《Attention is all you need》是Google Brain在2017年发表在NIPS的一篇文章。虽然在这篇文章之前,也在用Attention,但在这篇文章中,正式提出了Attention的概念,从此Attention在各个领域得到了广泛的应用。
- 1. Transformer讲解1
- 2. Tramsformer讲解2
- 3. 优缺点
- 4. Transformer在计算Attention为什么要scaled
- 5. Transformer为什么要加位置嵌入
- 6. Pytorch版Transformer
Latex公式在VSCode中显示还正常,博客上显示错乱。。。,凑合看吧
1. Transformer讲解1
Attention is All You Need浅读(简介+代码)
https://www.cnblogs.com/zingp/p/11696111.html
transformer和LSTM的最大区别是:LSTM是迭代的,是一个接一个字,当这个字过完LSTM单元,才可以进下一个字。Transformer的训练是并行的,就是所有的字是全部同时训练的,加快了训练效率。但是这样字之间的顺序是丢失的,transformer引入position embedding来捕获字与字之间的位置关系。
transformer的结构分为编码器和解码器:
![]()
先把一个句子输入到编码器,得到一个隐藏层,把隐藏层输入到解码器,得到输出的序列。例如在机器翻译中,输入是why do you work?通过编码器得到一个隐藏层,输入到解码器中,先给解码器一个start符,开始翻译,解码器输出翻译的第一个字‘为’,将‘为’输入到解码器中,输出‘什’,然后再输入到解码器中,直到解码器输出‘结束符’停止。
![]()
Transformer的编码器分为4部分,分别是:
- 位置嵌入
- 多头注意力机制
- 残差
- Positionwise FFN
![]()
1.1. 位置嵌入
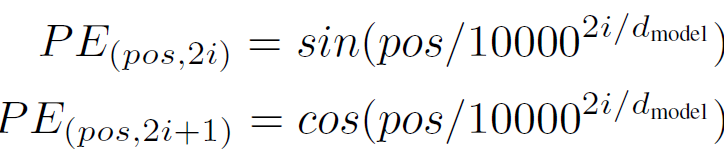
其中
$pos$:字在句子中的位置,比如一句话有10个字,pos从0~9
$i$:embedding dimension的维度,比如一个字的字向量有256维,则$i$的取值为0~255。
$d_{model}$:总共字向量的维度,即256.
如果一句话中有10个字,pos从0至9,一个字向量维度是256,从0~255.则
