平时主要使用mxnet和pytorch,下面记录下在代码中怎么使用GPU
1. mxnet
1.1. 单GPU
1 | import mxnet as mx |
1.2. 多GPU
多GPU计算
Run MXNet on Multiple CPU/GPUs with Data Parallelism
1 | import mxnet as mx |
2. pytorch
2.1. 单GPU
1 | import os |
2.2. 多GPU
1 | os.environ["CUDA_VISIBLE_DEVICES"] = "1,2,3" |
DataParallel自动分割数据,并发送到多个GPU上,每个GPU上完成前向传播, DataParallel收集每个GPU上的结果。
2020.2.11更新
3. mxnet和pytorch区别
在写程序时,主要用到mxnet和pytorch框架,这里针对2者在代码上的不同做个总结,下面的不同都是我自己在写程序遇到的,仅仅是一部分,仅供参考。
3.1. NDArray和Tensor
3.1.1. 和numpy转换
mxnet
- Numpy—>NDArray
nd.array(a) - NDArray—>Numpy
D.asnumpy()
- Numpy—>NDArray
pytorch
- Numpy—>Tensor
D = torch.from_numpy(a) - Tensor—>Numpy
a = D.numpy()
- Numpy—>Tensor
3.1.2. 转换为标量
- mxnet
asscalar()将函数结果转换成Python的标量X.sum().asscalar() - pytorch
item()将函数结果转换成Python的标量X.sum().item()
3.1.3. 改变数据形状
mxnet
reshape()
1
2X = x.reshape((3, 4))
X = x.reshape((-1, 4))
pytorch
view()
1
2y = x.view(15)
z = x.view(-1, 5) # -1所指的维度可以根据其他维度的值推出来
3.1.4. 数据转到GPU上
mxnet
使用as_in_context()1
2
3
4#在gpu上创建NDArray
B = nd.random.uniform(shape=(2, 3), ctx=mx.gpu(1))
z = x.as_in_context(mx.gpu())pytorch
使用to()函数1
2
3
4if torch.cuda.is_available():
device = torch.device("cuda") # GPU
y = torch.ones_like(x, device=device) # 直接创建一个在GPU上的Tensor
x = x.to(device)
3.2. loss计算
- maxnet
1 | loss = L2Loss() |
注1:在使用
y.backward()自动求梯度时,如果y不是一个标量,mxnet将默认先对y中元素求和得到新的变量,在求该变量关于x的梯度注2:mxnet的
L2Loss()返回值维度(batch_size,),即batch中每个样本的loss。需要在step()中传入batch_size参数
- pytorch
1 | loss = MSELoss() |
注1:在
y.backward()时,如果y是标量,则backward()不需要传入任何参数,否则,需要传入与y同形的Tensor注2:grad在反向传播过程中是累加的,这意味着每一个batch运行反向传播,梯度都会累加之前batch的梯度,所以一般在反向传播传播之前需要把梯度清零。
