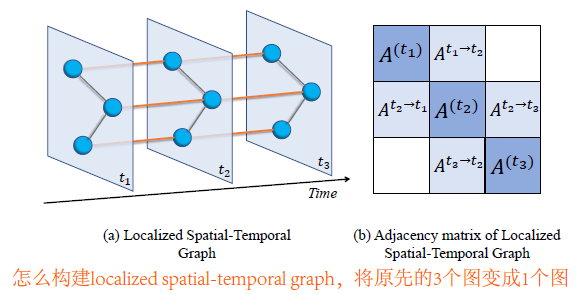
- 但是把3个图构成1个图失去了图之间的时间关系,模型可能会认为这是一个有3N个节点在一个时间步的信息,为了区域这3个图的时间关系,受ConvS2S启发,为时空网络序列$N \times C \times T$添加位置嵌入,增加时间嵌入矩阵$C \times T$,空间嵌入矩阵$N \times C$,这2个矩阵是通过模型学习的,当模型训练好之后,这2个矩阵可以包含图的时间和空间信息。然后把这2个嵌入矩阵和原始的图信号矩阵相加,这样图中就包含了时间和位置信息。
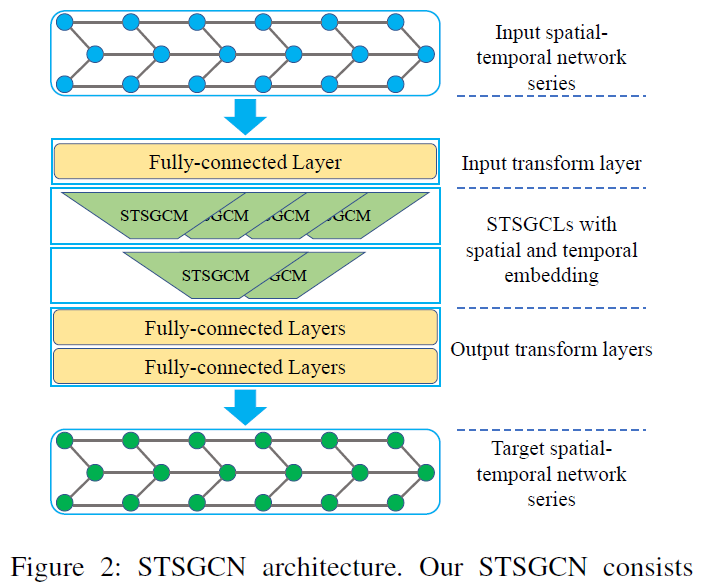
- 图中模型框架:多个STSGCM构成STSGCL,多个STSGCL构成STSGCN。STSGCN就是多层图卷积,从局部时空图中捕获邻居信息。STSGCL一层中有多个STSGCM,一个样本中每个时间段的局部时空图都用一个STSGCM来建模。
- 第一个FCN成将输入转换到高维空间,提高模型的表示能力
- 【STSGCM】中包含多层图卷积,使用GLU作为激活函数,其中sigmoid作为门控机制,控制哪个节点的信息可以流入到下一层。图卷积计算定义在顶点域,意味着不需要计算图的拉普拉斯矩阵
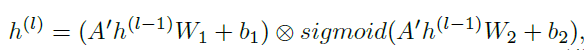
STSGCM的架构如下:参考JK-net,一共有L个图卷积层,每一层的输出都输入到AGG层中,AGG层将接收到的L个输出进行max聚合,最终得到一个输出$3N \times C_{out}$,然后进行裁剪,将前中后3个时间步的数据只保留中间时间步,即$N \times C_out$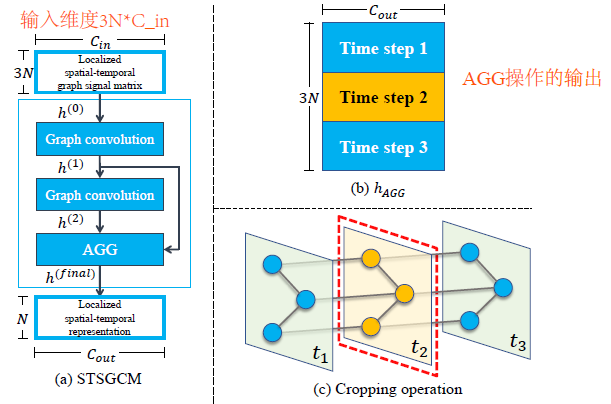
- 【STSGCL】多个STSGCM组成一个STSGCL层,其输入维度$T \times N \times C$,使用滑动窗口每次取3个时间段段的图构成$3N \times C$,一共构成$T-2$个局部时空图,然后需要$T-2$个STSGCM,最终输出$T-2个N \times C_{out}$,将其拼接为$(T-2) \times N \times C_{out}$,再输入到下一个STSGCL中。【注意】每个局部时空图是通过滑动窗口获得,每个时空局部图的邻接矩阵是不变的,而不是提前处理好局部图输入到模型中,这样会省空间
- 上面使用的邻接矩阵$3N \times 3N$中的值非0即1,每个邻居聚合的权重相等,聚合能力会受到限制,这里对此做出改进,将邻接矩阵乘上一个Mask矩阵,对每个邻居赋予不同的权重,其中Mask矩阵是可学习参数,维度$3N \times 3N$
- 最后的FCN将STSGCL的输出转换成预测的格式。STSGCL的输出格式为$T \times N \times C$,reshape成$N \times TC$,然后使用$T’$个2层全连接,每个全连接输出维度为$(N,1)$,然后将$T’$个全连接的输出拼接成$N \times T’$
- 损失函数使用Huber Loss,对异常值不敏感
- 使用mean-std归一化,训练集:验证集:测试集=6:2:2,模型包含4个STSGCL,每个STSGCM包含3个图卷积
1.6. HyperST-Net: Hypernetworks for Spatio-Temporal Forecasting(2019AAAI)
潘哲逸(上海交通大学)
梁宇轩(西安电子科技大学)
张钧波(京东)
易修文(京东)
郑宇(京东)
论文声称第一个考虑空间和时间内在因果关系的深度框架。
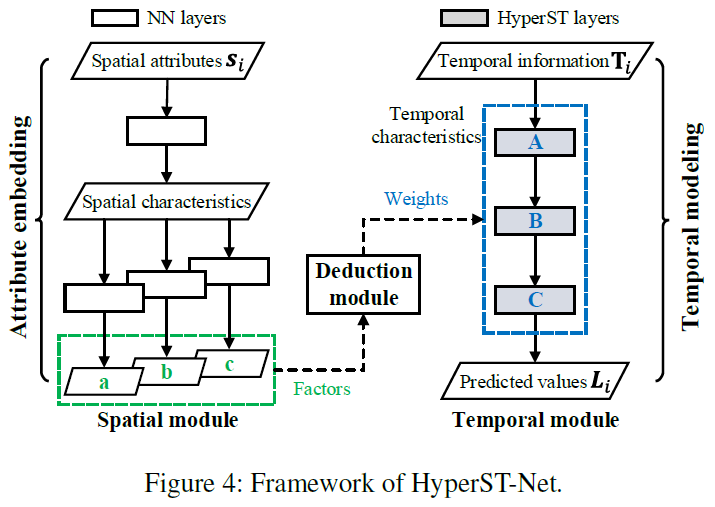
- 该论文提出的只是一个HyperNetwork框架,并不是一个具体的模型。
- HyperNetwork:和以往不同,以前都是一个网络的输出,输入到下一个网络中,超网络是一个网络的输出作为另一个网络的参数。
- 该模型有3个模块:空间模块,时间模块,推理模块。将空间模块的输出经过推理模块,得到的输出作为时间模块的权重参数,以此捕获时间和空间的内在因果关系。
- 这只是一个框架,可以变换成多种模型。在空间模块中如果使用全连接就是HyperST-Dense,使用卷积就是HyperST-Conv。
1.7. Urban Traffic Prediction from Spatio-Temporal Data Using Deep Meta Learning(2019KDD)
潘哲逸(上海交通大学)
梁宇轩(西安电子科技大学)
张钧波(京东)
郑宇(京东)
https://github.com/panzheyi/ST-MetaNet Mxnet
- 使用图中所有节点历史T个时间段的flow或speed,预测所有节点未来
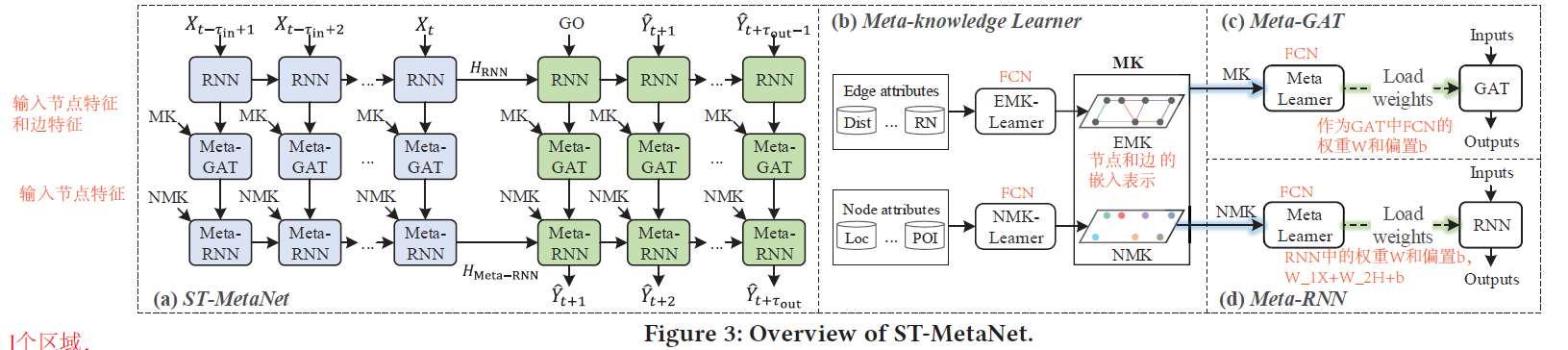
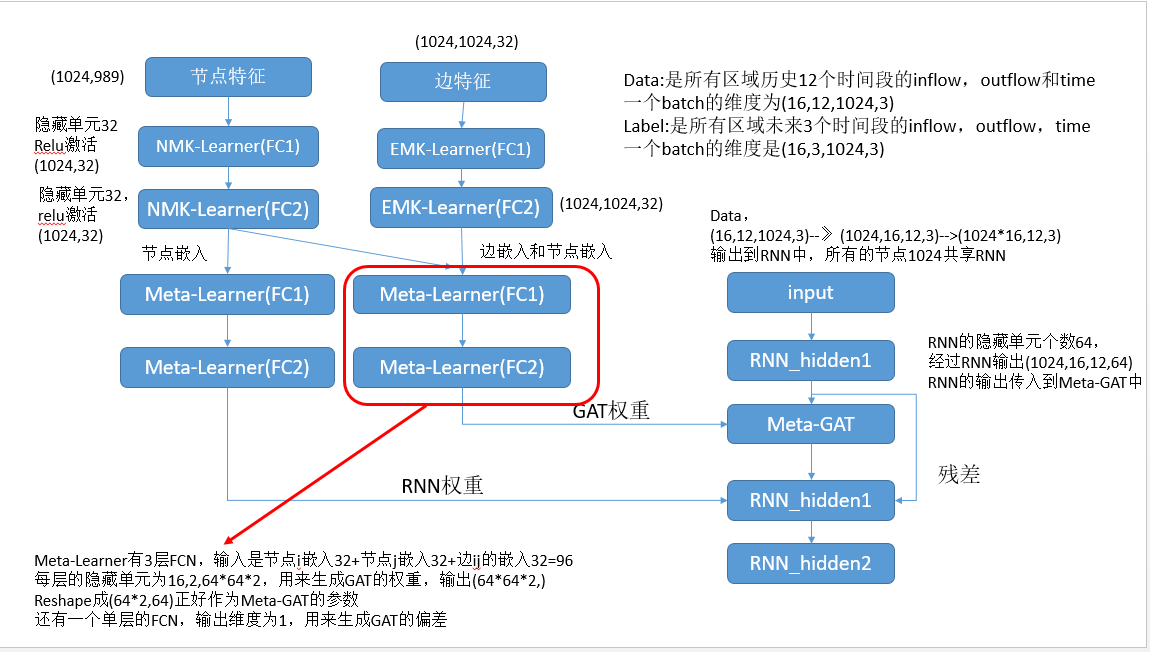

- 本论文用的图,但是实验中有一个$I \times J$的网格数据,将网格数据构建成图