第0个字的position embedding为$PE_{(0,0)},PE_{(0,1)},…,PE_{(0,254)},PE_{(0,255)}$.如果字向量维度的下标是偶数使用$sin$,为奇数使用$cos$。使用以上公式可以区分字与字之间的位置信息。
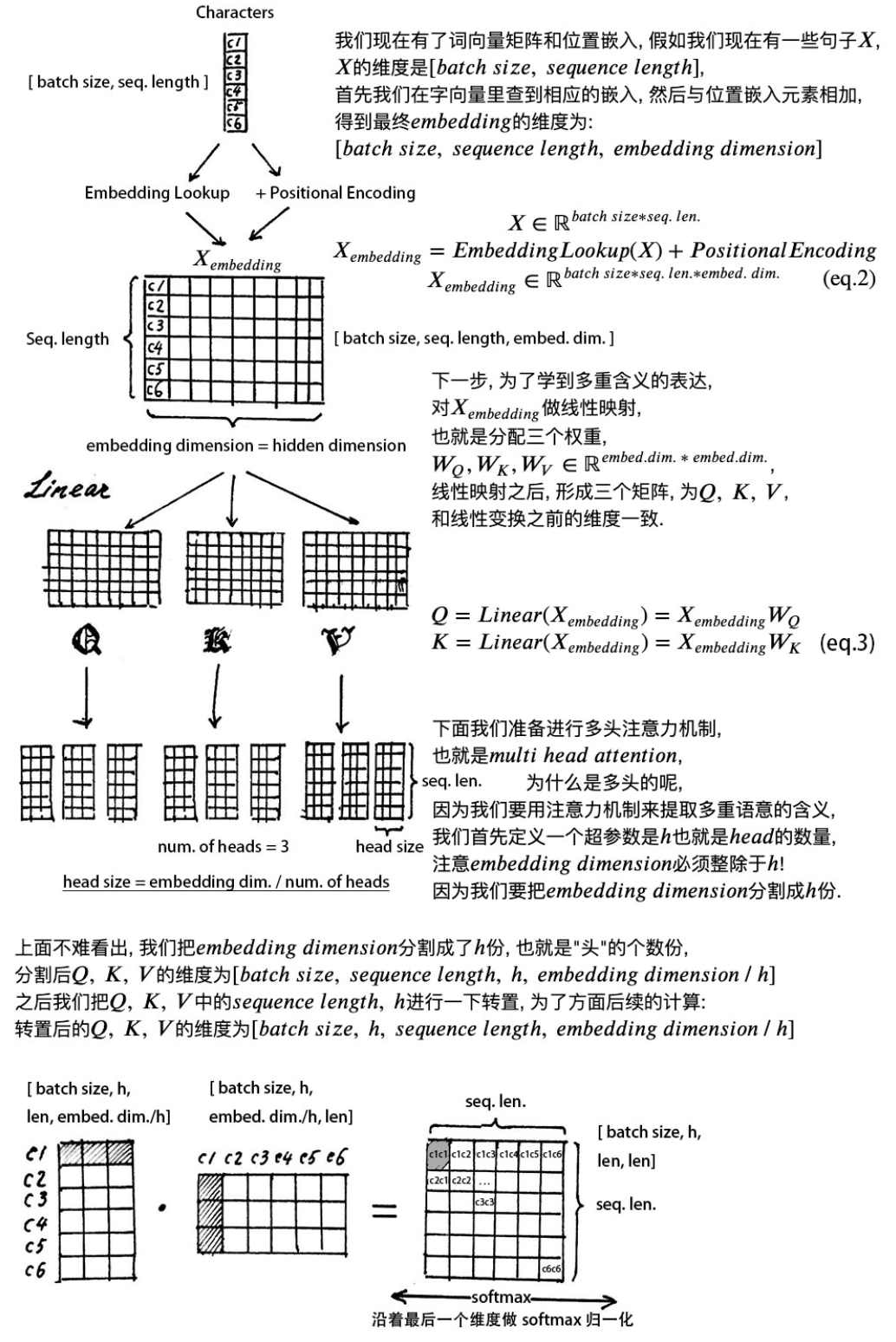
在输入的时候将每个字的词嵌入和位置嵌入相加,作为总体的输入。
1.2. self-attention
经过Embedding-lookup查表得到字向量,和position embedding得到位置嵌入,两者相加,得到一个字的最终嵌入表示,输入的维度为$X \in R^{batch_size \times seq_len \times embedding_dim}$
比如一个batch中有32个句子,每个句子有10个单词,embedding_dim=100,则输入的维度为$X \in R^{32 \times 10 \times 100}$然后将$X_{embedding}$进行3次线性变换,$W_QX_{embedding},W_KX_{embedding},W_VX_{embedding}$得到$Q,K,V$,维度都是$R^{batch_size \times seq_len \times embedding_dim}$
- 对$Q,K,V$进行分割,即多头注意力机制,其中head的个数是一个超参数,注意:$embedding_dimension$必须能够整除$head$,即一个矩阵变成$h$个小矩阵,分割之后$Q,K,V$的维度为$R^{batch_size \times seq_len \times h \times \frac{embedding_dimension}{h}}$,之后把$Q,K,V$的$seq_len,h$的维度进行转置,为了方面后面的计算,转置之后的$Q,K,V$的维度为$R^{batch_size \times h \times seq_len \times \frac{embedding_dimension}{h}}$
- 拿出一个$head$,即$Q*K^T$,得到的维度是$[batch_size,h,seq_len,seq_len]$,每个字与每个字之间的注意力,每一行表示当前这个字和所有字的关系。如果2个字之间的意思越相近,得到的注意力也越大。对每一行做softmax归一化,即每一行的和为1,得到归一化之后的注意力矩阵。
- 将注意力矩阵给$V$加权,即让所有字的信息融入到当前字中,得到当前字的一个加权表示。最终让每一个字都融合所有字的信息。得到的$V$的维度为$[batch_size,h,seq_len,embedding_dimension/h]$.
