1. Spark简介
1.1. Spark是什么
Spark是基于内存计算的大数据局并行计算框架。Spark基于内存计算,提高了数据处理的速度,同时具有高容错性和高伸缩性,允许用户将Spark部署在廉价的硬件之上,形成集群。
Spark和 Hadoop Map Reduce的优势:
- 中间结果输出在内存中
MapReduce将中间结果写入到磁盘中。而Spark在计算过程抽象成有向无环图DAG,执行的时候使用内存来存储中间结果。 - 数据格式
Spark使用弹性分布式数据集RDD,来进行数据的存储。在RDD上可以对数据进行分区,将数据分布在不同节点上。 - 任务调度
MapReduce是为了运行数小时的批量作业而设计的,在某些情况下,延迟非常高。
Spark采用事件驱动的类库AKKA来启动任务,通过线程池来避免线程启动和切换的开销。
1.2. Spark架构
Spark架构采用了分布式计算中的Master-Slave模型。将具有Master进程的节点视为Master,将含有Worker进程的节点视为Slave。
在搭建集群的时候已经分配好Master和Worker了。
- Master作为整个集群的控制器,负责整个集群的正常运行。
在运行Spakr程序时,分为Driver和Worker。
- Client用户端提交应用
- Driver是提交程序的那个节点,即运行
main()函数的那个节点,负责作业的调度。 - Worker是计算节点,用来接收主节点命令,执行任务。
- Executor:执行器,在worker节点上执行任务的组件。
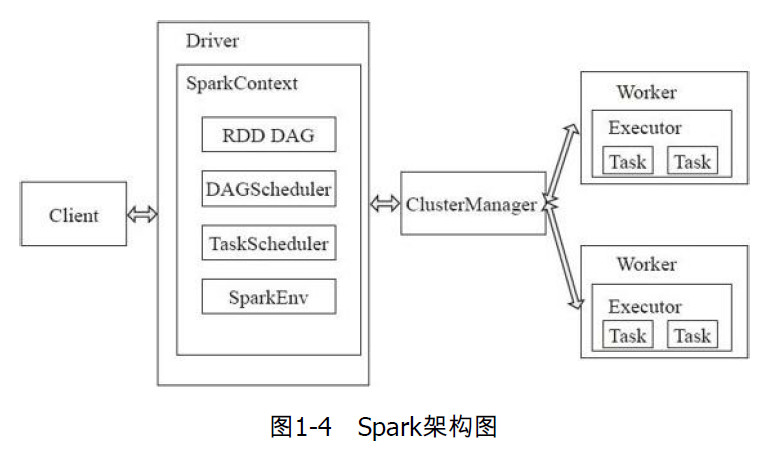
Spark的执行流程:
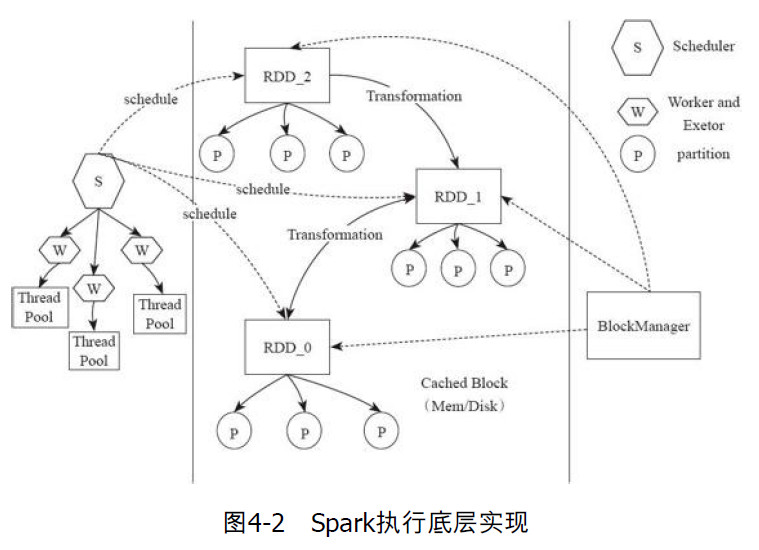
Client提交应用,Mater会找到一个Worker来启动Driver,Driver向Master申请资源,然后将RDD的一系列操作转换为DAG,然后调度器将DAG中的一系列操作切分成不同的stage,然后将这些stage分发给Executor执行。
