- 1. 总结
- 2. POI推荐
- 3. 时空数据预测
- 3.1. HyperST-Net: Hypernetworks for Spatio-Temporal Forecasting(2019AAAI)
- 3.2. RESTFul: Resolution-Aware Forecasting of Behavioral Time Series Data(2018CIKM)
- 3.3. Spatiotemporal Multi-Graph Convolution Network for Ride-hailing Demand(2019AAAI)
- 3.4. Revisiting Spatial-Temporal Similarity: A Deep Learning Framework for Traffic Prediction(AAAI2019)
- 3.5. Deep Spatio-Temporal Residual Networks for Citywide Crowd Flows Prediction(AAAI2017)
- 3.6. Attention Based Spatial-Temporal Graph Convolutional Networks for Traffic Flow Forecasting(2019AAAI)
- 3.7. UrbanFM: Inferring Fine-Grained Urban Flows(2019KDD)
- 3.8. Deep Multi-View Spatial-Temporal Network for Taxi Demand Prediction(2018AAAI)
- 3.9. Urban Traffic Prediction from Spatio-Temporal Data Using Deep Meta Learning(2019KDD郑宇)
- 4. 图卷积
- 4.1. Semi-Supervised Classification with Graph Convolutional Networks(2017ICLR)
- 4.2. Diffusion Convolutional Recurrent Neural Network Data-Driven Traffic Forecasting(2018ICLR)
