NN是微软官方出的一个自动调参的第三方库。非常好用。但是用起来还是有一些需要注意的地方。这里记录一下。
1. 术语
主要有2个术语experiment和trial。
experiment:如果需要调整LSTM的超参数,则需要指定每个超参数的可选项,然后运行程序,让nni自动调参。运行的这个调参程序就是experiment。
trial:上面运行的程序中,有很多的参数组合,每一个超参数组合是trial。
每一个experiment有一个ID,experiment中的每一个trial也有一个ID。在网页中可以看到
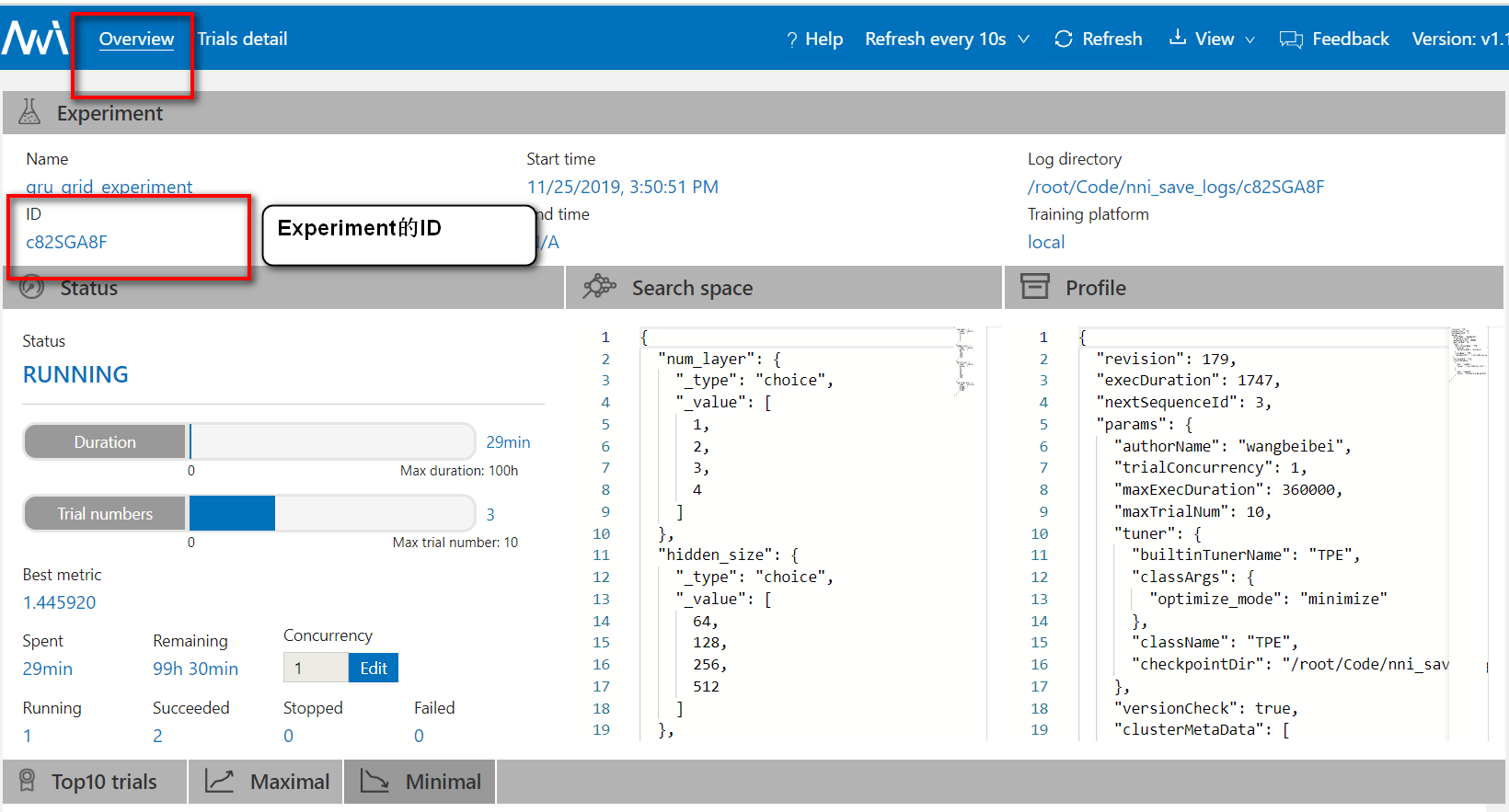
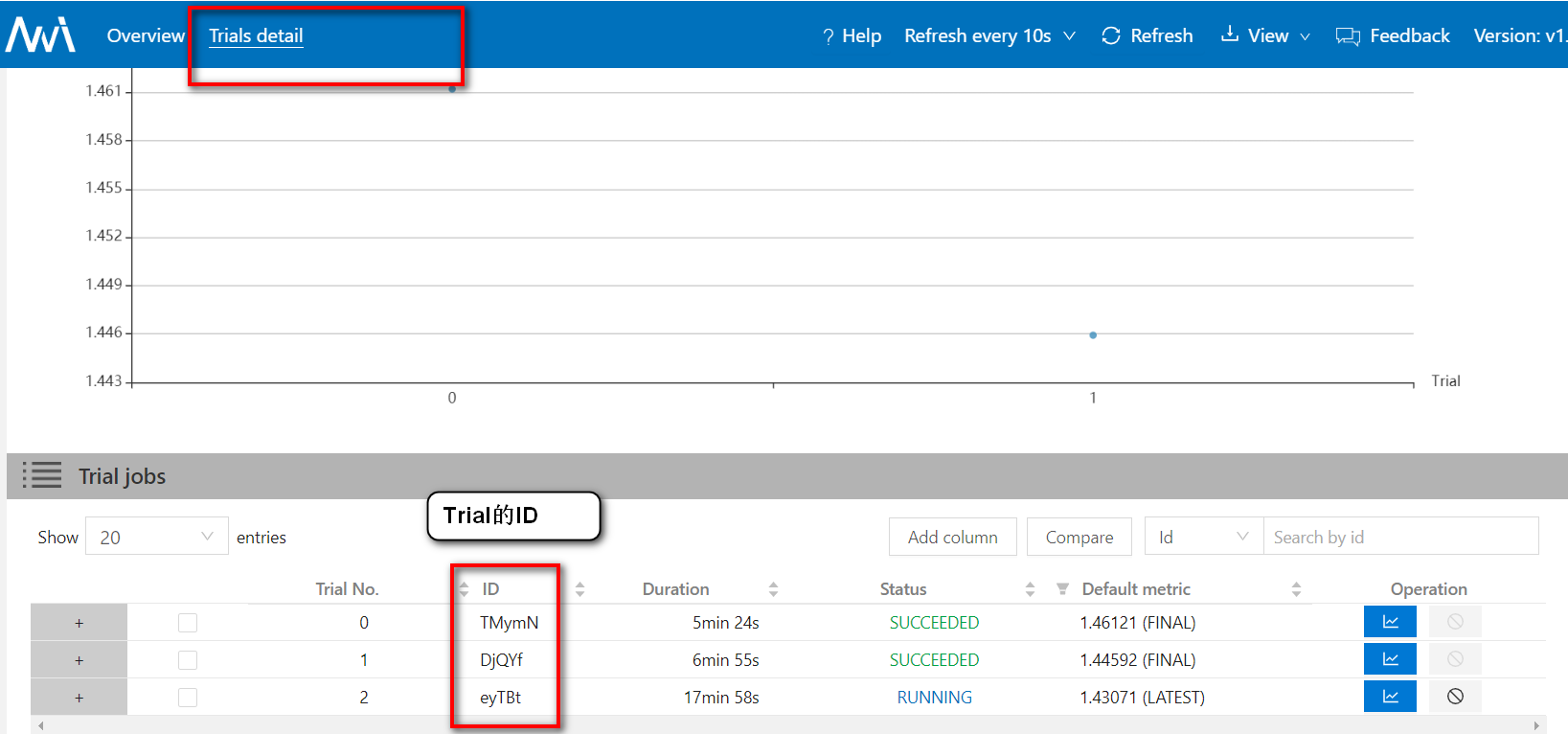
1.1. 使用步骤
创建搜索空间json文件
这里定义需要调整的超参数1
2
3
4
5
6{
"num_layer":{"_type":"choice","_value":[1,2,3,4]},
"hidden_size":{"_type":"choice","_value":[64,128,256,512]},