2. Spark计算模型
2.1. RDD介绍
Spark的核心数据结构:弹性分布式数据集(resilient distributed dataset)RDD,通过RDD的依赖关系形成有向无环图。
RDD的2种创建方式:
- 从HDFS,HBase,Hive中读取数据创建
- 从父RDD转换得到新的RDD
2.2. RDD的2种操作算子
转换算法Transformation
转换算子不是立即执行,等到Action之后才会被触发。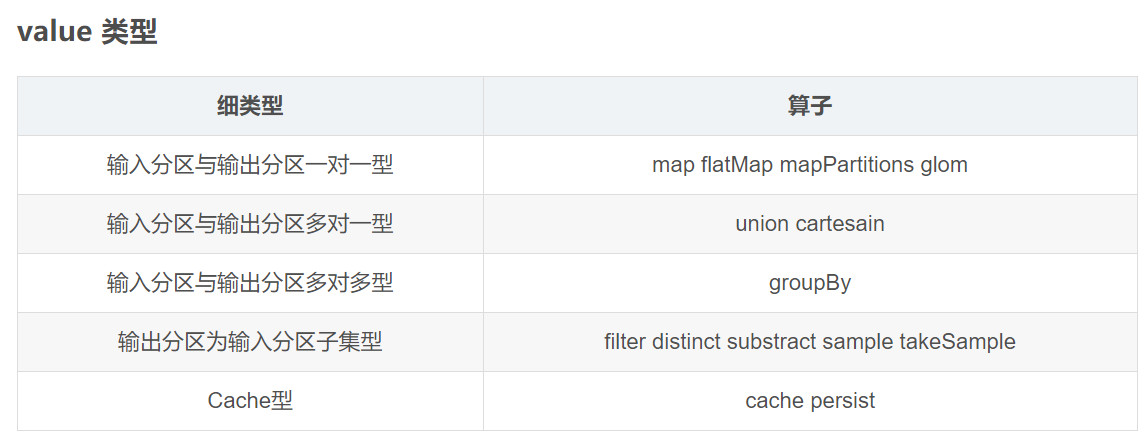
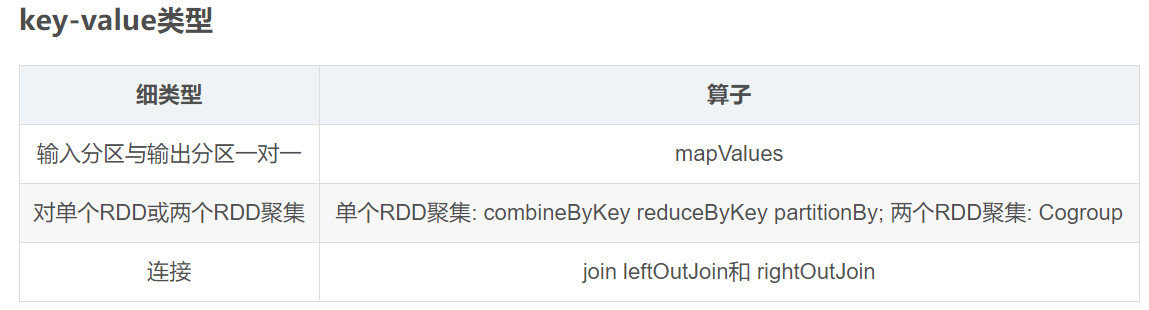
行动算子Action
Action算子触发Spark提交作业。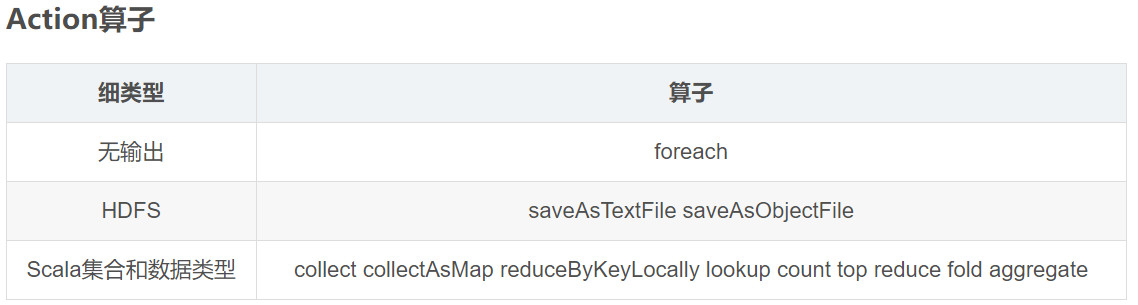
一个RDD有多个分区,每个分区上的数据存储在不同的节点上。
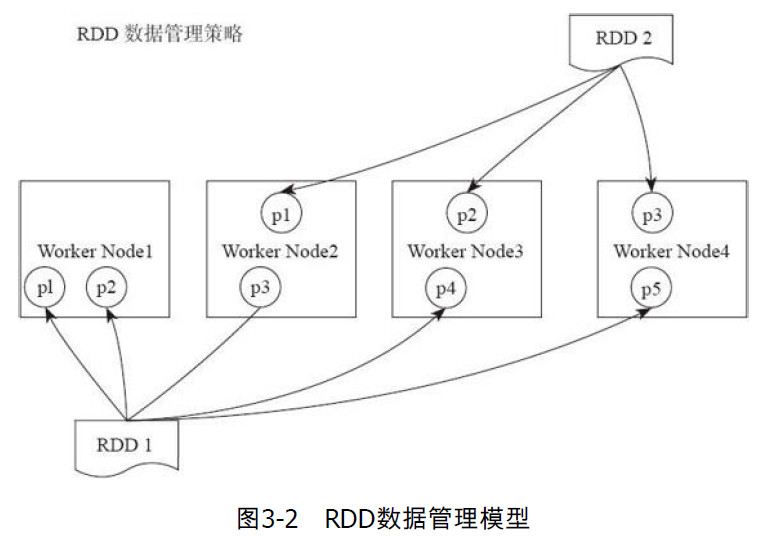
- Transform算子和Action算子的区别
转换算子不触发提交作业,只是完成作业中间过程处理。转换算子的操作是延迟执行的,必须等到action算子才会真正触发。Action算子触发SparkContext来提交job作业,并将数据输出到Spark系统中。 reduceByKey和groupByKey的区别
会在数据移动之前,进行一次reduce操作,然后再进行数据传输,但是groupByKey并不会提前进行reduce,导致集群中节点间开销很大,传输延时。
在对大数据进行复杂计算时,reduceByKey优先groupByKey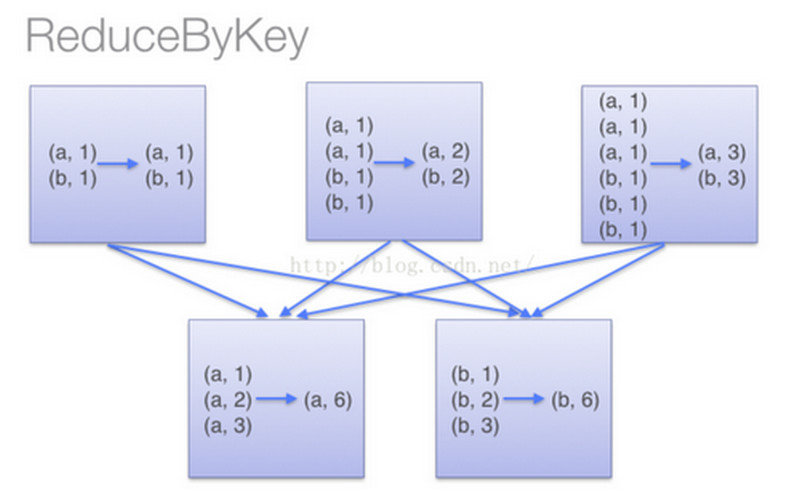
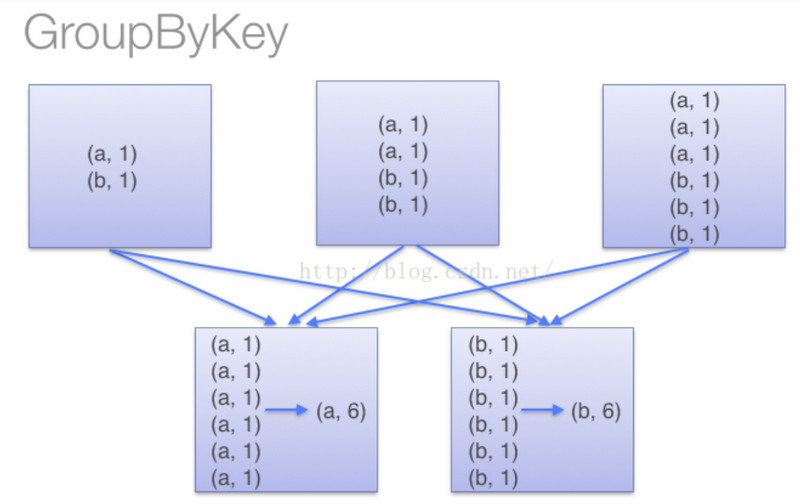