- 4.3. Graph Attention Networks(2018ICLR)
- 4.4. Deeper Insights into Graph Convolutional Networks for Semi-Supervised Learning(2018AAAI)
- 5. Time Series Forecasting
- 6. traffic accident预测
1. 总结
- 在POI推荐上,考虑考虑用户对不同POI的喜爱程度,对每个POI分配不同的权重,同时对一个POI也要考虑这个POI在不同方面的权重(比如饭店在食物和环境的权重)
- 在时空建模上,时间上考虑不同的方面,比如recent,periodic等方面,在空间上考虑neighbor,function similarity等方面,其中功能相似一般通过POI来度量
- 考虑不同区域之间的相似性,可以使用2个区域之间的traffic flow,2个区域之间的traffic flow越大,说明这2个区域关联性越强。还可以使用2个区域的POI,2个区域之间的POI越相似,这2个区域的function越相似。
- 不管time interval是多少,一般只说预测将来多少个时间段的数据,而不是说预测将来多长时间的数据。比如说预测将来5个时间段的数据。如果time interval=30min,则预测的是将来1.5h的数据,如果time interval=1h,则预测的是将来5h的数据。
- 如果是将城市划分成网格,每个网格都有空间特征,比如这个网格的flow或者speed。使用CNN获取这个区域的空间特征,所有区域的形成的矩阵形状为(F,I,J),其中F表示每个区域的空间特征个数,I和J表示网格的高和宽。如果将不同时间段的网格图拼接起来,比如将t个时间段的网格按照时间拼接起来,则形成的形状为(F*t,I,J),然后通过卷积来捕获空间特征。但是这样有一个问题,将时间拼接起来形成通道,会损失通道信息。如果预测是所有区域下一个时间段的inflow和outflow,则输出为(2,I,J)。如果预测的是所有区域接下来p个时间段的速度,则输出为(p,I,J)。
- 比如说网格数据有I*J个网格,每个网格有F个特征,这F个特征都是关于这个网格的特征。一般像外部因素不会放在网格中。因为外部因素,像温度,天气等一般不放在网格中。但也有放在网格中的,比较少。
