最近实验室安装了openpai平台,可以在上面提交程序运行。下面记录怎么使用OpenPai提交NNI程序,进行调参。
1. 使用步骤
1.1. 编写程序
先在VSCode中完成代码,先在VSCode的虚拟环境中运行,如果可以运行,再使用OpemPai运行。
注:在OpenPai上运行程序,不需要指定使用哪块GPU,因为OpenPai会自动申请需要使用的GPU。即以下代码注释掉
1 | # os.environ["CUDA_VISIBLE_DEVICES"] = "1,2,3" |
1.2. 准备镜像
准备一个包含hdfs的镜像,将需要用的镜像push到实验室服务器的仓库。
下面是我本人的镜像:
- 运行环境mxnet
lin-ai-27:5000/wangbeibei/mxnet:cu100_hdfs - 运行环境是pytorch
172.31.246.45:5000/dlspree:hdfs_pyg
1.3. 编写NNI的yml配置文件
使用pip install nni==1.2安装1.2版本的nni,如果不指定版本,默认安装最新版,目前最新是1.3,1.3版本的nni其yml配置文件和1.2有所区别
OpenPai模式
1.3版本的nni的yml配置文件和1.2有所不同,最新版本的配置文件,其中多了nniManagerNFSMountPath,containerNFSMountPath,paiStoragePlugin三个必填的键。
下面使用的是1.2版本的nni配置文件
1 | authorName: wangbeibei |
这里资源的配置都是针对一个trail的,memoryMB也是针对一个trail的。
注意: pai 模式下,NNIManager 会启动 RESTful 服务,监听端口为 NNI 网页服务器的端口加1。 例如,如果网页端口为8080,那么 RESTful 服务器会监听在 8081端口,来接收运行在 Kubernetes 中的 Trial 作业的指标。 因此,需要在防火墙中启用端口 8081 的 TCP 协议,以允许传入流量。
通常在服务器中8080端口无法使用,我们需要在启动NNI管理器时手动通过 —port 指定端口。
1.4. 安装NNI
由于NNI并不依赖于任何环境,因此当我们使用OpenPAI提交NNI任务时,为了方便(需要解决ip和端口映射问题),不需要在docker中启动NNI,直接在服务器环境下安装NNI,启动即可。