"batch_size": {"_type":"choice", "_value": [8, 16, 32,64,128,256]},
"learning_rate":{"_type":"uniform","_value":[0.0001,0.001]}
}首先在程序中import nni
1
2
3
4
5
6
7
8
9
10
11
12import nni
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "2"#单GPU
for epoch in range(1,train_epoch):
每一个batch,在测试集上训练,并反向传播
每一个epoch,计算验证集/测试集的loss
每一个epoch,计算验证集/测试集的评价指标(mae,rmse)
#将验证集的评价指标加入到nni中
if epoch < train_epoch:
nni.report_intermediate_result(valid_mae)
else:
nni.report_final_result(valid_mae)在下面的yml文件中,需要指定gpuNum,即需要使用多少张GPU卡。但是nni会自动申请gpu,你也不知道会申请到哪个gpu。为了解决这个问题,需要指定程序只能看见哪些卡,那么就会只申请看见的卡。
通过以下代码指定:1
2os.environ["CUDA_VISIBLE_DEVICES"] = "2"#单GPU
os.environ["CUDA_VISIBLE_DEVICES"] = "1,2"#多GPU注意:如果只指定能看见第2张卡,但是程序中,会给第2张卡编号的为0,即通过ctx=mx.gpu(0)来获取。如果指定能看见1和2卡,那么程序中会分别编号0和1。
nni的配置文件config.yml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33authorName: wangbeibei
experimentName: gru_grid_experiment
#并发尝试任务的最大数量,有1张gpu卡就是1,有2张gpu卡就是2
trialConcurrency: 1
maxExecDuration: 100h
#Trial 任务的最大数量,成功和失败的都计算在内