- 本论文来表示1张图有2个矩阵:图信号矩阵(N,D)和边特征矩阵(N,N,C)。对于网格数据来说,图信号矩阵表示每个网格POI个数,道路个数。边特征表示2个两个网格的道路个数。这都是静态数据,不随着时间变化。
【总结】发现上面这2个论文都是一个网络生成另一个网络的参数,查阅资料发现这叫做meta-learning,先记录一下以后再自己看
1.8. StepDeep: A Novel Spatial-temporal Mobility Event Prediction Framework based on Deep Neural Network(KDD2018)
Bilong Shen(清华大学)
梁晓丹(卡耐基梅隆)
- Spatial-Temporal mobility Event Prediction framework based on Deep neural network (StepDeep)同时考虑时间和空间模式,给定所有区域历史T个时间段的出租车流量和外部因素,预测所有区域在下一个时间段出租车的inflow和outflow。
- 网格区域中的flow随时间变化,可以看做一个视频(T,C,W,H),进而看做是视频预测任务
- 数据集NYC出租车轨迹数据,将NYC网格划分,计算每个区域的inflow和outflow,
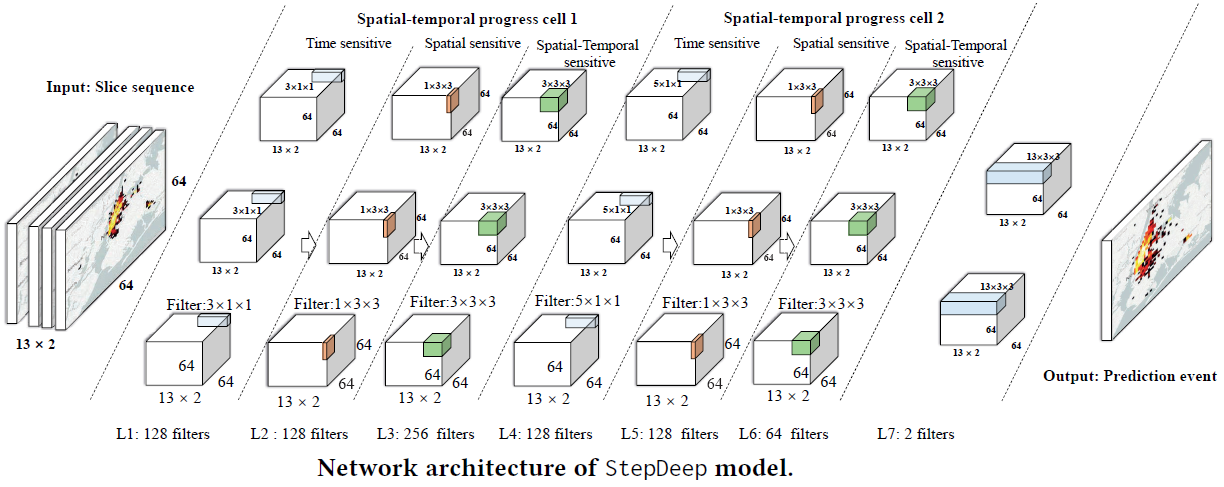
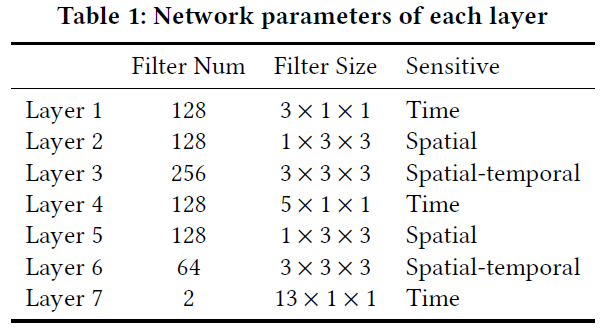
- 提出3种卷积:时间卷积,空间卷积,时空卷积。将输入(T,C,H,W)输入到以上7层卷积中,最终输出(C,H,W)表示下一个时间段所有区域的inflow和outflow,
1.9. STGRAT: A Spatio-Temporal Graph Attention Network for Traffic Forecasting(AAAI2020)
Cheonbok Park(韩国大学)
Chunggi Lee(韩国大学)
Hyojin Bahng(韩国大学)
- 根据所有节点历史T个时间段的交通速度,预测所有节点未来T个时间段的交通速度(T=12),时间多预测多,Seq2Seq架构
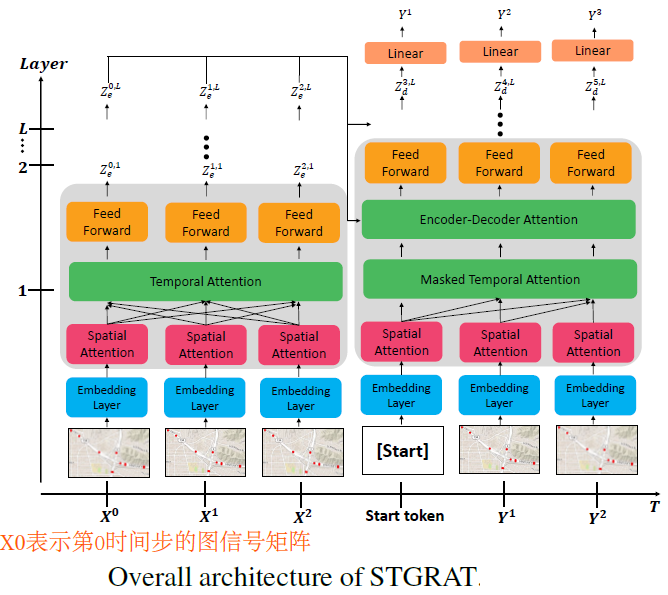
- Encoder layer中有3个sublayer:空间Attention层,时间Attention层和point-wise FCN。
- 空间Attention:关注每个时间步上空间邻近的节点
- 时间Attention:关注单个节点,输入时间序列的不同时间步
- 整个Encoder = 1个嵌入层 + 4个Encoder layer,使用LINE对图节点进行嵌入
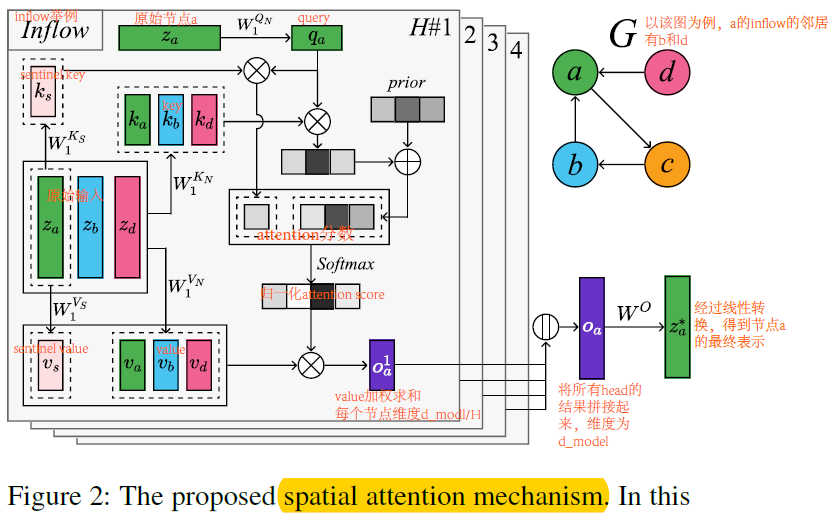
- 空间Attention层:参考Transformer,中心结点作为query,其邻居作为key和value,计算每个节点新的表示。
- 时间Attention==Transformer,输入维度(batch_size,T,N,D),计算时间步之间的attention分数,输出维度(batch_size,T,N,D)
- Point-wise FFN和Transformer中一样,使用2层FCN,中间使用GELU激活函数,Transformer使用的是ReLU激活函数。
- Decoder layer有4个sublayer:空间Attention层,mask时间Attention层,Encoder-Decoder Attention层,point-wise FFN层。整个Decoder层=1个嵌入层+4个Decoder层。
- 本模型比Transformer多了一个空间Attention层,其余都一样,因为时间Attention层、FFN和Transformer的一样
1.10. Connecting the Dots: Multivariate Time Series Forecasting with Graph Neural Networks(2020KDD)
该模型使用图网络模型捕获交通数据或其他领域数据中的时间和空间相关性。
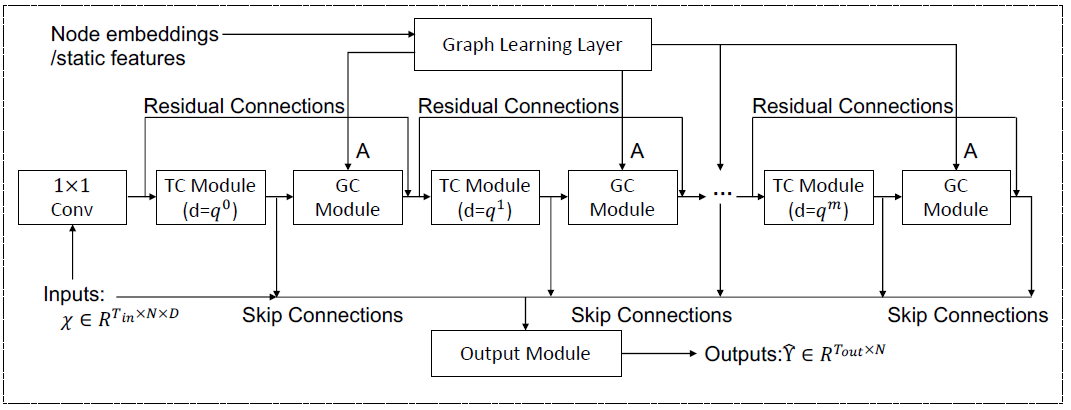
该模型有2个模块,图卷积模块和时间模块。其中图卷积模块主要解决4个问题:
- 节点间的空间相关性
- 如何构造图
- 如何解决图卷积过度平滑问题
- 大图如何训练问题
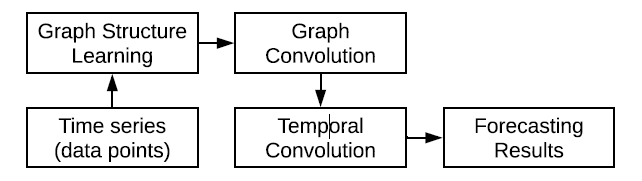
首先图信号矩阵,输入到图结构学习模块,构造图的邻接矩阵。注意这里的邻接矩阵不是预先定义好的,而是根据网络模块学习得到,据此构建图,然后输入到GCN中捕获时间相关性,然后输入到时间卷积捕获时间相关性,最后预测结果。
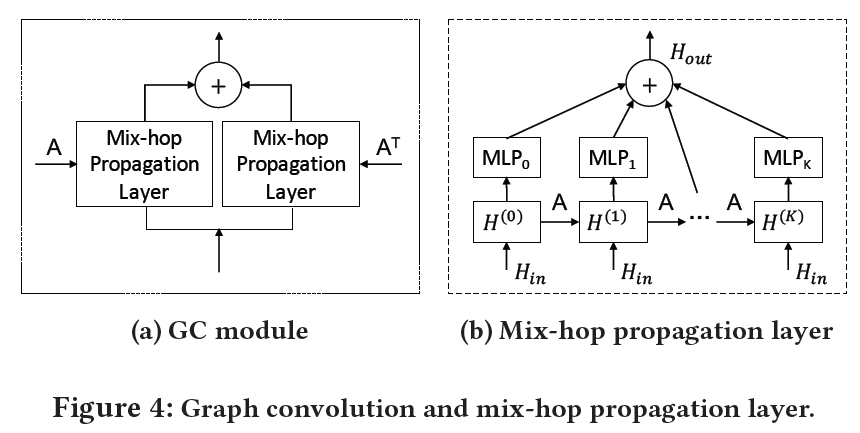
在构造图时,通过模型学习节点的嵌入矩阵,然后根据嵌入矩阵计算节点的相似性,为每个节点选取相似性前k的节点作为其一阶邻居。邻接矩阵不随着时间变化。
在图卷积模块,参考Min-hop架构,每个GCN层的输入会加上原始的图信号矩阵,避免图过度平滑问题,然后再将所有GCN层的输出加起来,进行融合。为了解决大图训练的问题,在进行GCN时,每次随机选取几个节点进行GCN运算,而不是使用所有的节点。