- 比如预测第t天的flow,用到该预测天前hour,day,week数据,同时还要考虑外部因素,这里使用的外部因素只考虑被预测当天的外部因素。
- 对于预测flow问题,如果只预测一个区域的flow,在构造样本的时候对于每一个区域都构造一个以该区域为目标区域的样本。训练模型是用所有区域的样本来训练,预测的时候输出一个区域的flow。并不是预测一个区域,只用这个区域的历史数据来训练,而是用所有的区域来训练。
- 《2018[AAAI] When will you arrive estimating travel time based on deep neural networks》用户的轨迹数据本来是一个时间序列数据,每个轨迹点使用<经度,纬度>表示,可以使用嵌入将用户的轨迹转换成一个矩阵,使用1D卷积捕获空间关系,然后再送入LSTM中,捕获时间关系。
2. POI推荐
2.1. Point-of-Interest Recommendation Exploiting Self-Attentive Autoencoders with Neighbor-Aware Influence (CIKM2018)
论文题目:邻居感知的自注意自编码器的POI推荐
- 挑战
(1)建模用户POI之间的非线性关系,原先都是所有的POI权重一样;
(2)结合上下文信息,例如POI地理坐标。
(3)用户去过的POI是一小部分,而所有的POI非常多,使得POI矩阵变得非常稀疏 - 模型
self-attentive encoder and a neighbor-aware decoder(SAE-NAD)
通过self-attentive encoder区分用户对访问过的POI的喜好程度,用户的访问POI向量中每个POI的权重不同,这样可以学到更好的user hidden representation。
通过neighbor-aware decoder结合地理上下文信息,使得用户之前到达区域的附近或相似的区域可达性变大。将访问的POI嵌入和未访问的POI嵌入做内积,基于RBF(2个POI的点对点距离) kernel,来计算访问过的POI对未访问POI的影响。
为了建模稀疏矩阵,我们给未访问的POI分配相同的小权重,给访问过的POI通过访问频率分配不同的大权重。这样对于每个用户就可以区分未访问,少访问,经常访问的POI - 贡献
第一篇使用基于attention的自编码器在POI推荐上 - 目标