- groupByKey对RDD中所有数据做shuffle,根据不同的key映射到不同partition中再进行aggregate
- reduceByKey先对每个partition中的数据根据不同的key进行聚合,然后再将结果shuffle,完成不同partition之间的聚合,这个aggregateByKey一样
- aggregateByKey相对reduceByKey还多了一些操作,aggregateByKey允许返回不同类型的结果,例如输入(1,2)和(1,4),可以输出(1,”six”),而reduceByKey只能输出相同类型的值
2.3. OOM或数据倾斜
3. Spark工作机制详解
Spark的执行流程:
Spark Application的运行环境:创建SparkConf对象
- 设置Application Name
- 设置运行模式及资源需求
- 创建SparkContext对象
- SparkContext向资源管理器申请运行Executor资源
- SparkContext将程序发给Executor
- SparkContext构建DAG图,将DAG图分解成stage,将task set发送给task scheduler,最后由task scheduler将task发送给Executor运行
- Task在Executor上运行,运行完释放所有的资源
- 基于Spark的上下文创建一个RDD,对RDD进行处理
- 使用Action算子触发转换算子运行
- 关闭spark上下文对象sparkContext
Client提交应用,Mater会找到一个Worker来启动Driver,Driver向Master申请资源,然后将RDD的一系列操作转换为DAG,然后调度器将DAG中的一系列操作切分成不同的stage,然后将这些stage分发给Executor执行。Executor会创建线程池,executor将需要执行的任务通过线程池并发执行。