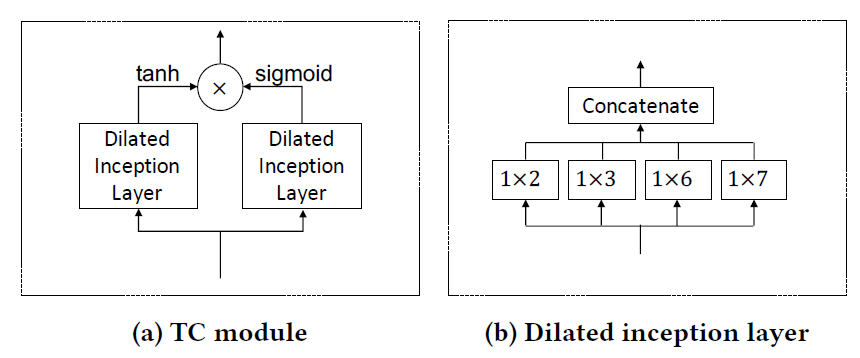
在时间模块,使用一维空洞卷积,捕获长期的时间依赖,同时参照Inception结构,设置不同的卷积核,来捕获不同力度的周期性,例如小时周期,天周期,周周期。
总结:
- 根据模型学习节点嵌入,由此构建邻接矩阵,构建相似性图
- 使用一维空洞卷积捕获时间相似性,使用不同的卷积核捕获不同粒度的周期性。
2. ETA预测
2.1. When Will You Arrive? Estimating Travel Time Based on Deep Neural Networks(AAAI20)
王东(杜克大学)
张钧波(京东)
郑宇(京东)
https://github.com/UrbComp/DeepTTE Pytorch
- 端到端Deep learning framework for Travel Time Estimation(DeepTTE),给定路径P和外部因素(weather,day of week,开始时间)预测整个path的时间
- 原先的工作都是预测travel中单个路段的耗时,然后再把每个路段的时间加起来,缺点是没有考虑到道路交叉口,红绿灯等影响,错误累积
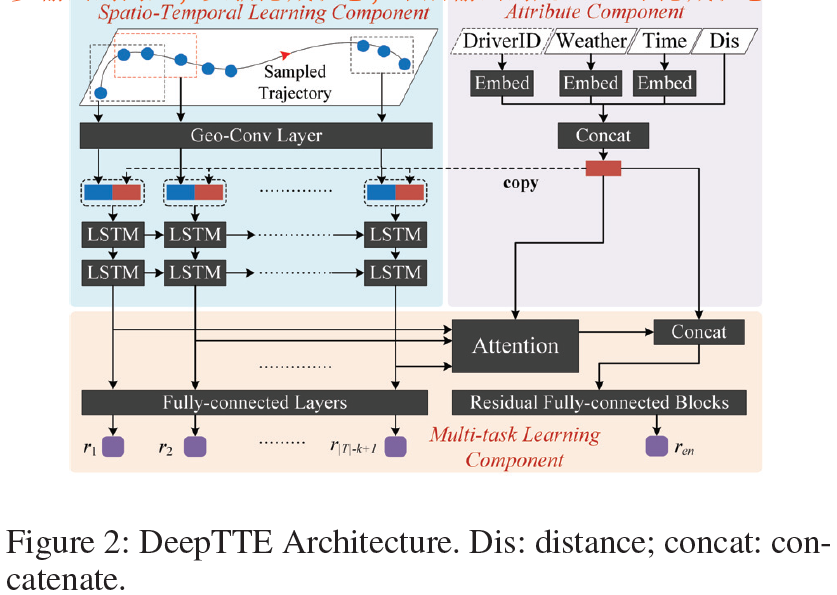
- DeepTTE提出geo-convolution,将地理信息加入到传统Conv中,捕获空间相关性
- 多任务学习,同时预测local path和entir path的时间,在loss中限制2者的权重
- 在生成测试数据时,将历史轨迹点中的时间戳都去掉(因为要预测出行时间,所以测试数据不能带有事件信息),从轨迹中抽样等距离的点组成路径P
DeepTTE一共有3个组件
- Attribute组件:外部因素:天气(one-hot),司机ID(one-hot),weekID和timeID(one-hot),都是类别值,不能直接输入到网络中,需要先嵌入层低维向量,参考(2016NIPS)A Theoretically Grounded Application of Dropout in Recurrent Neural Networks,然后再和整个path的距离拼接作为该组件的输出
- Geo-Conv层,历史轨迹是一个GPS序列,为了捕获空间依赖使用1D卷积,将历史轨迹序列先经过FCN变成一个矩阵$T \times V$,T个轨迹点,每个轨迹点有V个特征,然后使用C个k*V的1D卷积,卷积输出的时间维度变成$T-k+1$,将C个卷积核输出的结果拼接,然后再拼接上local path的距离,输出结果为$T-k+1 \times D$
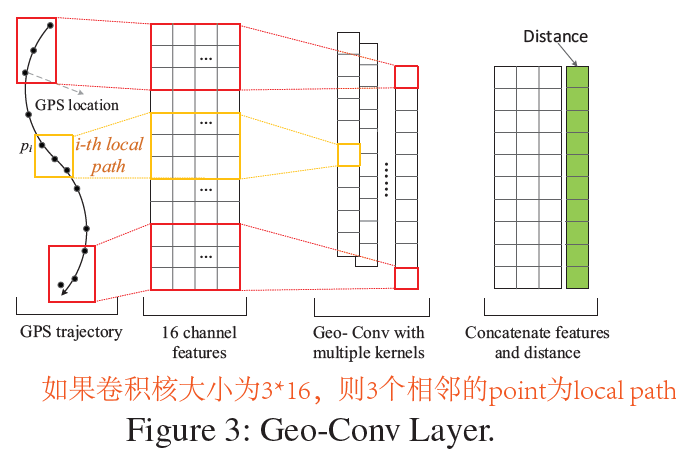
- 然后将$T-k+1 \times D$的序列拼接外部因素输入到LSTM中,每个时间步表示一个local path,将隐藏状态用来预测每个local path的时间作为辅助任务
- LTSM输出$T-k+1$个时间步,将其整合成1个向量,通过和外部因素做Attention,对每个local path赋予不同的权重,然后再和外部因素拼接,用来预测entir path的时间
训练阶段预测local path和entir path的时间,在测试阶段只预测entir path的时间
在训练时,使用MAPE作为loss,包含辅助任务和主任务的loss
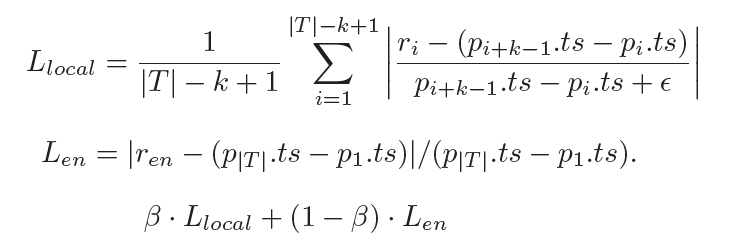
这篇文章也是经典的CNN+LSTM的架构,只是这里的CNN是1D卷积。在融合外部因素上也是CNN的输出和外部因素拼接,送入到LSTM中。
3. 出租车需求预测
3.1. Deep Multi-View Spatial-Temporal Network for Taxi Demand Prediction(AAAI2018)
姚骅修(Pennsylvania State University)
吴飞(Pennsylvania State University)
柯金涛(香港科技大学)
Xianfeng Tang(Pennsylvania State University)
叶杰平(滴滴出行)
https://github.com/huaxiuyao/DMVST-Net Keras
- 出租车需求预测,根据SS的小区域,历史T个时间段的出租车订单数据,预测下一个时间段中心区域的订单。*空间和时间都是多预测一
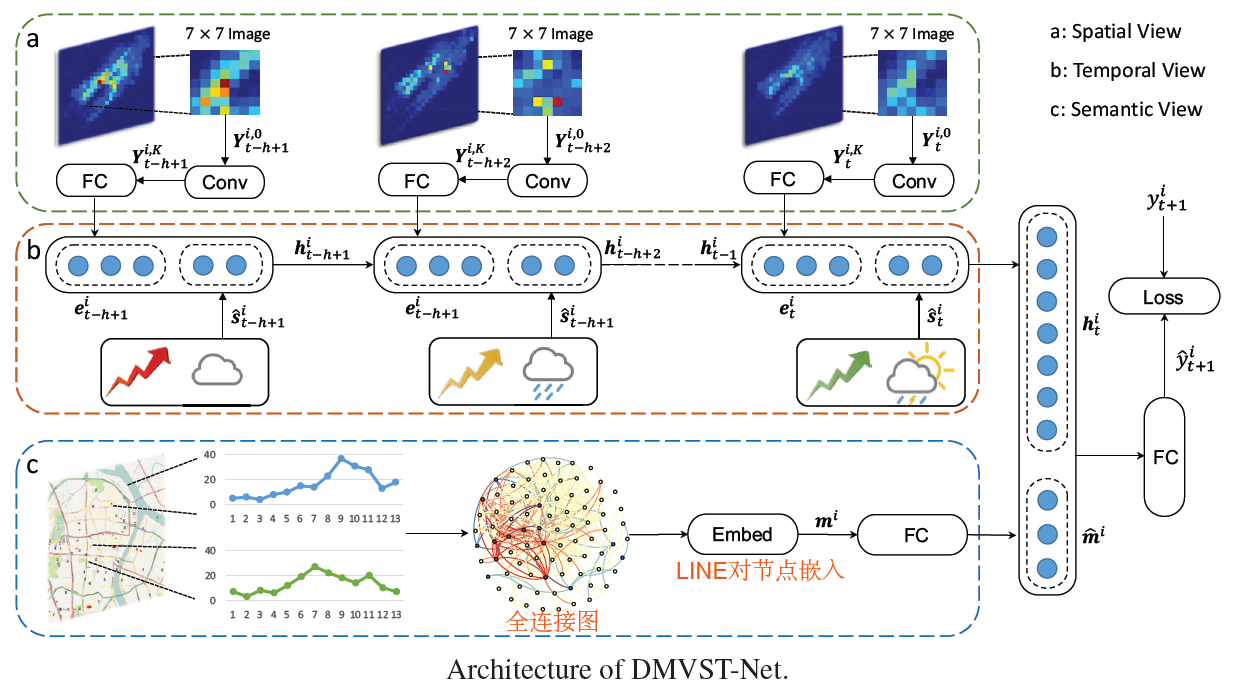
- 现有的研究都是使用CNN对空间建模,LSTM对时间建模,时间和空间分开建模,本文的模型是对时间和空间同时建模
- 本文提出DMVST-Net,有3个view:时间view(通过LSTM建模时间关系),空间view(使用local CNN建模邻近空间关系),语义view(建模功能相似的区域)
- local CNN只考虑空间邻近的区域,但是不能考虑离得较远,但出租车需求模型相似的区域,所以又加了语义view

- 输入是S*S的邻居区域,如果是边界区域,其邻居用0填充
- 在LSTM每个时间步的特征中拼接天气等外部因素