根据用户check-in的记录,向用户推荐一系列从未去过的POIS Definitoin
POI(类型,经纬度)
Check-in(用户id,POI ID,时间)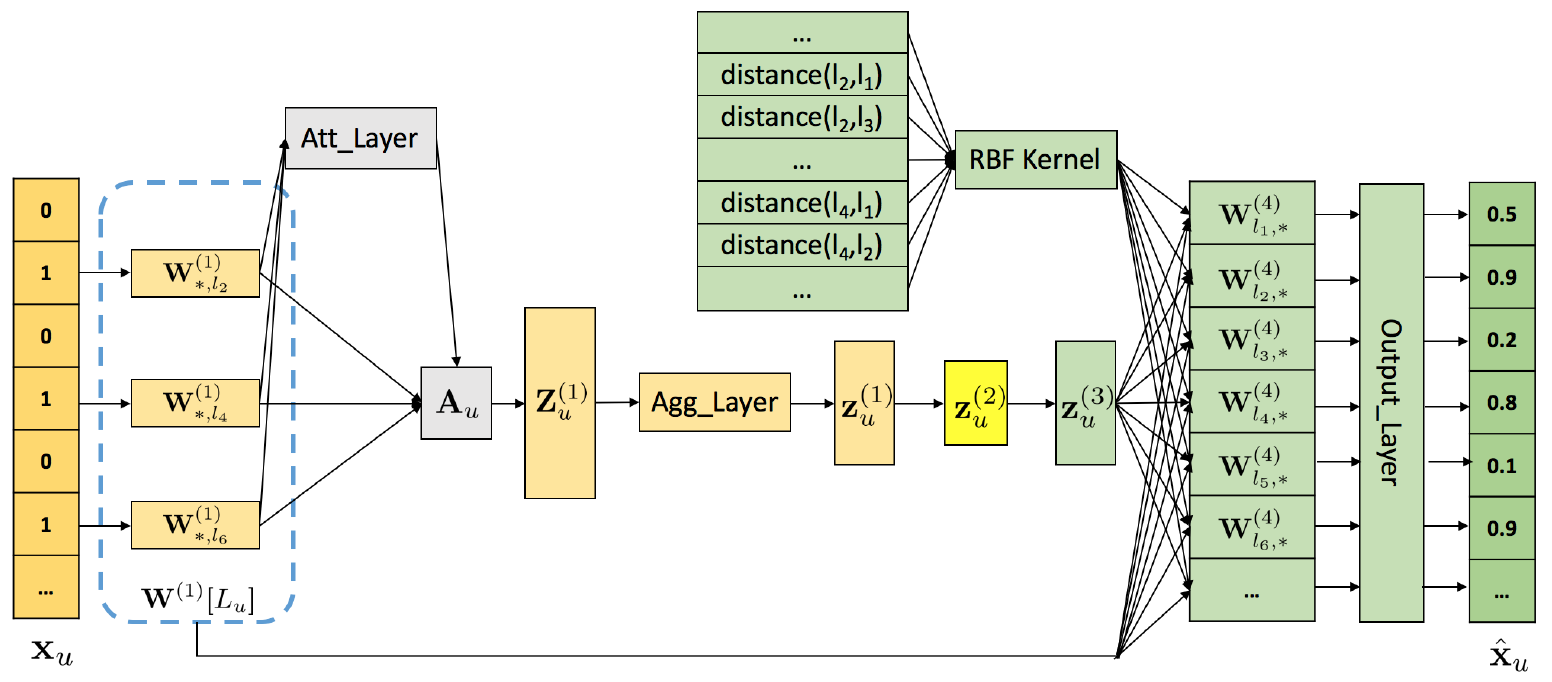
使用stack autoencoder(堆叠自编码器)学习用户隐藏表示。输出是一个用户去过和没去过的POI,一个n维的0/1向量,其中的$l_2,l_4,l_6$表示去过的POI下标,根据去过POI的下标在POI嵌入矩阵$W^{(1)}$中取出对应的POI向量组成矩阵$W^{(1)_{[L_u]}}$,得到用户已经去过区域的POI嵌入,这n个POI有些POI更能表示用户的喜好,用到self-attentive机制,为$W^{(1)_{[L_u]}}$中的每个POI嵌入学习不同的权重,来构成user hidden representation。一般的attention给每个POI嵌入学习一个分数,这个分数只能反映POI在一方面的重要性。例如饭店,在味道方面这个用户喜欢这家饭店,但是在环境方面用户不喜欢,为了从不同方面捕获用户的喜好,使用multiple-dimension attention,分别对不同方面进行打分。
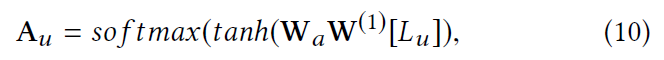
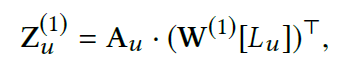
这n个POI嵌入向量,从$d_a$个方面进行打分,得到的$A_u \in R^{d_a \times n}$ ,然后把n个POI嵌入乘上分数再相加,得到第u个用户隐藏表示$Z^{(1)}_u \in R^{d_a times H_1}$,从$d_a$个方面来表示这个用户,为了让这个矩阵输入到encoder中,通过全连接将$d_a$个方面整合成一个方面,从一个矩阵变成一个向量。 然后经过2个encoder得到$z^{(3)}_u$
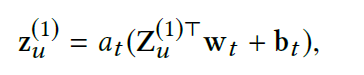
用户访问过的POI会对没访问过的POI有影响,影响程度有着2个POI的相似性和距离决定。和已访问过的POI相似或邻近的POI用户访问的概率比较大。使用内积的方式求2个POI的相似性,但是这没有考虑到2个POI之间的距离,我们采用RBF kernel根据2个POI之间的距离计算2个POI之间的相关性,得到一个N*N的矩阵。然后把相似性和距离相关性相乘,得到2个POI的最终区域相关性,