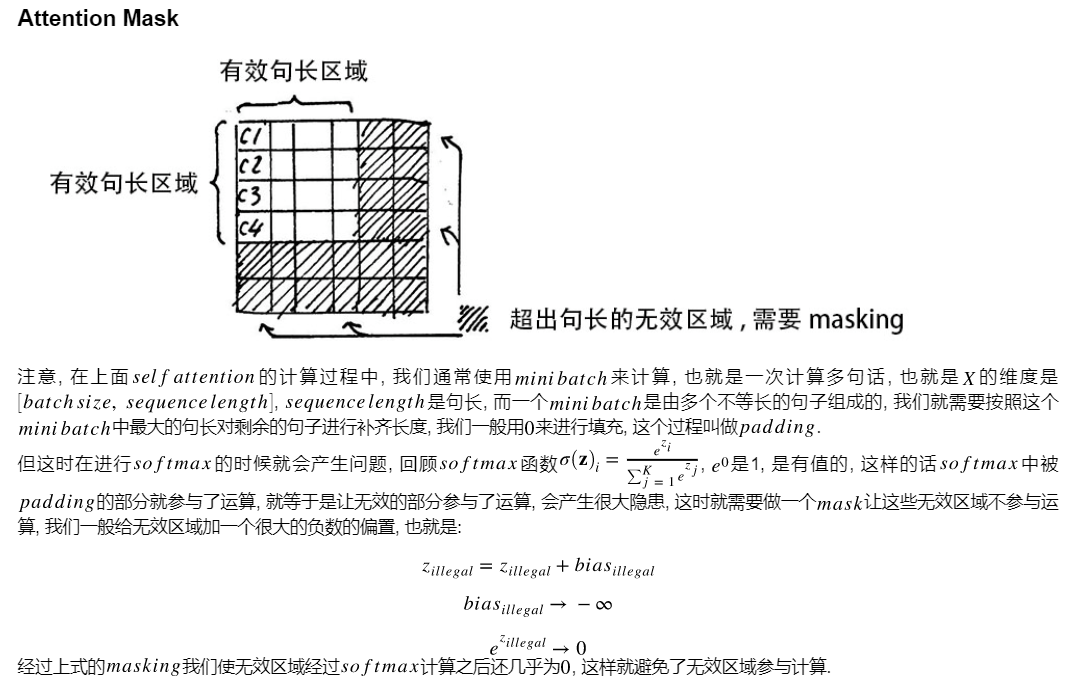
- 在训练的时候,通常多句话进行计算,即形成一个mini-batch。mini-batch中的句子的长度不一样,找出句子的最大长度max_seq_len,将短的句子补成和最大句子一样的长度,使用0padding。假设max_seq_len=10,一个句子的长度为7,即得到的attention矩阵,下面3行和右边3列都是0。在对attention矩阵做softmax会出问题,因为softmax计算涉及到指数计算,$e^0=1$,即经过softmax计算attention不为0,让无效的部分参与了计算。为了解决这个问题,需要用一个mask让这些无效的区域不参与计算,一般给无效的区域加一个很大的负数的偏置,$Z_{illegal}$表示无效的区域,加上一个很大的负数,变成负数,即通过softmax指数计算结果还是0。