- local CNN和LSTM对时间和空间建模,然后再构建图,表示区域之间需求相似性(功能相似性)。求出2个区域每周的需求量,形成一个时间序列,使用DTW计算2个序列的相似性,即2个区域的相似性,作为图中的边,创建一个全连接图(任意2个区域都相连),使用LINE对图中节点进行嵌入。
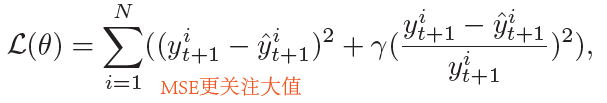
损失函数由MSE和MAPE组成,MSE更关注大值,为了避免模型偏向大值的方向训练,又添加了MAPE,但是使用MAPE时,真实值中不能有0- Max-Min激活,最终输出值在[0,1]之间,反归一化
- 最后一层FCN用sigmoid激活,其余的FCN用ReLU激活
3.2. Revisiting Spatial-Temporal Similarity: A Deep Learning Framework for Traffic Prediction(AAAI2019)
姚骅修(Pennsylvania State University)
Xianfeng Tang(Pennsylvania State University)
https://github.com/tangxianfeng/STDN Keras
- 主要问题是:原先研究中的空间相关性都是静态的,本次建模动态的空间相关性。时间有天和周周期,且有时间偏移。
- 提出模型Spatial-Temporal Dynamic Network(STDN)来traffic prediction
- 根据SS小区域历史T个时间段的volume和flow,预测下一个时间段中心区域的volume,*空间和时间都是多预测一
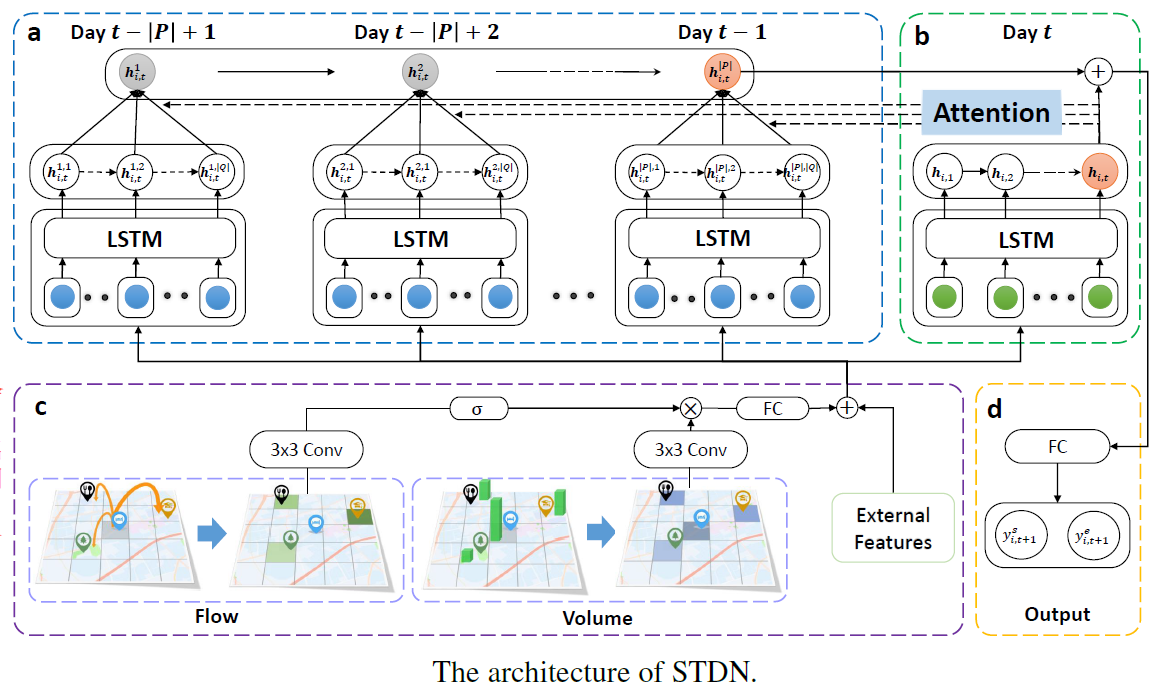
- 将交通量分为2种
- traffic volume:无方向,一个区域进来和出去的流量。
- traffic flow:有方向,从区域i到区域j的流量
- flow-gated local CNN每次输入S*S区域的volume和flow,其中flow起到门控作用,值在[0,1]之间,如果2个区域之间flow大,即门控的值大,2个区域的相关性强。每个时间段经过local CNN输出的值,再拼接上该时间段的天气等外部因素送入LSTM中
- 时间偏移Attention:比如预测第t+1个时间段的volume,用到当天前t=7个时间段的数据(短期依赖),前P=3天(长期依赖),每天Q=3个时间段(解决时间偏移问题)。
- 先将短期的t个时间段数据输入LSTM中,得到隐藏状态h做Attention。前P天,每天Q个时间段输入到LSTM中,每天得到Q个隐藏状态,和h做attention,将Q个整合成1个,最终生成P个隐藏状态,再输入到LSTM,得到长期依赖的隐藏状态,然后再和短期的隐藏状态h拼接,输入到FCN中。
- 短期的隐藏状态和长期的隐藏状态做Attention
- 短期的隐藏状态和长期的隐藏状态拼接
- 数据集:出租车流量和自行车流量
- STDN和DMVST-Net是同一作者发的
- 两者都是:空间和时间多预测一
- STDN:local CNN + LSTM
- DMVST-Net:flow-gated local CNN + Periodically Shifted Attention LSTM
3.3. Spatiotemporal Multi-Graph Convolution Network for Ride-hailing Demand Forecasting(AAAI2019)
Xu Geng(香港大学)
Yaguang Li(南加利福尼亚)
Lingyu Zhang(滴滴AI)
杨强(香港大学)
叶杰平(滴滴)
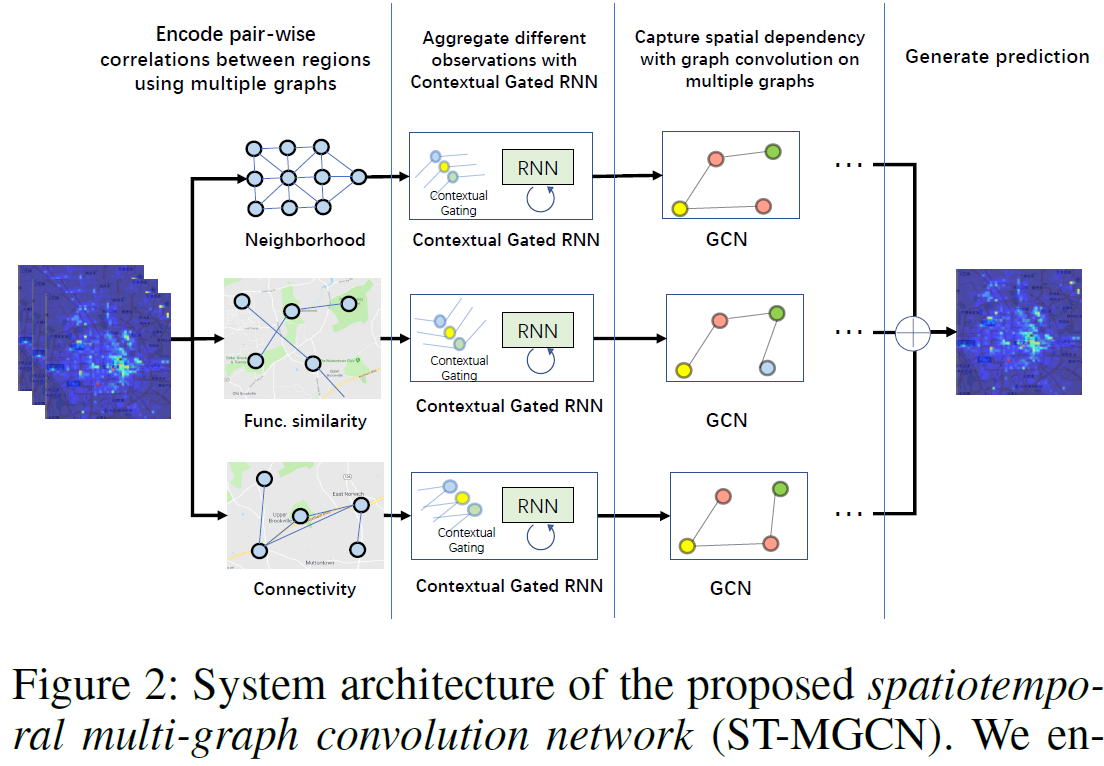
- 问题:根据所有区域历史T个时间段的订单数,预测所有区域下一个时间段的订单数
- 将研究区域划分为网格,根据网格构建3个图,这3个图的图信号矩阵一样,只是邻接矩阵不一样。分别
- 邻居图(3*3网格,每个区域有8个邻居,2个区域是邻居,邻接矩阵为1,否则为0);
- 区域功能相似图(根据每个区域的POI,计算相似性,值在0<=sim<=1);
- 交通连通图(看2个区域是否在高速公路,公共交通等方式相连,相连为1,否则为0)
- Channel-wise attention参考CV领域,图像输入$X \in \mathbb{R}^{W\times H \times C}$,计算每一个通道的权重$s$,然后再把输入和通道权重相乘$\tilde{\boldsymbol{X}}_{:,:,c}=\boldsymbol{X}_{:,:, c} \circ s_{c} \quad for \quad c=1,2, \cdots C$
- 一共有3类图,每类图的邻接矩阵不一样,图信号矩阵一样,表示该区域的订单数,图信号矩阵是动态的,每个时间段的图信号矩阵都不一样,一共有T个时间段。拿一个图距离,输入为(T,V,P),根据通道维的attention,这里将时间维作为通道维,对T个时间段做Attention,最终得到attention后的输入(T,V,P),然后输入到RNN中,因为RNN一次只能输入一个节点T个时间段的数据,但是这里有V个节点,这里V个节点共享一个RNN,最终得到隐藏状态,然后在把3个图的输出融合,得到最终的预测结果(所有区域下一个时间段的订单数)