3.1. Spark中术语概念
Spark应用Application是用户提交的应用程序。执行模式有Local,Standalone,YARN。
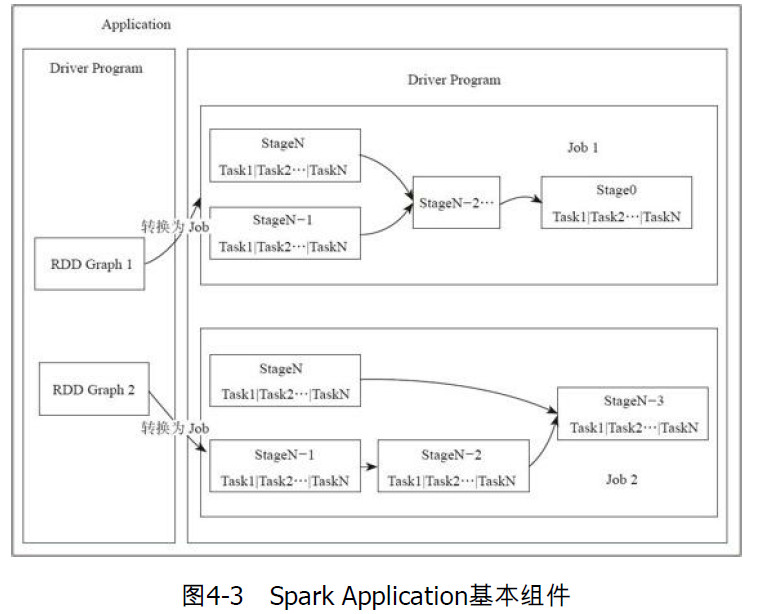
- Application:用户自定义的Spark程序,用户提交后,Spark为App分配资源
- Driver Program:运行App的main函数,并创建SparkContext
- RDD Graph:RDD是Spark核心结构,RDD所有算子操作组成一个有向无环图DAG
- Job:一个RDD Graph触发的作业,一般由Action触发,在SparkContext通过runJob方法向Spark提交Job
- Stage:每个Job会根据RDD的宽依赖关系被切分成很多stage,每个stage中包含一组相同的task,这一组Task也叫做TaskSet
- Task:一个分区对应一个Task,Task执行RDD中的算子,Task被封装好后放在Executor中的线程池中执行。
3.2. Spark资源分配
Spark有多种运行模型:Local,Standalone模型,YARN模式。
下面根据不同的运行模式介绍配置调度:
- Stansalone模式
默认情况下,用户以standalone模式提交应用使用FIFO的顺序进行调度。每个应用会独占所有可用节点的资源。用户可以通过配置参数spark.cores.max来决定一个应用可以在整个集群申请的CPU core数,而不是一个节点的核数。如果没有设置这个值,则使用默认参数。 - YARN模式
当Spark在YARN平台上提交时,用户可以在YARN的客户端通过配置--num-executors:应用分到的executor个数--executor-memory:每个executor的内存大小--executor-cores:每个executor的cpu核数