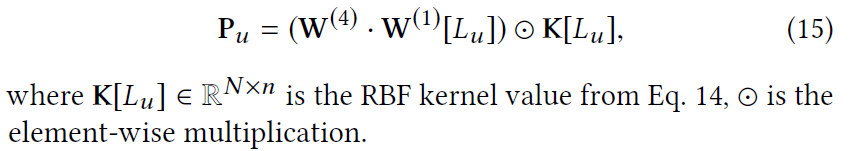
解码器阶段:将用户隐藏进行解码。其中$z^{(3)}_u$表示根据用户去过的POI得到的用户表示,$p_u$表示去过的POI对未去过的POI的影响。

- 总结
根据一个用户之前去过的POI对这个用户进行表示,不同的POI有不同的权重,同一个POI在不同的方面也有不同的权重,得到一个user hidden representation,将用户表示经过2层encoder,然后在解码的时候,用到邻居信息,去过的POI对未去过的POI有影响,影响大小根据这2个POI之间的相似性和距离决定。
2.2. HST-LSTM: A Hierarchical Spatial-Temporal Long-Short Term Memory Network for Location Prediction(2018IJCAI)
这篇论文没怎么看懂
弱实时预测,向用户推荐下一分钟或小时要去的地点。 在LSTM中使用时空信息。
- 贡献
提出HST-LSTM结合时空影响到LSTM中,来解决位置预测中数据稀疏的问题。
HST-LSTM建模用户的历史访问序列,使用encoder-decoder的方式来提高预测性能。 - 模型
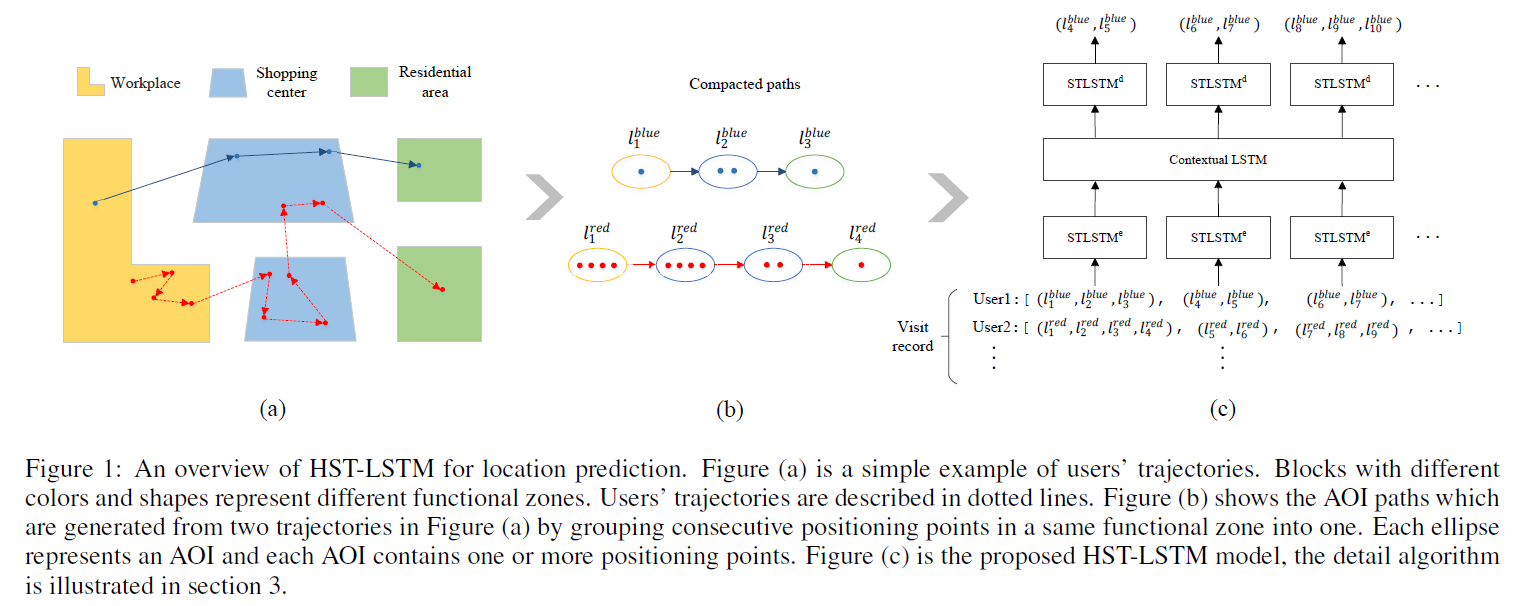
HST-LSTM model
AOI:具有一种功能的区域,例如购物中心,工作区
Visit Record:用户在一段时间内(几周或几个月)访问的所有AOIS
Visit Session:一个用户在在一个时间段(一天)访问的AOI序列,在一个session中的AOI有强烈的相关性,揭示了用户的运动模式。
Visit Session Sequence:一个用户连续的visit sessions,可以作为上下文信息预测下一个AOI。
多个AOI组成一个visit session,多个visit session组成visit record, - 目标
用户在一段时间内访问了N个AOI,这N个AOI按照时间排序(AOI可能有重复),给定前j个用户去过的AOI,预测接下来用户要去的N-j个AOI,是一个多对多的预测。
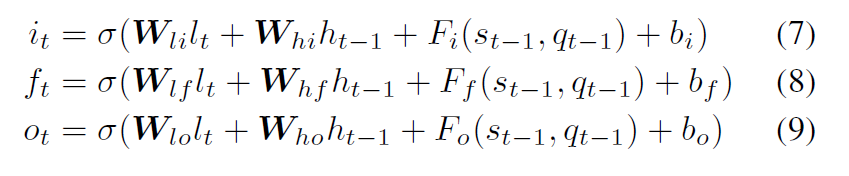