注3:pytorch的
MSELoss()返回值维度(1,),Tensor中只有1个数,也称作scalar:零维的张量。因为MSELoss()返回值是batch中所有样本loss的平均值。所以在step()中不需要传入batch_size参数
3.3. RNN输入维度
这里只讨论单向RNN
- mxnet
- 输入数据维度默认
(T,batch_size,input_size) - 初始化state维度
(num_layers,batch_size,hidden_size),可以不输入,则默认用全0初始化 - output输出数据维度
(T,batch_size,hidden_size),表示最后一层所有时间步的隐藏状态 - out_state:输出维度和state一样,都是
(num_layers,batch_size,hidden_size),表示所有层最后一个时间步的隐藏状态,如果state不输入,则out_state不会被返回 - 如果想让输入维度是(B,T,C),则指定参数
layout=NTC
- 输入数据维度默认
- pytorch
- 输入数据维度默认
(T,batch_size,input_size) - 初始化state维度
(num_layers,batch_size,hidden_size),可以不输入,则默认用全0初始化 - output输出数据维度
(T,batch_size,hidden_size),表示最后一层所有时间步的隐藏状态 - out_state:输出维度和state一样,都是
(num_layers,batch_size,hidden_size),表示所有层最后一个时间步的隐藏状态,如果state不输入,则out_state不会被返回 - 如果想让输入维度是(B,T,C),则指定参数
batch_first=True
- 输入数据维度默认
注意:Mxnet和Pytorch的唯一区域是:mxnet的state不指定,out_state就不会输出,pytorch不管state是否指定,out_state都会输出
3.4. Transformer输入维度
mxnet
Mxnet中有一个NLP相关的包gluonnlp,里面封装了Transformer,这里只讨论TransformerEncoder- 输入维度为
(batch_size, length, C_in) - 输出维度为
(batch_size, length, C_out)
- 输入维度为
pytorch
Pytorch中也封装了Transformer,TransformerEncoder- 输入维度为
(length, batch_size, Embedding) - 输出维度为
(length, batch_size, Embedding)nn.TransformerEncoderLayer - 输入维度为
(length, batch_size, Embedding) - 输出维度为
(length, batch_size, Embedding)
- 输入维度为
【注意】Mxnet版的Tranformer中Dropout的p默认为0,Pytorch版的Transformer中Dropout的p默认为0.1
3.5. 多GPU运行
mxnet
mxnet.gluon.utils.split_and_load(data, ctx_list, batch_axis=0, even_split=True)