maxTrialNum: 10
#choice: local, remote, pai,在虚拟环境和docker运行时,都写local
trainingServicePlatform: local
#在第一步创建的json文件的路径,这里需要写相对路径,因为当前的yml文件和json文件在同一文件夹下
searchSpacePath: lstm_search_space.json
#choice: true, false
useAnnotation: false
# 存储日志和数据的目录, 默认值是 /data/WangBeibei/nni/experiments
#如果在虚拟环境中运行该代码,logDir是服务器下的绝对路径,/data/WangBeibei/graduation/Code/nni_save_logs
#如果在docker下运行该代码,logDir是容器下的绝对路径,/root/Code/nni_save_logs/
logDir: /root/Code/nni_save_logs/
tuner:
#choice: TPE, Random, Anneal, Evolution, BatchTuner, MetisTuner, GPTuner
#SMAC (SMAC should be installed through nnictl)
builtinTunerName: TPE
classArgs:
#choice: maximize, minimize
#mae、rmse、mse都是最小化
optimize_mode: minimize
trial:
# 指定了运行 Trial 进程的命令行
command: cd baseline && python3 lstm_baseline.py
#指定了 Trial 代码文件的目录
#首先从yml目录下,进入到代码的根目录下
codeDir: ../
#指定需要使用
gpuNum: 1启动容器
nni网页的默认端口是8080,所以需要和本地映射一下,1
2
3docker run -it -p 7000:8080 -v $PWD:/root --runtime=nvidia --rm -u 1018 --name wbbnni lin-ai-27:5000/wangbeibei/mxnet:cu_100