- T为5,根据ST_ResNet,其中3个邻近,1个天周期,1个周周期。
3.4. Passenger Demand Forecasting with Multi-Task Convolutional Recurrent Neural Networks(PAKDD2019)
Lei Bai1(University of New South Wales)
Lina Yao(University of New South Wales)
Salil S. Kanhere(University of New South Wales)
- 根据历史T个时间段相似区域出租车demand和人流量,预测下一个时间段中心区域的出租车demand。时间和空间都是多预测一
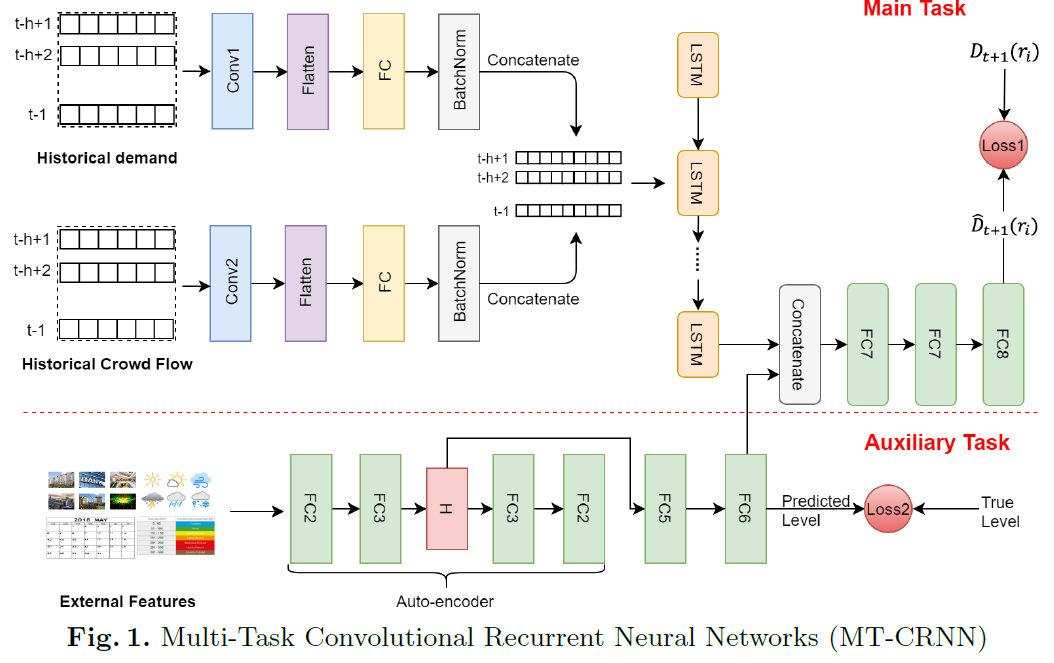
- 根据路网来划分区域
- 多任务预测:
- 主任务(回归):预测中心区域的订单需求数
- 辅助任务(分类):预测中心区域的订单需求等级(高、中、低)
- 主任务输入的是相似区域的订单数据和人流量数据,其中根据POI和taxi demand来计算2个区域的相似性,为中心区域选择m=3个最相似区域
- 使用外部信息(天气等)来预测订单需求等级(辅助任务)
3.5. STG2Seq: Spatial-temporal Graph to Sequence Model for Multi-step Passenger Demand Forecasting(2019IJCAI)
Lei Bai1(University of New South Wales)
Lina Yao(University of New South Wales)
Salil S. Kanhere(University of New South Wales)
- 基于GCN,提出Seq2Seq的模型,来进行多步预测。本文说这是第一篇使用GCN来进行多步预测
大部分的研究只预测下一个时间段,本文预测多个时间段。以前的研究预测多个时间段使用seq2seq架构,里面是RNN或者其变体(ConvLSTM),有个问题是:在decoder中,将前一个时间步的预测结果作为输入,会出现错误累积
将城市划分为N个小区域,基于网格或道路划分都可以
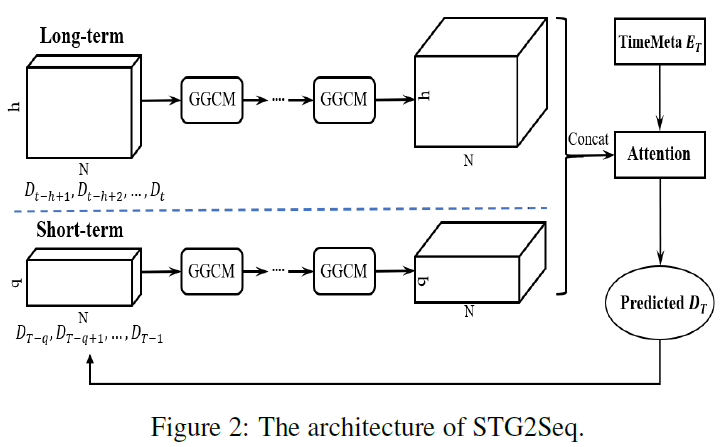
给定历史h个时间段的D(需求量,维度$N \times D_{in}$)和所有时间段的时间信息E,预测未来$\tau$个时间段的需求量
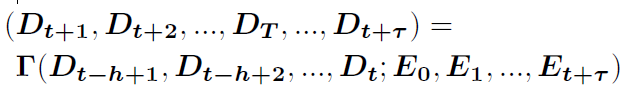
图中每个节点表示一个小区域,图的邻接矩阵A中非0即1,根据区域demand的模式,计算2个区域的皮尔森相似度,如果相似度大于某个阈值,邻接矩阵为1,否则设置为0
模型主要有3个模块,假设预测时间段为$t+1,t+1,…,t+\tau$
- 长期encoder:历史长期h个时间段,(h,N,D)
- 短期encoder:最近的q个时间段,(q,N,D)
- Attention模块:在历史时间段中,找出对预测时间段的重要性
长期encoder和短期encoder都是由GGCM组成,一个GGCM中有多个GCN。拿长期encoder举例,输入维度(h,N,D),每k个时间段(k,N,D)输入到GCN中,h个时间段一共有h-k+1个GCN,即经过一个GGCM,输入维度变成(h-k+1,N,D1),每经过一个GGCM,时间维度都会变小,为了防止时间维度变小,会拼接上一个(k-1,N,D1)的全0padding,让其变成(h,N,D1)的维度,然后再输入到下一个GGCM中。

- 对于一个GCN中,输入维度是(k,N,D),reshape成(N,k*D),然后使用下面的公式。下面这个公式用到了残差连接,在经过GCN后,加上原来的$X^l$,同时和后面的sigmoid逐元素相乘,控制线性转换的哪部分可以通过门。
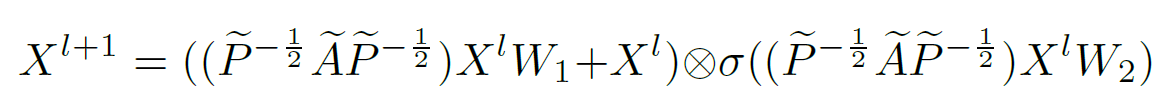
- 在经过长期encoder和短期encoder后,将输出拼接,得到$(h+q,N,d_{out})$
- 时间Attention:历史h+q个时间段对target时间段的影响不同,为了求出不同的影响程度,使用Attention机制。将$Y_{h+q}$reshape成$(h+q) \times (N \times d_{out})$其中$W_{3}^{Y} \in \mathbb{R}^{(h+q) \times\left(N \times d_{\text {out }}\right) \times 1}, W_{4}^{E} \in \mathbb{R}^{d_{e} \times(h+q)}$,$b_{1} \in \mathbb{R}^{(h+q)}$ 得到的Attention分数$\boldsymbol{\alpha} \in \mathbb{R}^{(h+q)}$