split_and_load()将一个batch中的数据划分为多个小batch到多个GPU上。
【注意】默认batch_axis=0,也就是默认划分axis=0的维度,如果batch不在第0维,例如RNN中,输入的维度默认为TNC,batch在第1维,那就需要在split_and_load中指定batch_axis=1split_and_load()返回值是list,里面每个元素是NDArray,经过split_and_load()对一个batch数据进行分割,得到的X,y的shape变成(batch_size/n,*),经过模型输出得到的predicted维度也是(batch_size/n,*)
计算得到的loss也是list类型,里面存储一个batch在多个GPU上计算的loss,对每个loss分别反向传播求梯度,然后再使用step()更新参数。1
2
3
4
5
6
7
8
9
10
11
12for epoch in range(100):
for X,y in train_iter:
gpu_Xs = gutils.split_and_load(X,ctx)
gpu_ys = gutils.split_and_load(y,ctx)
with autograd.record():
#ls是list,里面有n个NDArray,n是GPU的个数
ls = [loss(net(gpu_X),gpu_y for gpu_X,gpu_y in zip(gpu_Xs,gpu_ys)
for l in ls:
l.backward()
train.step(batch_size)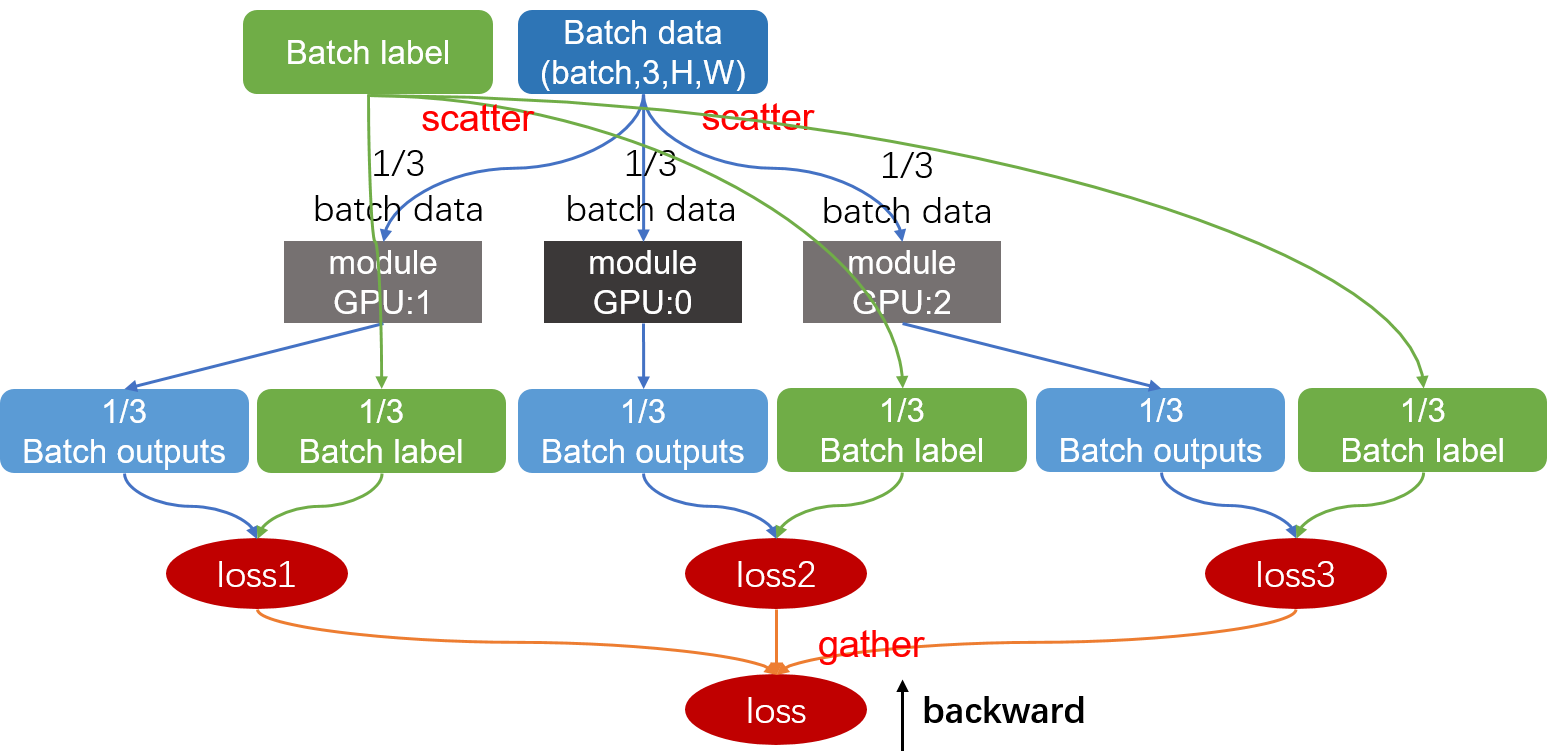
pytorch
Pytorch学习CLASS torch.nn.DataParallel(module, device_ids=None, output_device=None, dim=0)
DataParallel自动将batch进行划分,划分维度默认dim=0,如果batch在其他维度,通过dim指定
pytorch使用DataParallel()来进行数据并行,不需要手动将数据划分到多个GPU上,即train_feature的维度是(batch_size,*),经过模型输出的predicted的维度也是(batch_size,*),这一点和mxnet不同1
2
3
4
5
6
7
8
9
10
11
12
13
14
15#使用多GPU的关键代码
if torch.cuda.device_count() > 1:
transformer_model = nn.DataParallel(transformer_model)#默认全部GPU
transformer_model.to(device0)
for epoch in range(1,training_epoch+1):
for train_feature,train_label in train_loader:
train_feature = train_feature.to(device0)
train_label = train_label.to(device0)
#train_label:(tabch_size,*)
predicted = transformer_model(train_feature)
l = loss(predicted,train_label)#l的shape:(1,)
trainer.zero_grad()
l.backward()
trainer.step()
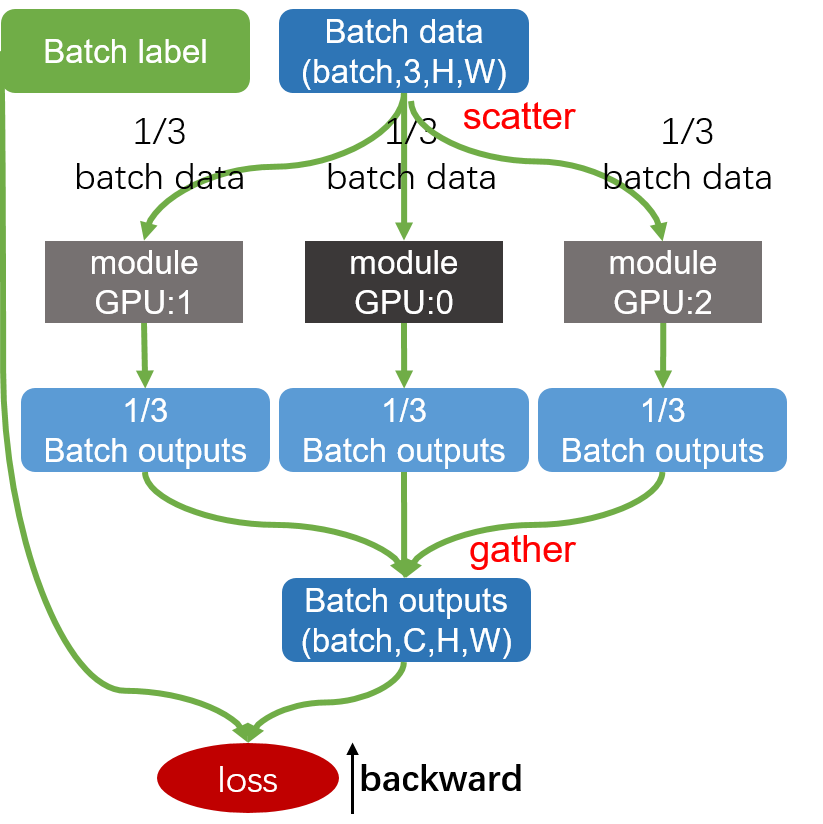