- 不同的head得到的结果concat起来,才能恢复到原来的维度$[batch_size,seq_len,embedding_dimension]$。不同的head关注的点不一样,可能有的head关注的local的关系,有的head关注的是global的关系。
- 最后一步是Position-wise FFN,其实就是2层全连接,对输出$[batch_size,seq_len,embedding_dimension]$,经过2次线性变换和一个Relu激活函数。$Relu=max(0,x)$
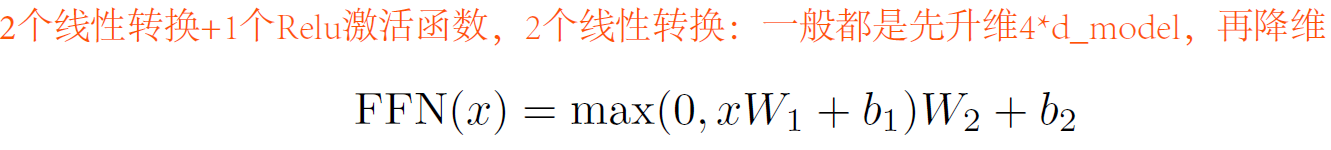
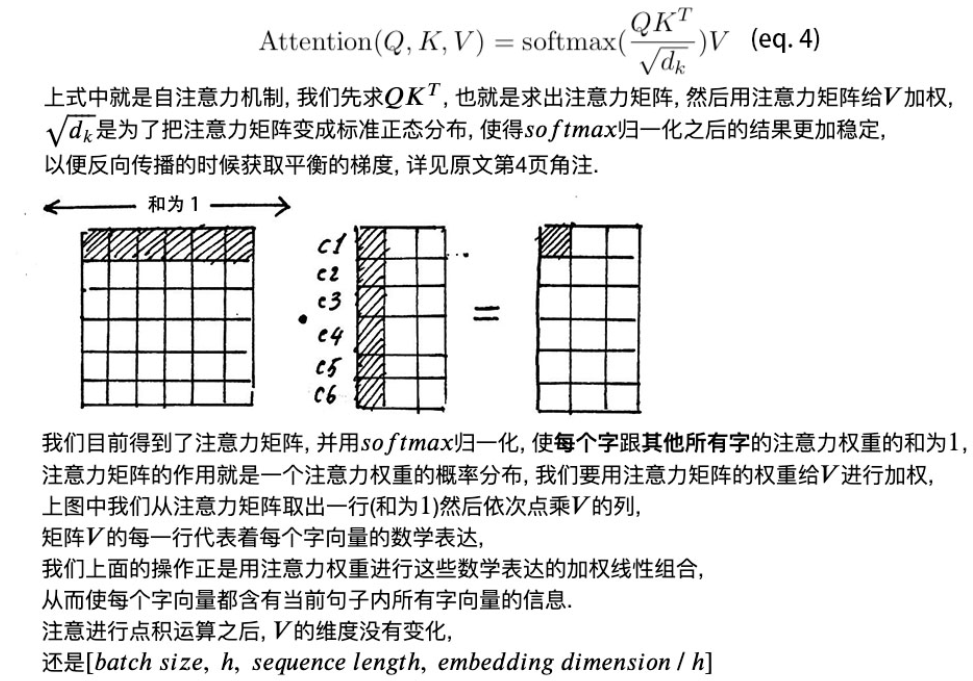