使用pip install nni==1.2安装nni
1.5. 启动NNI
使用nnictl create --port 6688 --config xxx.yml来启动一个Experiment,如果端口被占用,换别的端口
1.6. NNI浏览器查看
在浏览器中输入服务器ip:6688
1.7. 在浏览器中查看OpenPai
在浏览器中登录OpenPai,可以查看启动的trail,在代码中的print输出的内容在stdout中查看。
注:有时候print语句输出的内容在stdout显示不出来,添加flush=True就可以了
1 | print("************进入main函数",flush=True) |
1.8. 关闭NNI
直接在服务器中使用nnictl stop即可关闭nni的Experiment
2020.3.5更新
内存指标解读
1 | trial: |
【gpuNum】:设置为2,表示该程序使用2张GPU,即该程序独占2张GPU卡,独占2张卡的显存和计算力
【cpuNum】:设置为3,占用3块CPU来计算
【memoryMB】:设置为20000MB,表示该程序总共占2000MB的内存,在openpai上内存是共享的,显存是独享的。
当我设置如上资源来跑程序时,可以看到程序的资源占用情况如下所示: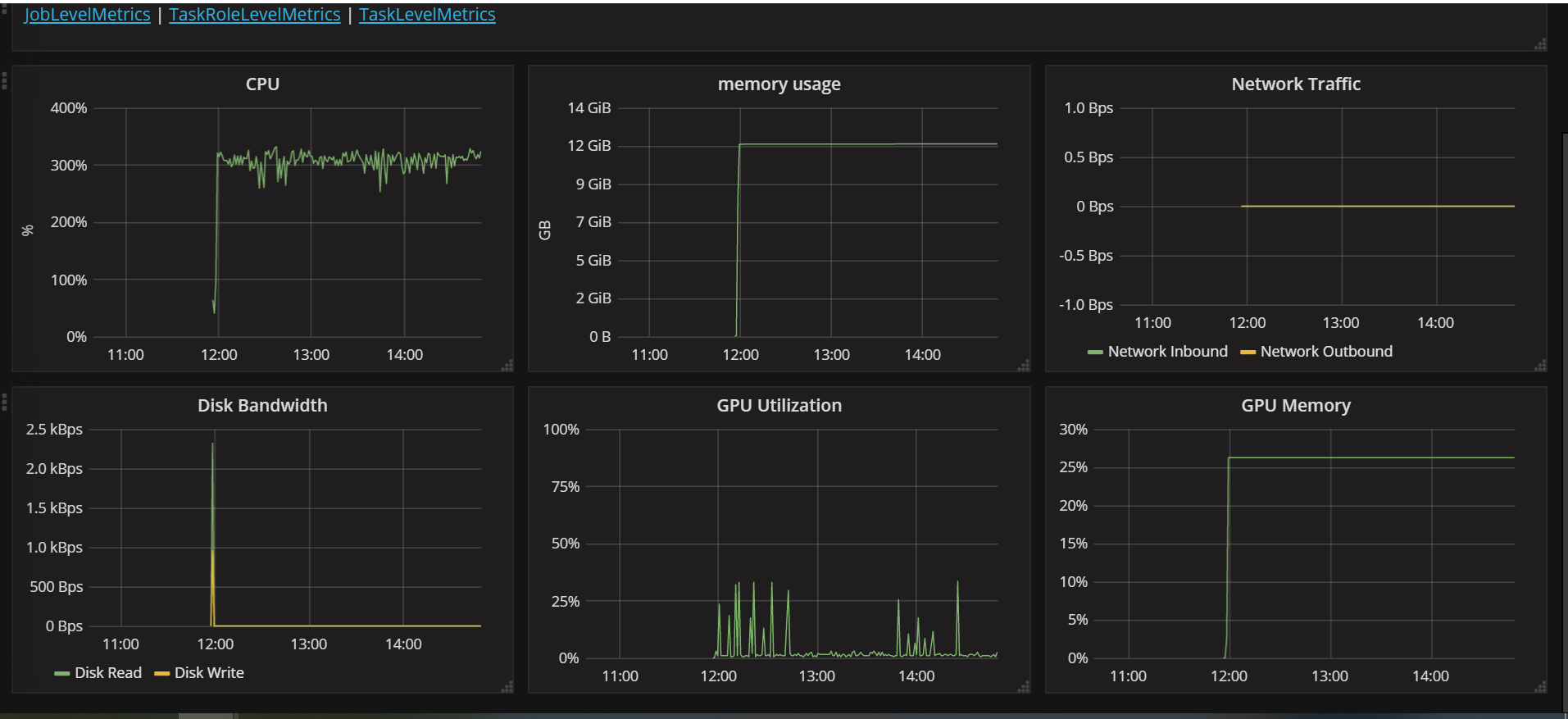
【指标解读】
上面从左到右一共有6张图,我们只关注CPU,memory usage,GPU Utilization,GPU Memory这4张图。
- CPU:CPU的占用率稳定在300%,说明程序分配的3张CPU卡都用来做计算,CPU一直是满载状况,这时候可以适当增加cpuNum的个数
- memory usage:内存占用率稳定在12G,我们分配给该程序的资源是20G,分配的有点多,可以适当减少些。内存分配的资源也不是越多越好,因为openpai在跑程序时,当有足够的GPU但是却没有足够的内存,程序依然不能运行,会一直处于waiting状态
- GPU Utilization和GPU Memory:GPU的占用率稳定在25%,给该程序分配了2张GPU卡,一张卡有11G显存,但是程序只占了25%,也就是大约3G,2张卡对该程序有点多,可以改为1张卡