docker run -it -p 7000:8080 -v $PWD:/root --runtime=nvidia --rm -u 1018 --name wbbnni lin-ai-27:5000/wangbeibei/pytorch_nni启动一个nni的experiment
进入到yml所在的目录,使用以下命令,启动一个experiment实例,然后就可以在网页上查看
使用nnictl create --config config.yml
出现以下提示,说明启动成功。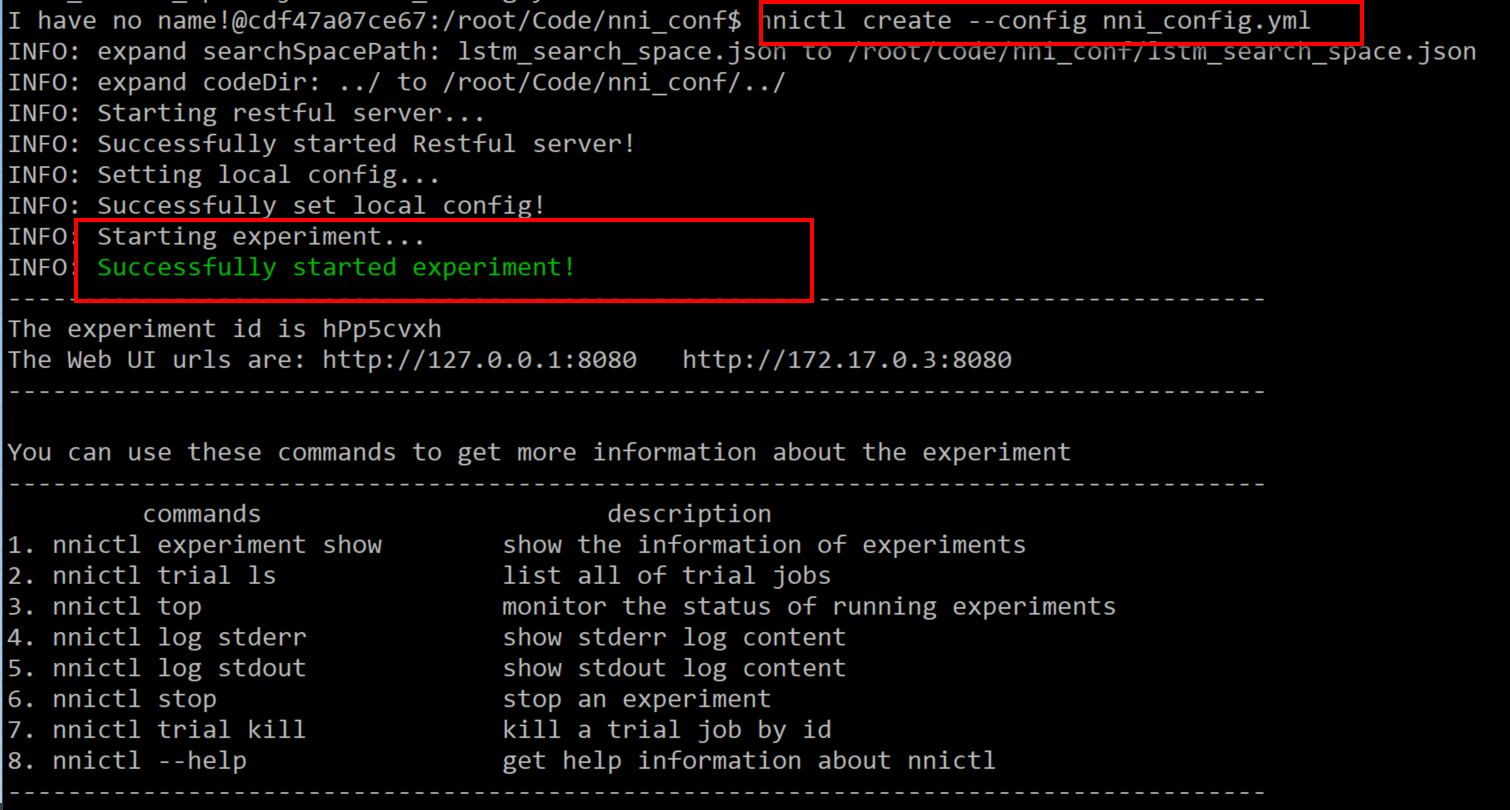
在网页上访问
在网页上打开服务器ip:7000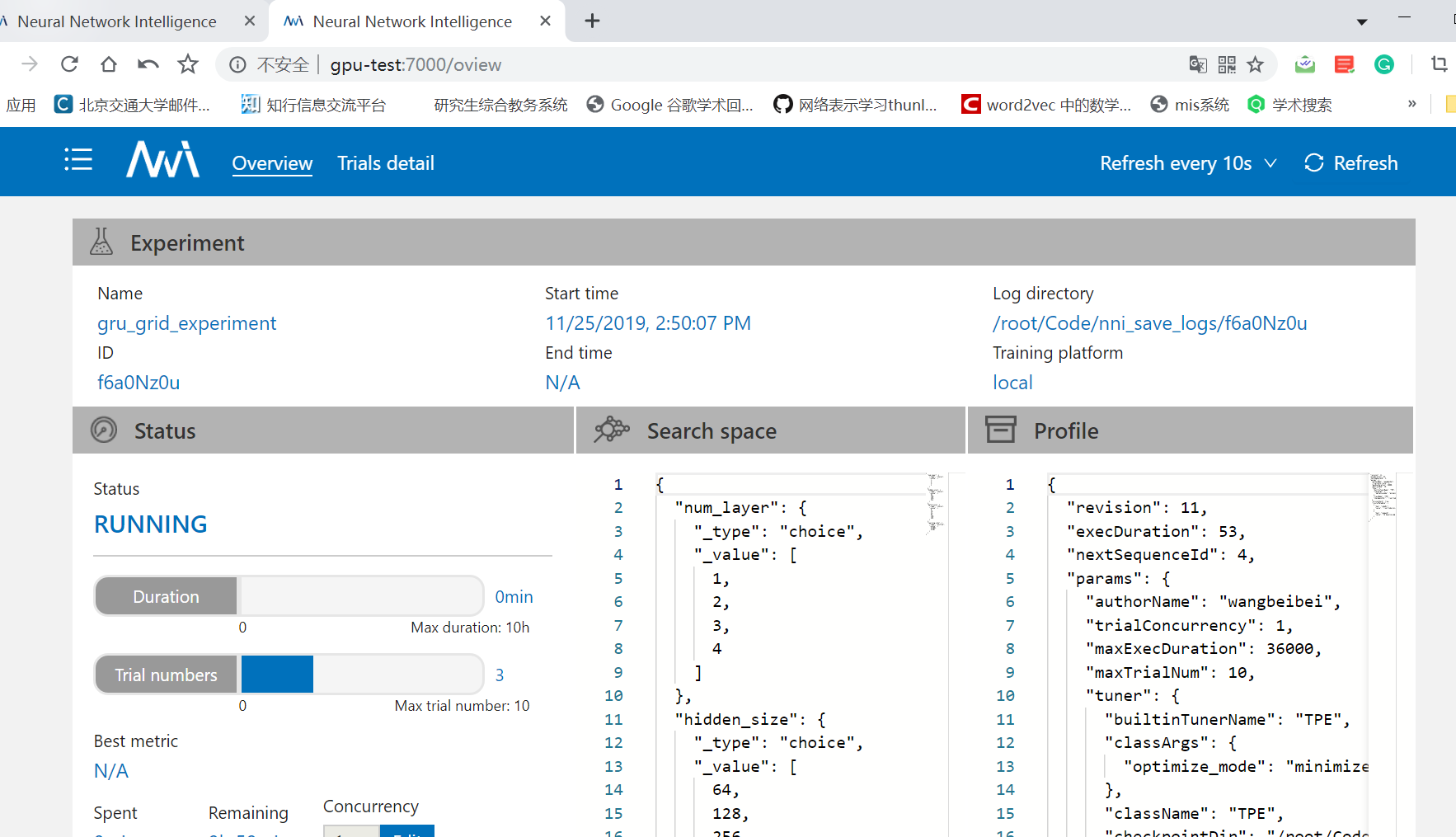
错误日志
如果提交的任务都失败了,可以去看日志文件。日志文件的位置在下图中。在容器中进入到下面的目录中。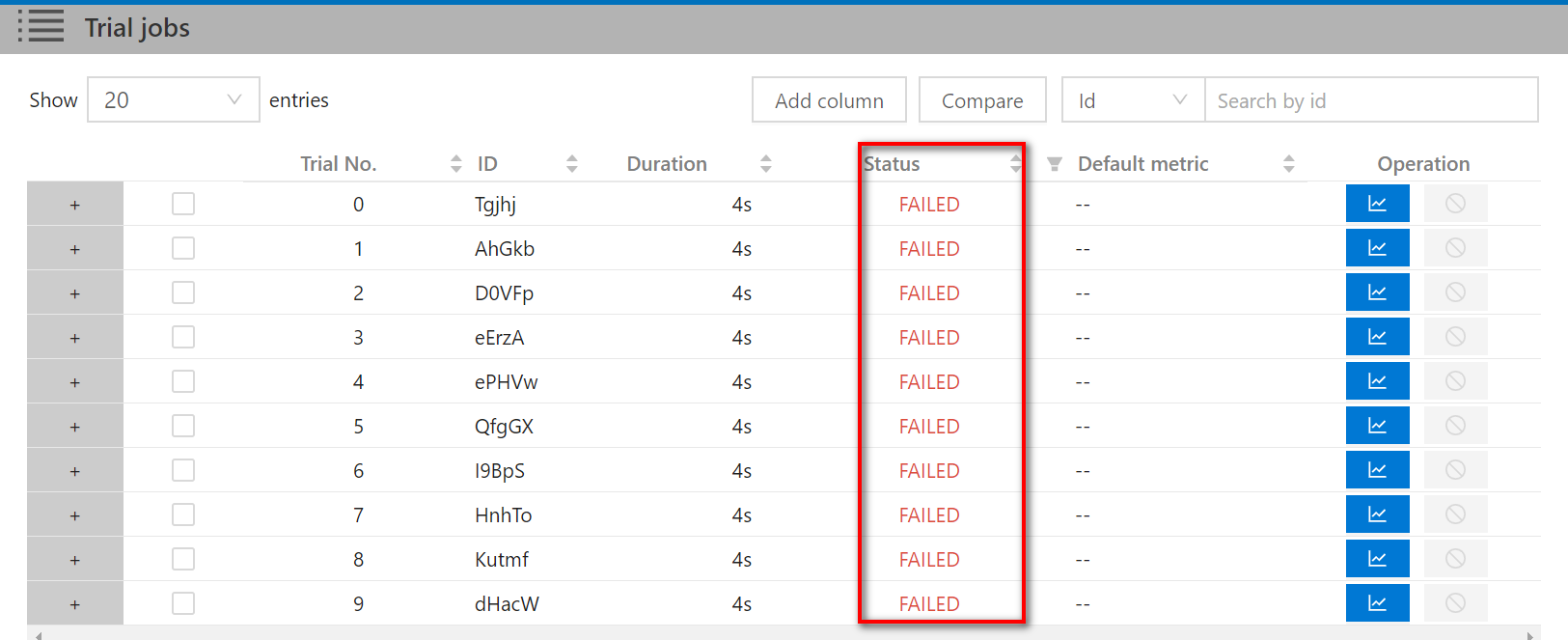
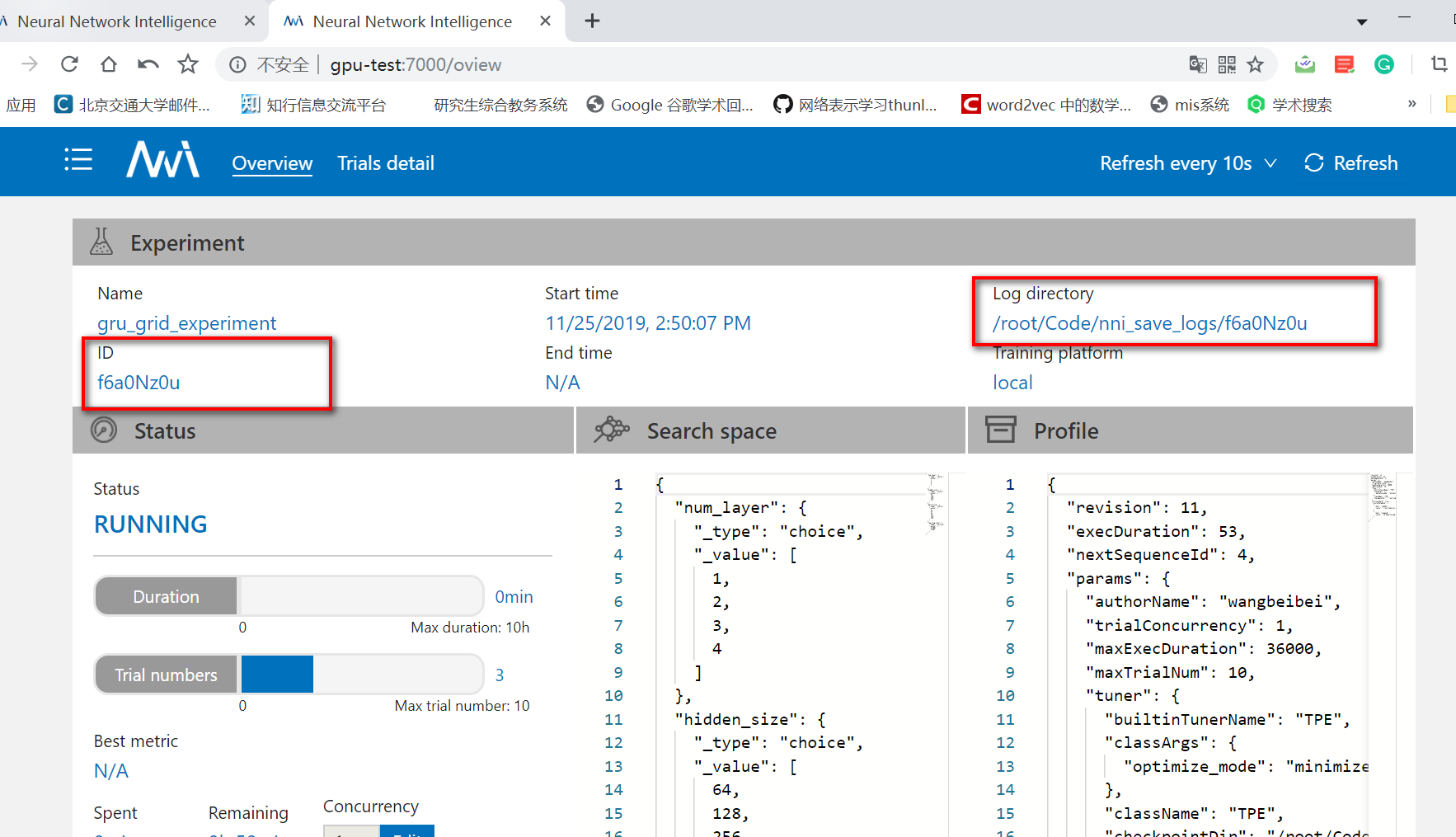