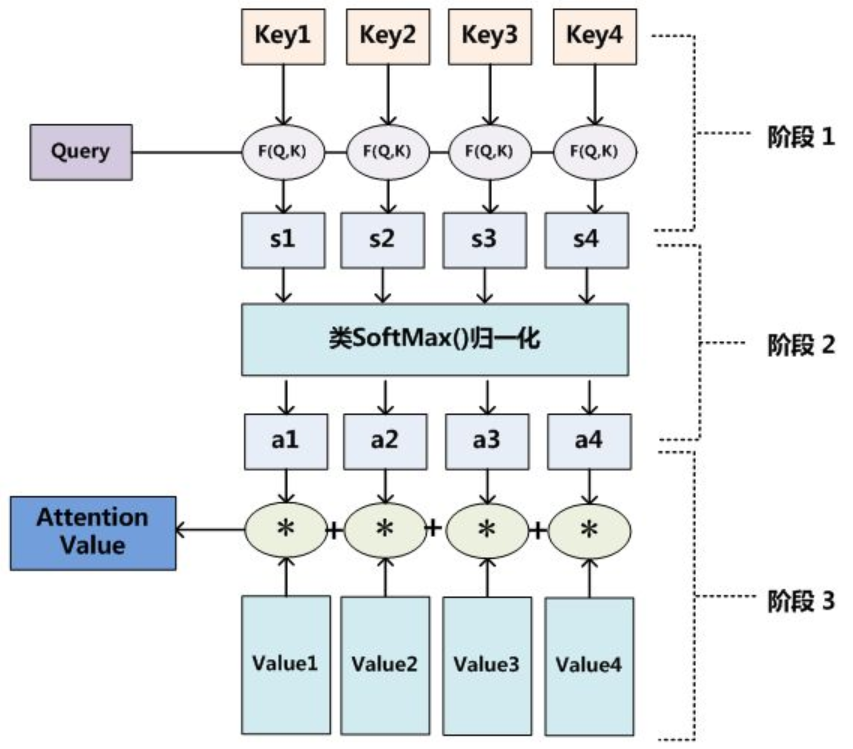
Attention的总体架构如下:给出Q,求Q和所有K的attention,然后使用attention和value加权求和,得到加权的value。
1.3. 残差连接和LayerNorm

1.4. transformer的整体结构
![]()
2. Tramsformer讲解2
其中
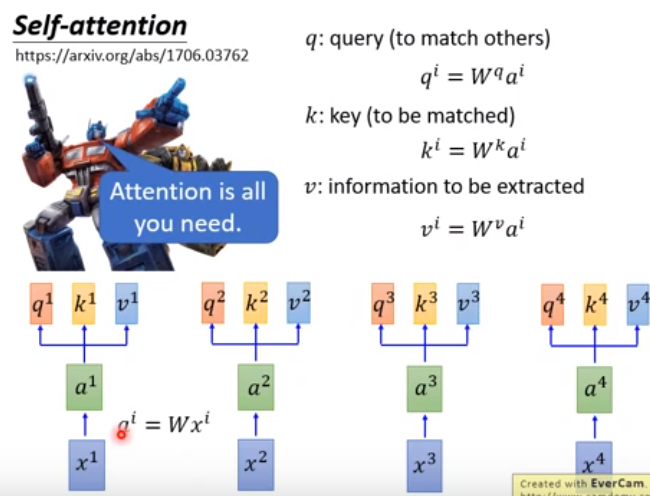
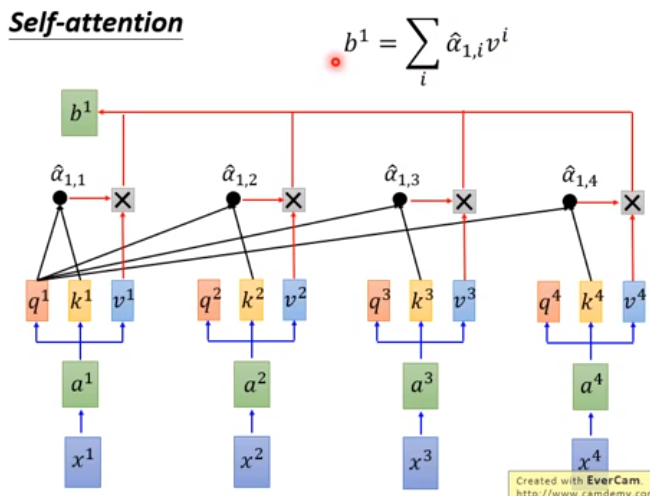
$x1,x2,x3,x4表示4个词向量,组成一个sequence,$$每一个a分别乘上3个矩阵,得到q,k,v,然后使用每一个q对每个k做attention$。
将每一个q对k做attention,然后将结果进行softmax归一化,相加为1.