- 通道Attention:经过上一步的时间Attention,得到的结果$Y_{\alpha}$维度为$N \times d_{out}$,然后再经过通道Attention,将$Y_{\alpha}$reshape成$N \times d_{out}$其中$W_{5}^{Y} \in \mathbb{R}^{d_{\text {out}} \times N \times 1}, W_{6}^{E} \in \mathbb{R}^{d_{e} \times d_{\text {out}}}, b_{2} \in \mathbb{R}^{d_{out}}$,$\boldsymbol{\beta} \in \mathbb{R}^{d_{\text {out }}}$
- 经过通道Attention,求得$Y_{\beta}$就是一个时间段的预测值
- 总结:
- 图的邻接矩阵非0即1,计算2个区域的相似度,大于阈值为1,否则为0
- 将历史时间段分为长期和短期,在历史时间段上设置一个长度为k的滑动窗口,每k个时间段都用不同的GCN来捕获空间关系
- 时间Attention:经过encoder后,将长期和短期的输出拼接,形成h+q个时间段,计算对target的时间段的时间Attention
- 通道Attention:借鉴CV领域的思想《(CVPR2017)-Spatial and channel-wise attention in convolutional networks for image captioning》
- 使用GCN捕获空间相关性,然后分别使用时间Attention和通道Attention
4. 时间序列预测
4.1. RESTFul: Resolution-Aware Forecasting of Behavioral Time Series Data(2018CIKM)
吴宪(University of Notre Dame)
史宝旭(University of Notre Dame)
Yuxiao Dong(微软)
黄超(University of Notre Dame)
本文使用多种时间粒度的时间序列数据来预测。
模型为RESolution-aware Time Series Forecasting (RESTFul)
第一个使用多种时间粒度来进行行为时间序列预测
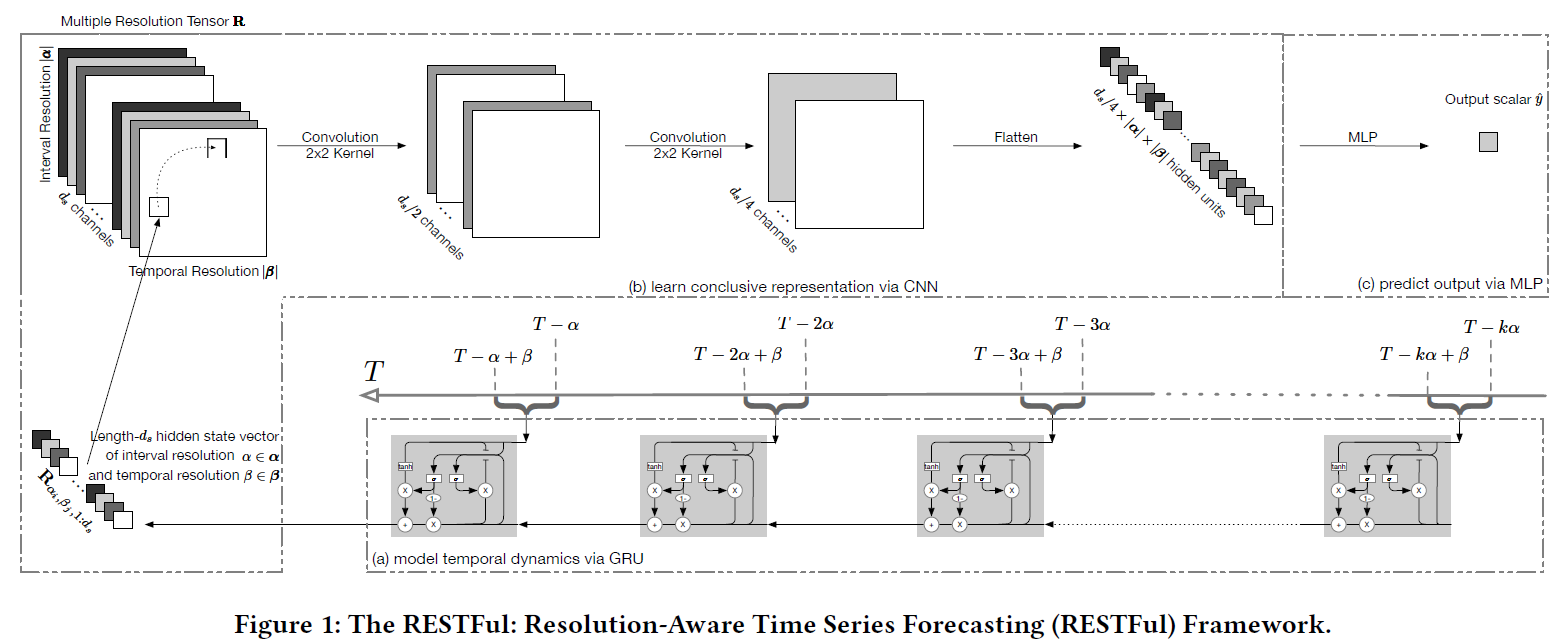
- 有2个参数$\alpha和\beta$,取值{day,week},限制α>=β,
$\alpha$=1week,$\beta$=1day,表示1周测量1次,1次测1天。
$\alpha$=1week,$\beta$=1week,表示1周测量1次,1次测1周。
有一个完整的时间序列,要从中隔抽取不同时间粒度的时间序列。$X=\left[x_{1}, \ldots, x_{t}, \ldots, x_{T-1}, x_{T}\right]$,不同的$\alpha和\beta$就构成不同时间粒度的序列,序列长度为k,这里设置为5。 - 对于每一个时间序列都用GRU来捕获时间相关性,得到一个隐藏状态,那么n个时间序列就有n个隐藏状态
- 将所有的隐藏状态reshape成$\alpha \beta d$的张量,然后使用卷积融合不同粒度。
- 使用数据集:销售数据,311投诉数据
4.2. Multi-Horizon Time Series Forecasting with Temporal Attention Learning(KDD2019)
Chenyou Fan(京东金融)
Yuze Zhang(京东金融)
Yi Pan(京东金融)
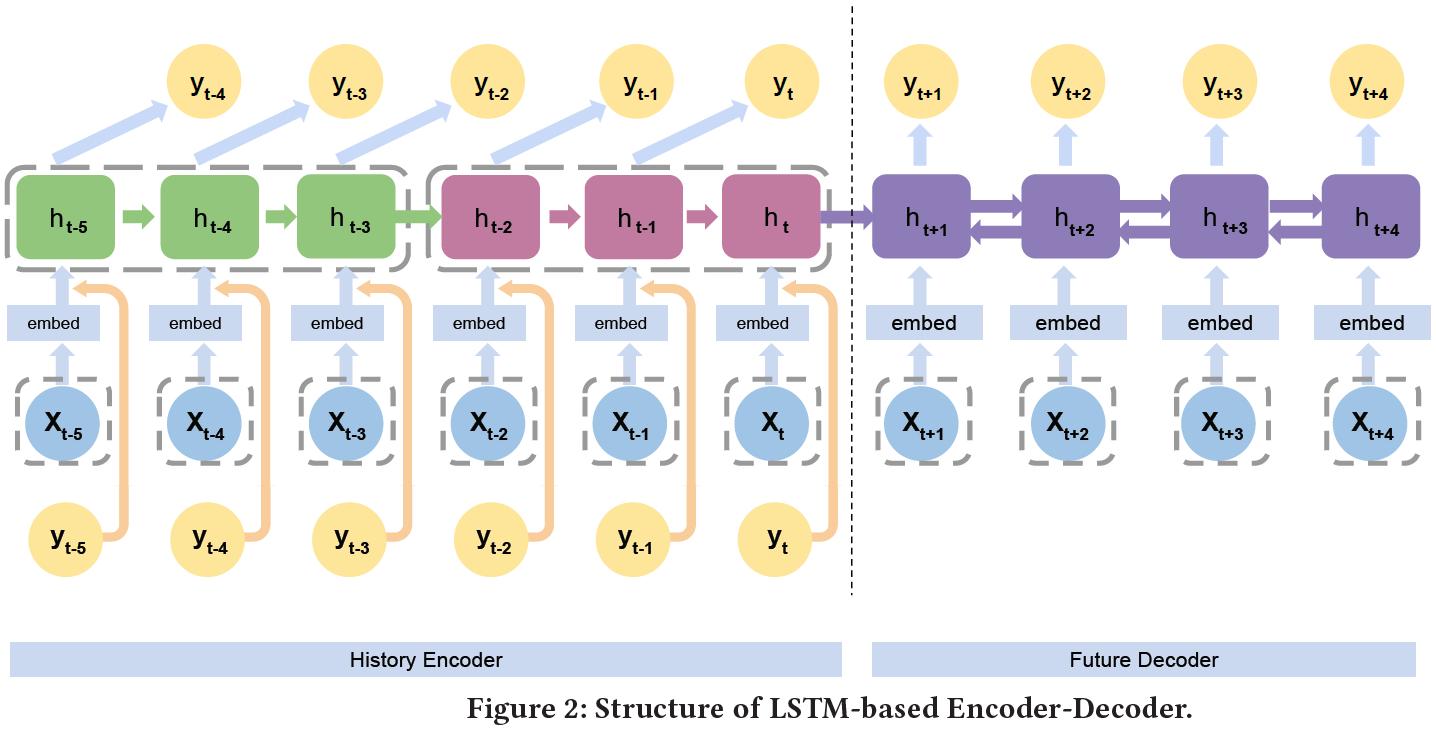
- 使用前T个时间段的销售数据,预测未来
T'个时间段的销售数据 - 传统的encoder-decoder架构使用rnn,本文的一个改进是在decoder中使用BiLSTM
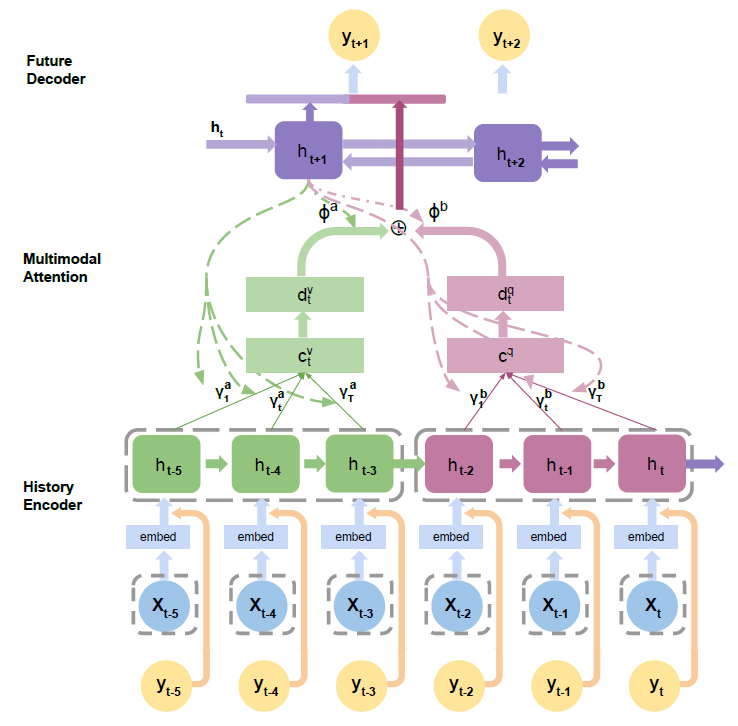
- 时间Attention:在decoder中第$t+1$个时间步生成的隐藏状态,对encoder中的隐藏状态进行attention,这里并不是对所有的历史时间段做attention,而是对历史$T_h$个时间段(可划分为M个period)做attention。例如上图中M=2,然后形成M个$c$向量,再经过FCN转换成$d$,然后再将M个$d$向量融合,这里使用attention融合,通过decoder的隐藏状态$h_{t+1}$对M个向量d做attention,将其融合成1个向量,然后再和$h_{t+1}$拼接,输入到FCN中预测第$t+1$个时间步的$y_{t+1}$,decoder中每个时间步都输出该时间步的预测值$y$。
- 本文的创新点就是:BILSTM和时间local Attention(只和局部时间段做Attention)
5. 总结
5.1. 网格—>图
图用2个矩阵表示:图信号矩阵和邻接矩阵。由网格构建图时,节点表示区域,图信号矩阵就是区域的特征。重点是怎么构建邻接矩阵。
- 《Spatiotemporal Multi-Graph Convolution Network for Ride-hailing Demand Forecasting》(AAAI2019)这篇文章构建了3个图:邻居图,POI功能相似图,交通连通图
