2019NIPS的一篇论文,
论文地址
1. Introduction
本文说Transformer有2个缺点,(1)locality-agnostics:局部不可知性,原先只针对一个点,计算该点和其余所有点的相关性,没有考虑到子序列和子序列的attention。(2)memory bottleneck:内存瓶颈,空间复杂度和输入序列的长度L有关。对于捕获长时间序列不方便。
2. 模型
本文针对以上2个问题,提出2种解决方案,(1)传统Transformer—>Conv Transformer,(2)使用LogSparse来减少内存的使用。
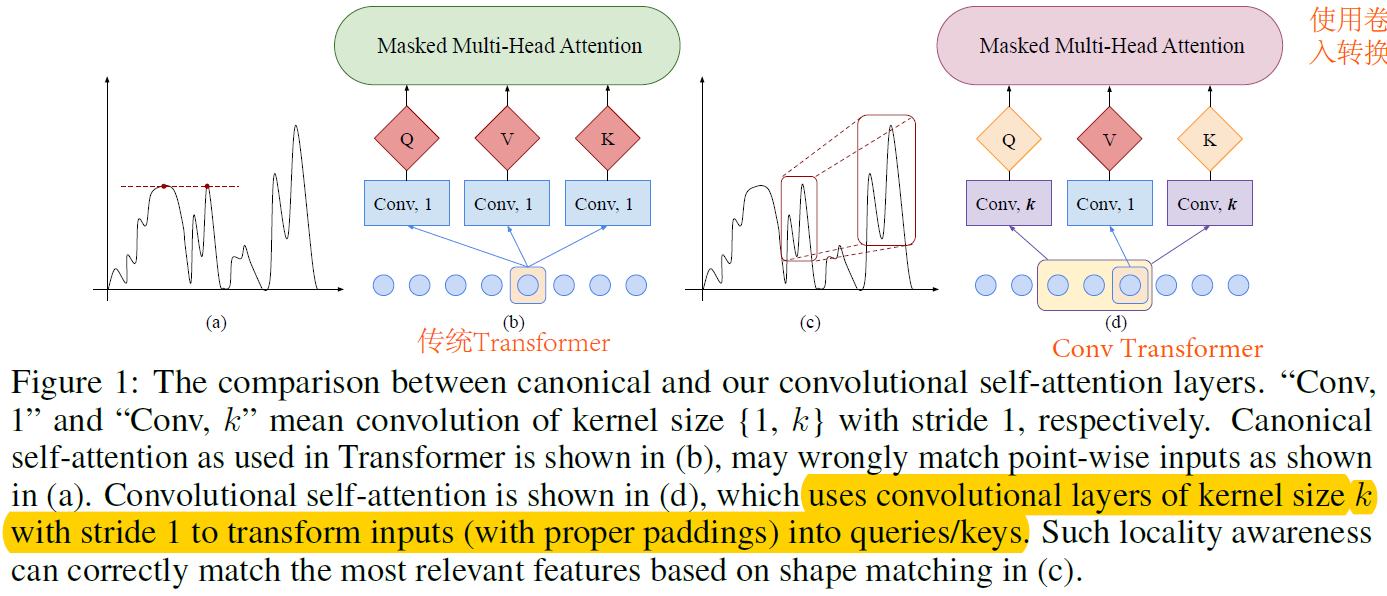
图b是传统的Transformer,在计算Attention时,计算的是一个点和其余所有点的Attention,在本文中使用一维卷积来生成query和key,在计算Attention时,使用的是子序列之间的Attention,捕获了local上下文信息。
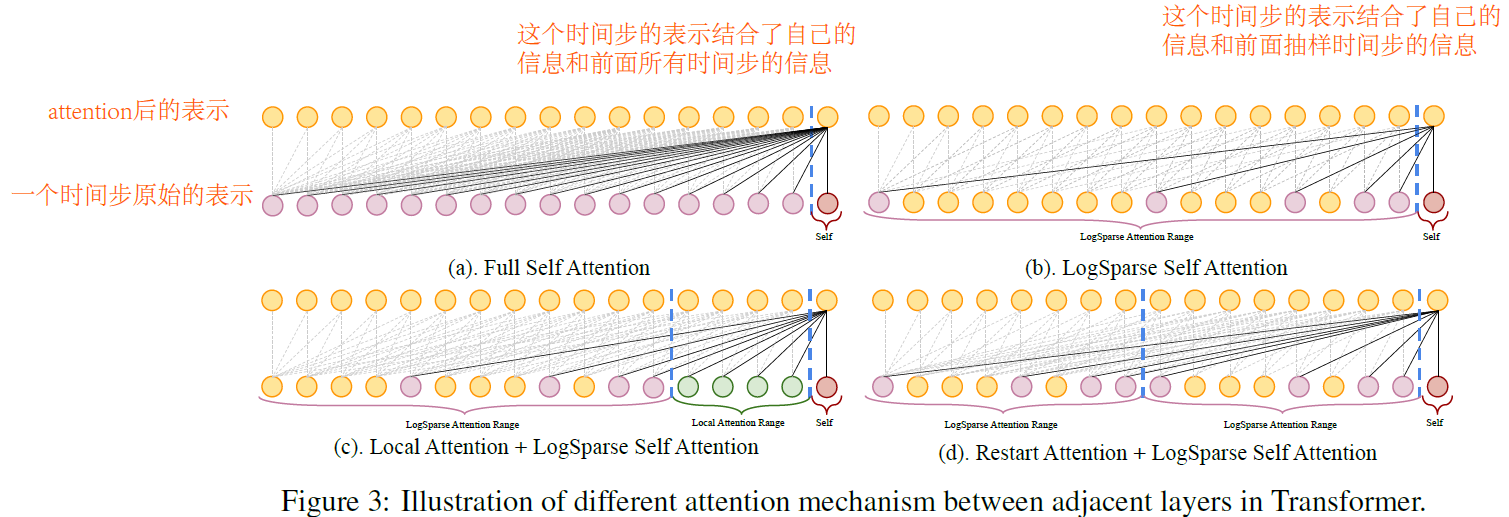
在传统Transformer在计算Atterntion时,使用的因果卷积,在第t步捕获前面所有历史时间步的信息,但是这样空间复杂度较大。所以本文提出了LogSparse,即在计算Attention时,对历史时间步的信息使用log函数进行抽样,然后多堆叠几层,也可以捕获前面所有时间步的信息。减少了空间复杂度,又可以捕获历史时间步的所有信息。