这样可以限制用户提交的应用不会占用过多的资源,让不同用户可以共享整个集群资源。
3.3. Spark中Job的调度
在Spark应用程序内部,用户通过不同线程提交的Job可以并行运行。这里所说的Job是action算子触发的一个job。
Spark的调度器是线程安全的,有以下3种调度方法:默认是FIFO
- FIFO
在默认情况下,Spark使用FIFO方式调度Job执行。有多个Job时,第一个Job优先获取所有的资源,第一个job还行结束后,才开始执行第二个job。但是如果第一个Job运行很长时间的话,第二个job就需要等很久。 - FAIR
Spark在多个Job进行轮询来分配资源,所有的Job获取资源的优先级是一样的。当一个长任务在执行时,短任务也可以分配到资源。这种调度适合多用户的场景。 - 配置调度池
用户可以通过配置文件自定义调度池的属性。通过设置权重,控制整个集群的资源分配上。如果一个调度池的权重为3,则该调度池将会比权重为1的调度池优先获取资源。
4. Spark I/O机制
Spark的数据分布在多个节点上,不仅要考虑本机的I/O开销,还要考虑不同节点之间的传输开销。
4.1. 序列化
序列化:将对象转换成字节流。将链表存储的非连续空间的数据转换成连续空间存储的数据,这样就可以将数据进行流传输或块传输。
在Spark中,传输的数据都需要进行序列化,序列化后的数据影响数据传输速度,影响集群计算效率。序列化方式有Java序列化库,Kyro序列化库,自定义序列化方法。
5. 容错机制
分布式数据集的容错性有2种方式:
- 数据检查点,成本高
- 记录数据的更新,Spark使用该方式。但是如果更新粒度太细太多,更新成本也很高,所以RDD只支持粗粒度转换,即在大量记录上执行的单个操作。将创建RDD的一系列Lineage(血统)记录下来,以便恢复丢失的分区。Lineage本质上很类似数据库中重做日志(redo log),只不过这个重做日志粒度很大。