- 《RiskOracle: A Minute-level Citywide Traffic Accident Forecasting Framework》(AAAI2020)有27*27个网格,但只有354个网格有道路,所以构建图中有354个节点。根据区域之间的道路静态信息和交通动态信息(flow和speed)来计算区域之间的相似性,构建邻接矩阵。由于动态交通信息随时间变化,所有每个时间段的相似性都不同,即每个时间段的邻接矩阵都不一样。
- 图信号矩阵:区域的flow,speed、和前一个时间段的差值
- 邻接矩阵:区域之间的相似性,在[0,1]之间
邻接矩阵的构造
邻接矩阵,非0即1,如果2个区域相邻,为1,否则为0
《Spatial-Temporal Synchronous Graph Convolutional Networks: A New Framework for Spatial-Temporal Network Data Forecasting》(AAAI2020)计算2个区域的相似性,如果2个区域的相似度大于某个阈值,设置为1,否则为0
《STG2Seq: Spatial-temporal Graph to Sequence Model for Multi-step Passenger Demand Forecasting》(2019IJCAI)- 计算2个区域的相似性,使用相似性作为邻接矩阵的值
《RiskOracle: A Minute-level Citywide Traffic Accident Forecasting Framework》(AAAI2020) - 计算2个节点的相似性,为每个节点选取相似性前k的节点作为其一阶邻居,其余节点的相似性设置为0,例如《Connecting the Dots: Multivariate Time Series Forecasting with Graph Neural Networks》2020KDD
5.2. 动态图
一般的图卷积的输入维度是(batch_size,N,C),即只有一个时间段,但如果输入的是动态图即(batch_size,T,N,C),该怎么办?
(batch_size,T,N,C)-->(batch_size,T*N,C)-->(T*N,batch_size,C),例如《Spatial-Temporal Synchronous Graph Convolutional Networks: A New Framework for Spatial-Temporal Network Data Forecasting》(AAAI2020),将时间T乘到节点N上,需要对邻接矩阵进行变换成(TN,TN)的形式,才可以和h相乘。不常用,除非对邻接矩阵A进行变换(batch_size,T,N,C)-->(batch_size,N,T*C),可以先经过一个FCN,将其转换为(batch_size,N,D),然后再输出到GCN中,也可以不经过FCN,直接输入到GCN中。较常用,例如:
《RiskOracle: A Minute-level Citywide Traffic Accident Forecasting Framework》(AAAI2020)
《STG2Seq: Spatial-temporal Graph to Sequence Model for Multi-step Passenger Demand Forecasting》(2019IJCAI)
5.3. 计算2个区域的相似性
用出租车需求量计算2个区域的相似性,用2个区域训练集中出租车需求量组成时间序列
- 使用DTW计算2个序列的相似性,2个时间序列越相似,说明2个区域越相似。例如:《Deep Multi-View Spatial-Temporal Network for Taxi Demand Prediction》(AAAI2018)
- 使用皮尔森度量函数Pearson Correlation Coefficient,
《Passenger Demand Forecasting with Multi-Task Convolutional Recurrent Neural Networks》(2019PAKDD)
《STG2Seq: Spatial-temporal Graph to Sequence Model for Multi-step Passenger Demand Forecasting》(2019IJCAI)
计算2个区域之间的相关性,使用区域间带有方向的traffic flow,如果2个区域之间的traffic flow越大,说明这2个区域越相关。但是《R evisiting Spatial-Temporal Similarity: A Deep Learning Framework for Traffic Prediction》(AAAI2019)说这种相关性也是相似性。我觉得有问题,例如工作区和住宅区,2个区域的traffic flow很大,有很强的相关性,但是相似性并不强。
- 根据POI计算2个区域的相似性