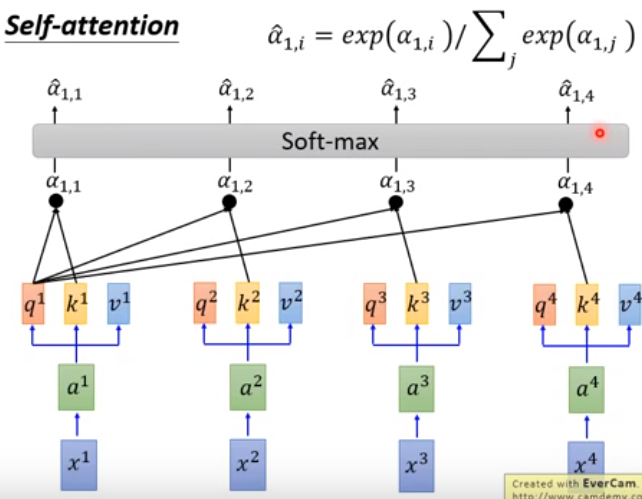
其中得到的$\hat{a}_{1,1},…\hat{a}_{1,4}$表示每个词对词1的attention,然后将attention和v做点积,再相加得到词1新的加权词向量b1,即b1包含了所有词对词1的影响,产生b1的时候已经看到了所有的词,即global attention,再远的词都可以看到。
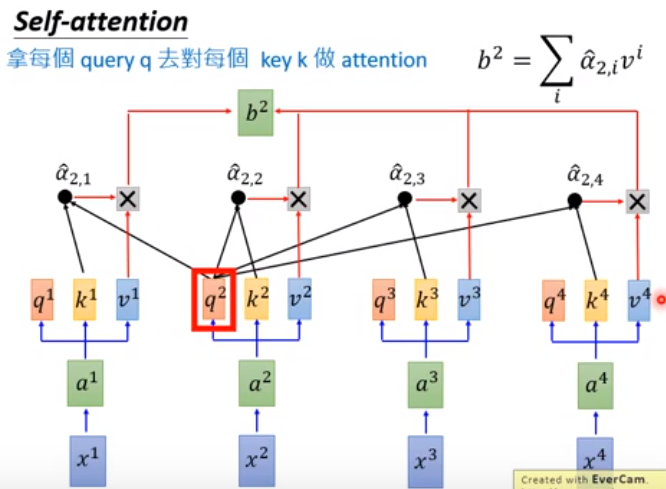
同理可以算出b2
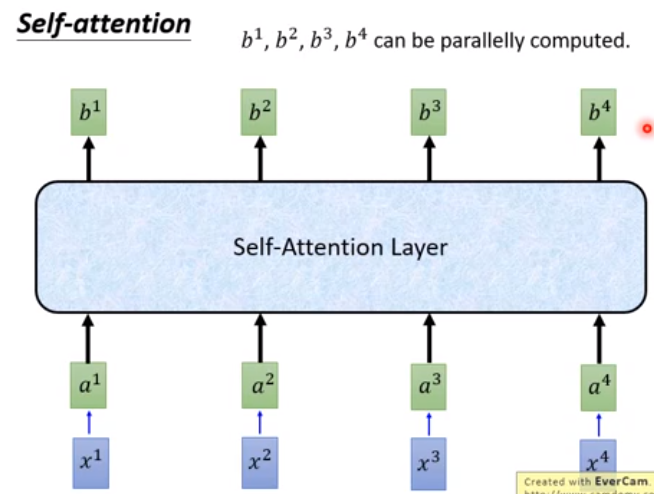
即一个序列a1…a4,通过一个self-attention layer得到一个新的序列b1…b4。此时b1…b4可以并行计算。
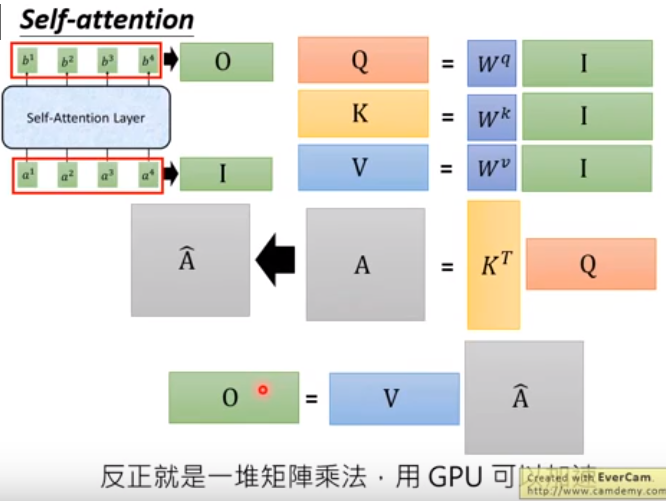
self-attention的输入看做矩阵$I$,经过self-attention layer变成矩阵$O$。
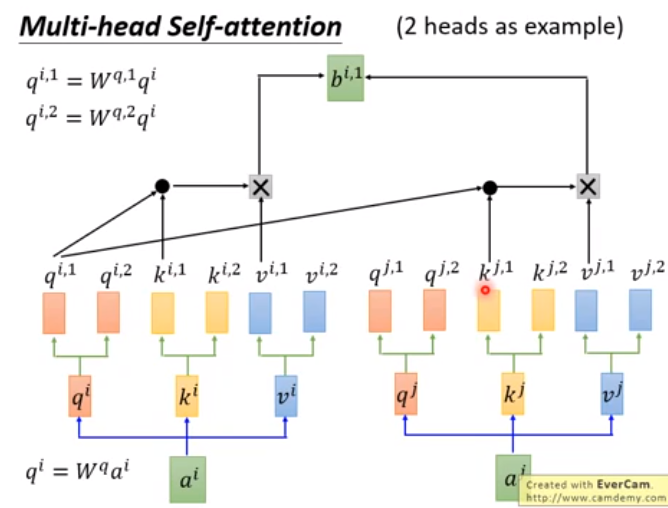
2.1. multi-head