RDD的Lineage记录的转换算子行为,当这个RDD的部分分区数据丢失时,它可以通过Lineage重新运算和恢复丢失的数据分区。
2种依赖
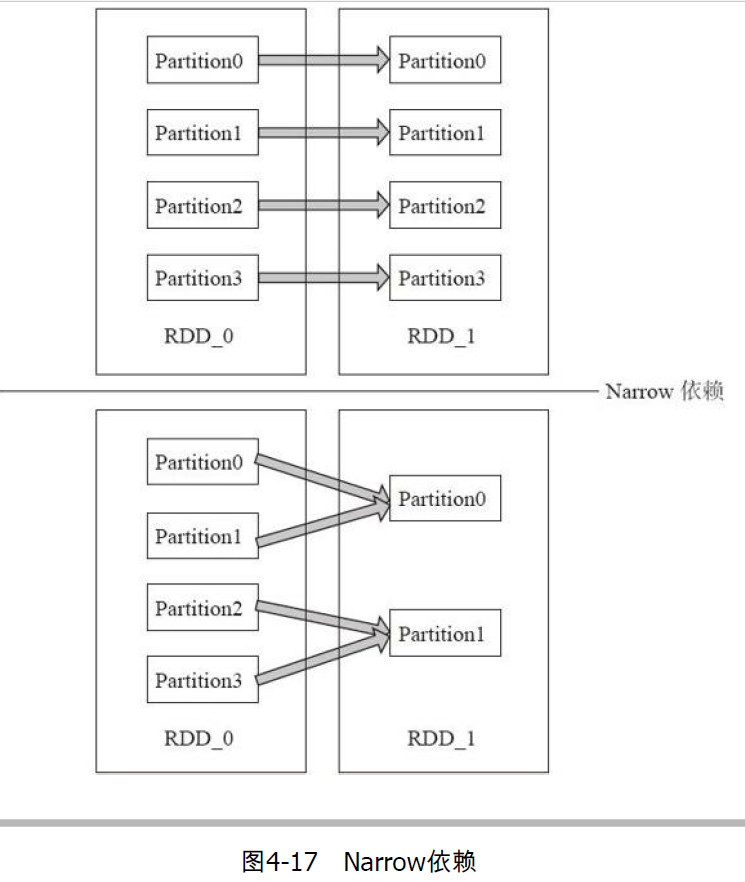
RDD在Lineage依赖方面有2种:窄依赖和宽依赖,用来解决数据容错的高效性。
窄依赖:一个父分区对应一个子分区,即父RDD的分区对应于一个子RDD的一个分区。
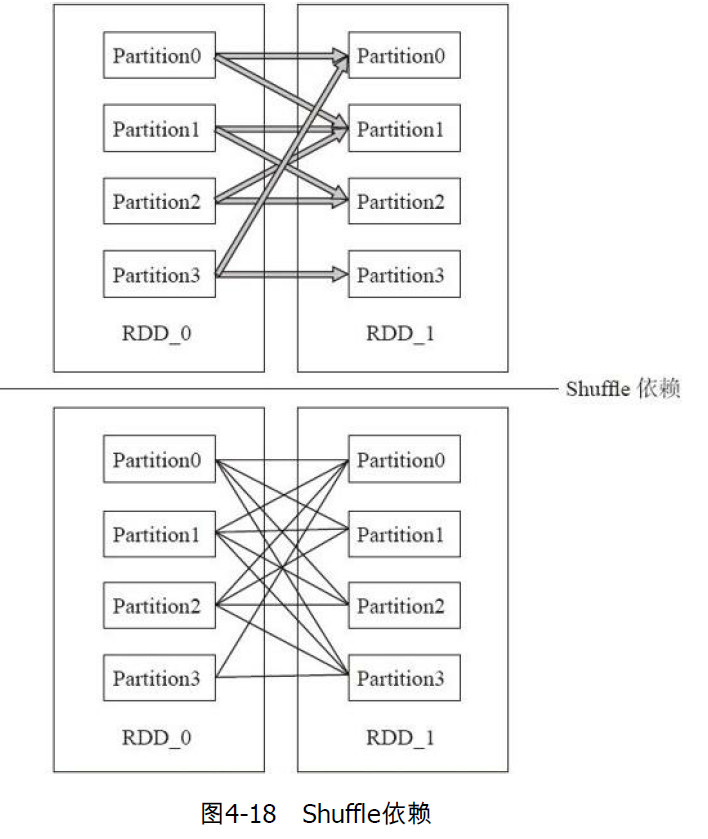
宽依赖:一个父分区对应多个子分区子,即父RDD的分区对应于一个子RDD的多个分区。
5.1. CheckPoint机制
RDD需要加检查点:
- DAG中的Lineage过长,如果重算,开销太大
- 在宽依赖上做CheckPoint获得的收益更大
可以通过SparkContext.setCheckPointDir()设置检查点数据的存储路径,进而将数据存储备份,然后Spark删除已经做检查点的RDD的祖先RDD依赖。
检查点本质是通过将RDD写入Disk做检查点,为了通过Lineage做容错的辅助,lineage过长会导致容错成本过高。在检查点之后如果丢失分区,则从做检查点的RDD开始重做Lineage。
6. Spark Streaming
Spark Streaming是一个批处理的流式计算框架,适合处理实时数据与历史数据混合处理的场景,并保证容错性。Spark Streaming是一个实时计算框架
Spark Streaming将数据流以时间片为单位分割成RDD,然后对每个RDD都会生成一个spark job进行处理。
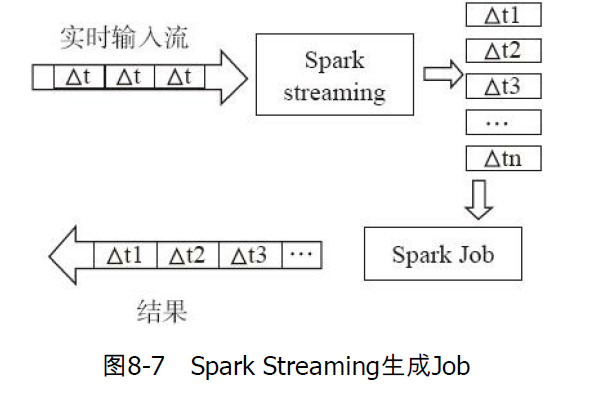
在spark streaming程序中,需要注意批量窗口的大小。如果窗口过大,可能处理的速度低于数据进来的速度,导致数据堆积,阻塞。