- 例如《Passenger Demand Forecasting with Multi-Task Convolutional Recurrent Neural Networks》(2019PAKDD)
- 《Spatiotemporal Multi-Graph Convolution Network for Ride-hailing Demand Forecasting》(2019AAAI)但是这篇文章没有提到使用什么函数来计算相似度
- 《RiskOracle: A Minute-level Citywide Traffic Accident Forecasting Framework》(AAAI2020)根据区域的道路静态信息和交通动态信息(flow和speed)计算2个区域的相似性。使用JS散度
5.4. POI
很多论文中都习惯将POI成为Semantic
- 《Deep Multi-View Spatial-Temporal Network for Taxi Demand Prediction》(AAAI2018)
- 《DeepSTN+: Context-aware Spatial-Temporal Neural Network for Crowd Flow Prediction in Metropolis》(AAAI2019)
5.5. 时间相关性
像dayOfWeek,monthOfYear等时间信息,在论文中称作time meta feature
- 使用RNN来捕获时间相关性
- 使用1D卷积来捕获时间相关性,或者使用1D空洞卷积,来捕获长期的时间相关性。或者参照Inception结构,使用不同大小的卷积核来捕获不同粒度的周期性,例如WaveNet,MTGNN
- 使用不同的模块捕获不同粒度的周期性,例如ST-ResNet,DeepSTN,ASTGCN
5.6. LSTM共T个隐藏状态整合
LSTM一共有T个时间步,将输出T个隐藏状态,怎么将其整合成1个,有3种方法:
- 只取最后一个时间步的隐藏状态,例如
《Deep Multi-View Spatial-Temporal Network for Taxi Demand Prediction》(AAAI2018) - 将T个时间步的隐藏状态拼接或平均或加和
- 将T个时间步的隐藏状态和被预测时间步的某个向量(e.g.外部因素)做Attention,对每个时间步赋予不同的权重,整合成1个向量。例如
《Revisiting Spatial-Temporal Similarity: A Deep Learning Framework for Traffic Prediction》(AAAI2019)
《When Will You Arrive? Estimating Travel Time Based on Deep Neural Networks》(AAAI20)
5.7. 外部因素嵌入
外部因素包括:天气,时间,holiday等信息,
- 外部因素中类别值(dayOfWeek,weather等)用one-hot表示,连续值(温度,风速)等用float表示,将这些外部因素拼接在一起,送入FCN中做嵌入。
例如《 Deep Spatio-Temporal Residual Networks for Citywide Crowd Flows Prediction(AAAI2017)》 - 外部因素中类别值(dayOfWeek,weather等)直接用数字表示,例如周一用0表示,周日用6表示。连续值(温度,风速)等用float表示,然后将每个类别值用对应的Embedding嵌入,然后再把嵌入的结果拼接
例如《When Will You Arrive? Estimating Travel Time Based on Deep Neural Networks(AAAI20)》Embedding相关知识参考Pytorhc之Embedding
5.8. mask
有时候mask是舍弃一些不想关注的值,比如预测车流量时,真实车流量小于5的值则舍弃,即不关注那些车流量小的值预测结果,只关注大约5的值的预测结果。一般在评价指标中mask
1 | def mask_mae_np(y_true,y_pred,region_mask,null_val=None): |
5.9. Max-min归一化
使用Max-Min将数据归一化到[0,1],但是也有论文归一化成[-1,1],如下所示:
1 | class MinMaxNormalization(object): |
【注意】对特征和y归一化有2种方式:
- 只对特征进行归一化,y不进行归一化,模型预测的结果和真实y是同一量纲,模型的loss会偏大,计算评价指标时,不需要反归一化
- 对特征和y都归一化,y归一化到[0,1]之间,在计算loss时,不需要反归一化,loss相对方法1会偏小,在计算评价指标时,需要对真实y和预测y进行反归一化,再计算MAE等指标
关于上面是否需要对y进行归一化。如果模型收敛(loss一直在下降),可以不对y进行归一化。如果模型不收敛(数值过大),则需要对y进行归一化。

如果对y进行归一化,loss初始值很小,模型训练时很快就会收敛loss不再下降。不对y归一化,loss初始值很大,在训练过程中,训练很多轮loss才开始收敛,可能还会造成训练过程不稳定,loss上下震荡。