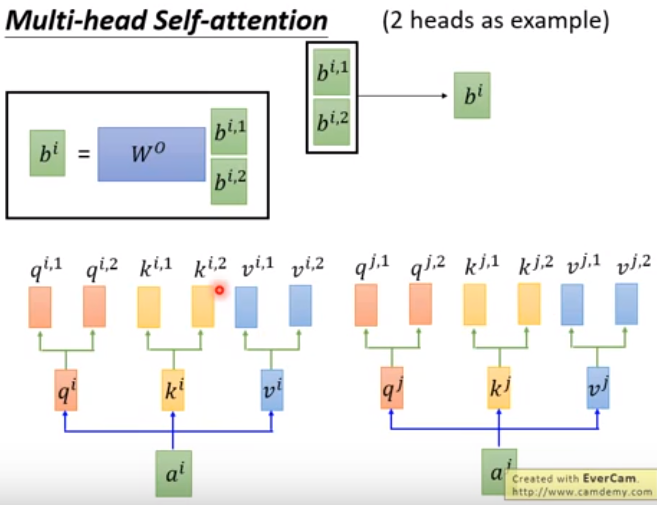
如果head=2,生成2个$q,k,v$,维度也是原来的一半。经过self-attention操作得到$b^{i,1}和b^{i,2}$,将$b^{i,1}和b^{i,2}进行concat,得到b^i,或者concat之后乘上矩阵W得到b^i.$
3. 优缺点
- 【优点】
解释性好 - 【缺点】
- 无法捕获位置信息,需要额外添加位置信息
- 空间消耗大,需要存储attention acore(N*N)的维度,所以序列长度N不能太长,易出现OOM问题。
4. Transformer在计算Attention为什么要scaled
论文中的解释是:向量的点积结果很大,将softmax函数push到梯度很小的区域,scaled会缓解这种现象。
怎么理解将softmax函数push到梯度很小的区域?为什么处于$\sqrt{d}$,而不是其他的数
因为Attention中,使用点积会使得结果变得很大,这样使得在计算softmax时计算得到的概率中,对于输入中最大的那个数计算得到的概率接近1,而其他数的概率接近0.