从这2个图中可以看出Mxnet和Pytorch多GPU运行的区别。
Mxnet将batch数据和label都分配到每个GPU上,然后在每个GPU上都计算loss,然后再把loss聚合。
Pytorch只把batch数据分配到每个GPU上,在每个GPU上得到输出,gather到主设备上,然后再和label计算loss。
Mxnet会比Pytorch会一些,因为Mxnet的loss是在不同的GPU上计算的,但Pytorch的写法更简单。
为了解决Pytorch在一张卡上计算loss的问题,有人提出了解决方案,参考基于PyTorch使用大batch训练神经网络和pytorch 多GPU训练总结(DataParallel的使用)
3.6. 将网络加入list中
mxnet
1
2
3
4
5
6self.submodules = []
with self.name_scope():
for backbones in all_backbones:
self.submodules.append(
ASTGCN_submodule(num_for_prediction, backbones))
self.register_child(self.submodules[-1])pytorch
Pytorch中nn.Module, nn.ModuleList, nn.Sequential,统称为容器,因为我们可以添加模块module到它们中。但有时候容易混淆,我们主要讨论nn.ModuleList, nn.Sequential的使用。【nn.ModuleList】
PyTorch 中的 ModuleList 和 Sequential: 区别和使用场景
Pytorch使用 nn.ModuleList() 和nn.Sequential()编写神经网络模型
ModuleList是一个类,可以将Module任意子类(Conv2d,Linear等)加入到list中,方法和Python自带的list一样,使用append或extend等操作。但不同于一般的list,加入到ModuleList里的module会自动注册到整个网络上,同时module的参数也会自动添加到整个网络中。
1 | class MyModel(nn.Module): |
3.7. 固定随机种子
mxnet版本
1
2
3
4seed = 2020
mx.random.seed(seed)
np.random.seed(seed)
random.seed(seed)pytorch版本
1
2
3
4
5
6seed = 2020
torch.manual_seed(seed) # cpu
torch.cuda.manual_seed(seed) #gpu
torch.backends.cudnn.deterministic=True#cudn,cpu/gpu结果一致
np.random.seed(seed)#numpy
random.seed(seed)#ramdom
3.8. 访问模型参数
mxnet
1
2for name,param in gru.collect_params().items():
print(name,':',parameters.size())pytorch
1
2
3
4
5for name,parameters in net.named_parameters():
print(name,':',parameters.size())
for parameters in net.parameters():
print(parameters)