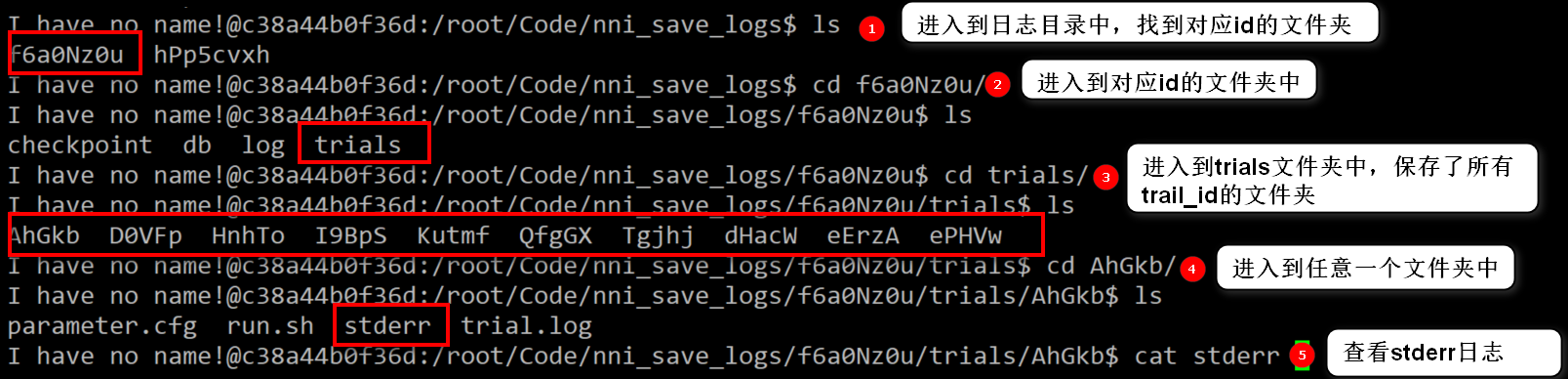
在容器中进入到日志目录中,找到对应id的文件夹。
成功日志
如果trial成功运行,那么关于这次trial的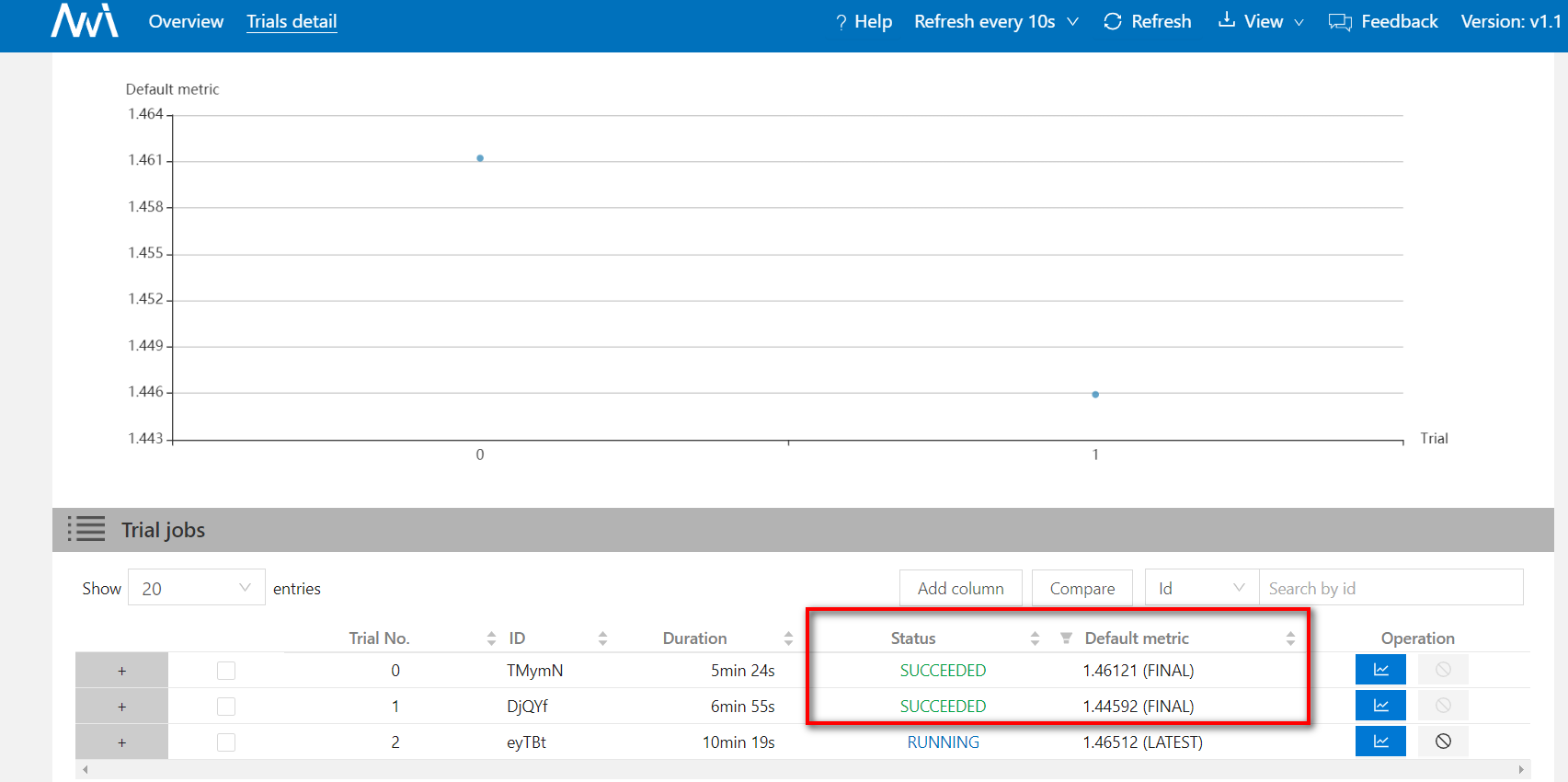
2. NNI命令
- nnictl create
(1)在默认端口8080上创建一个新的Experimentnnictl create --config nni/examples/trials/mnist/config.yml
(2)在指定的端口上8088创建新的Experimentnnictl create --config nni/examples/trials/mnist/config.yml --port 8088 - nnictl stop
停止正在运行的单个或多个Experiment
(1)没有指定id,停止所有正在运行的Experimentnnictl stop
(2)停止指定id的Experimentnnictl stop [experiment_id] - nnictl update
更新 Experiment 的搜索空间,其中experiment_id是可选的参数,后面的--filename是必填的参数。
先使用vscode修改搜索空间的json文件,然后再使用下面的命令来更新搜索空间文件。nnictl update searchspace [experiment_id] --filename examples/trials/mnist/search_space.json nnictl view
如果使用stop结束调参程序,以后还想看一下网页上的调参结果,使用该命令。这个命令只是在前端展示调参的结果,调参程序不会再次启动。1
2
3nnictl view [OPTIONS]
其中experiment_id是必填的,port是选填的
nnictl view [experiment_id] --port 8088nnictl top
查看正在运行的Experiment- nnictl experiment show
显示Experiment的信息 - nnictl experiment status
显示Experiment的状态 - nnictl experiment list
显示正在运行的Experiment的信息