5. Transformer为什么要加位置嵌入
因为self-Attention没有包含位置信息,即一句话“我要吃饭了”和“吃饭我要了”在transformer中没有区别。所以要加入位置嵌入。
要实现带有位置的嵌入有2种方法:
- 通过训练学习得到位置嵌入
- 通过公式计算位置嵌入
Transformer采用方法2,因为使用公式计算位置嵌入没有参数。
6. Pytorch版Transformer
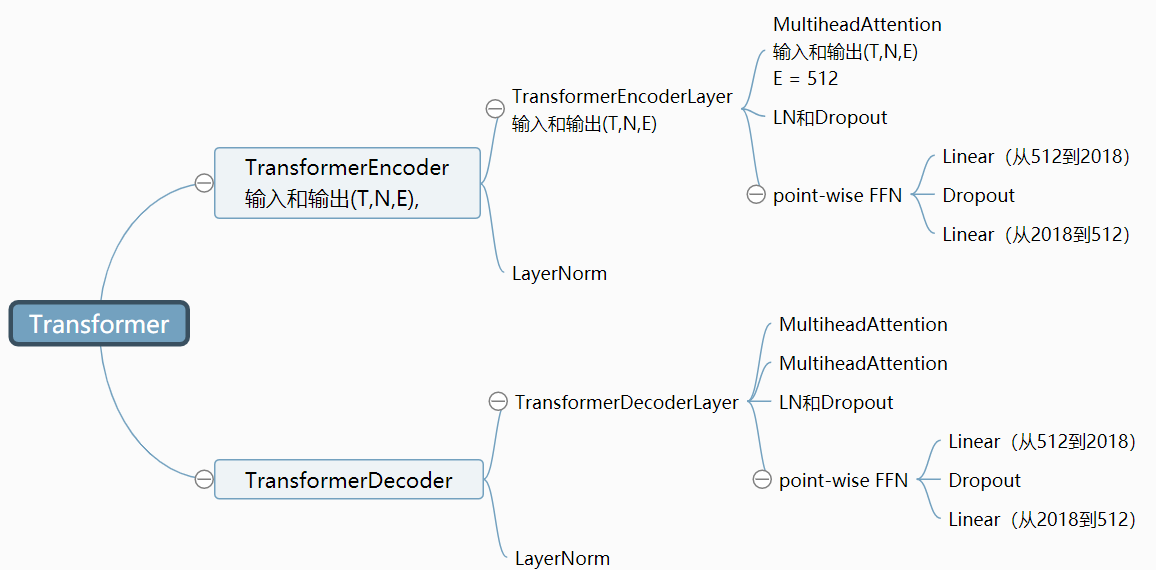
Pytorch已经将Transformer封装好了,可以直接调用,但是这个Transformer中并没有位置嵌入层,所以需要自己来实现,在将数据输入到Transformer中,先经过位置嵌入层。
【注】因为Transformer中有Dropout层,分训练模式和测试模式。训练是用model.train(),如果在测试或验证阶段使用model.eval()
https://github.com/pytorch/examples/word_language_model
PyTorch中,关于model.eval()和torch.no_grad()
Pytorch中net.eval与net.train