在LSTM中3个门控机制中,输入门,遗忘门,输出门加入时空因素。其中s和q都是d维的向量,分别表示空间和时间的影响因素。
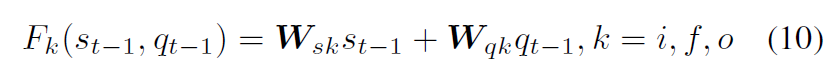
基于提出的ST-LSTM,对每个visit session建模。使用STLSTM,每一个时间步输入的信息是一个visit session中的AOI嵌入,使用一个STLSTM对一个session进行建模,输出最后一个时间步的隐藏状态$h^i_e$作为第$i$个session的表示。对$n-1$个session进行建模得到n-1个隐藏状态,将这n-1个隐藏状态使用Contextual LSTM建模长期的visit sequence,在global context encoding阶段,每个时间步输入的是上一个STLSTM中session的表示。
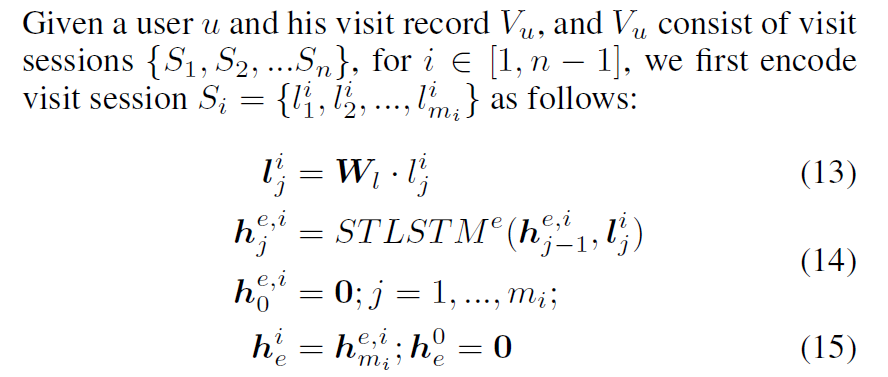
在Decoding阶段,使用前i-1个session的推断接下来要去的AOI。
- 总结
在LSTM阶段加入时空信息,提出STLSTM。
使用encoder-decoder来实现POI推荐,encoder和decoder都是LSTM
3. 时空数据预测
3.1. HyperST-Net: Hypernetworks for Spatio-Temporal Forecasting(2019AAAI)
题目:超时空网络预测
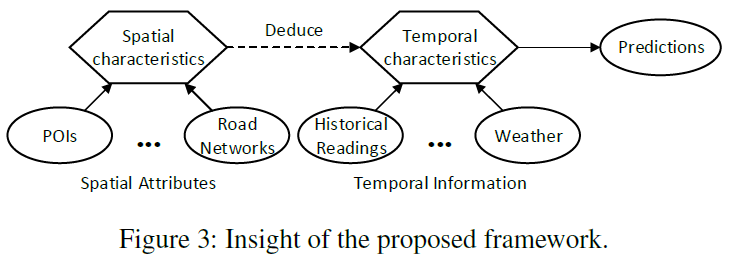
以前的方法分别对时间和空间分别建模,没有考虑到时间和空间内在的因果关系。空间的属性(POI或路网)影响空间的特征(工作区或居民区),从而影响时间特征(inflow trend)
- 目标
预测一个区域。根据这个区域的空间和时间特征,预测ST数据,例如空气质量预测,交通流量预测。
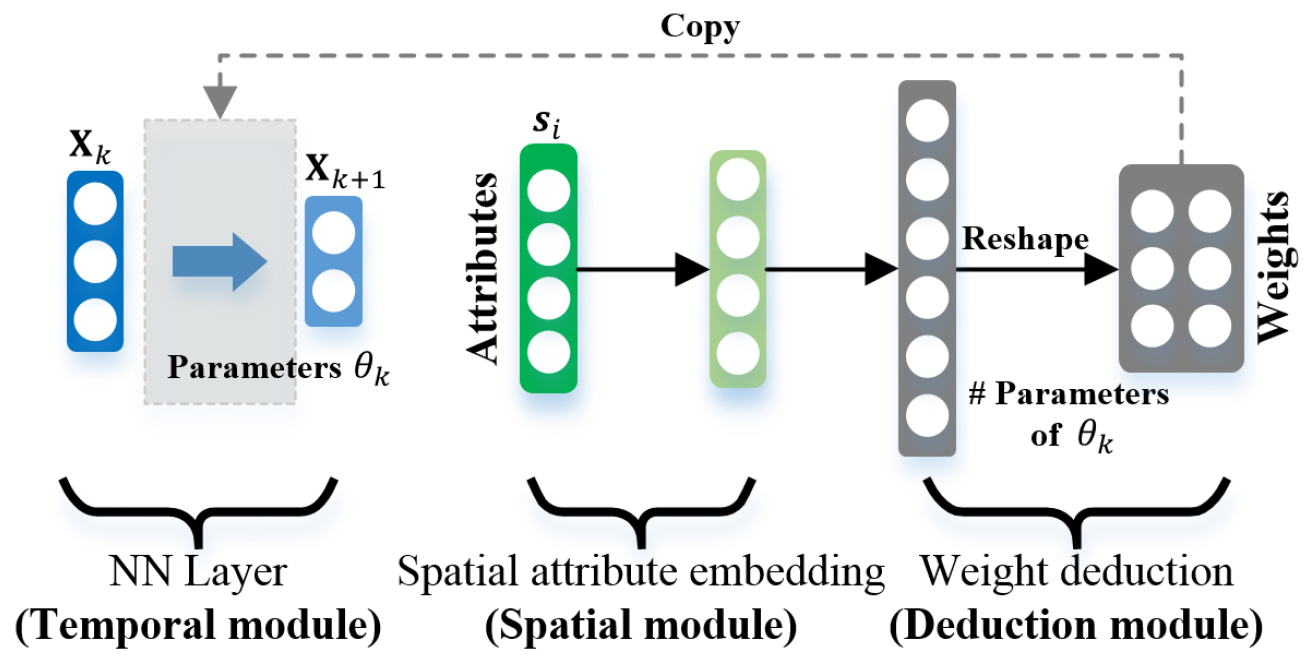
本篇论文提出一个框架,包含3部分:空间模块,时间模块,演绎模块(deduction module)。
这是第一篇考虑空间和时间特征内在因果关系的框架。
使用spatial module从spatial attribute建模spatial characteristic,然后使用deduction module从spatial characteristic建模temporal characteristic.
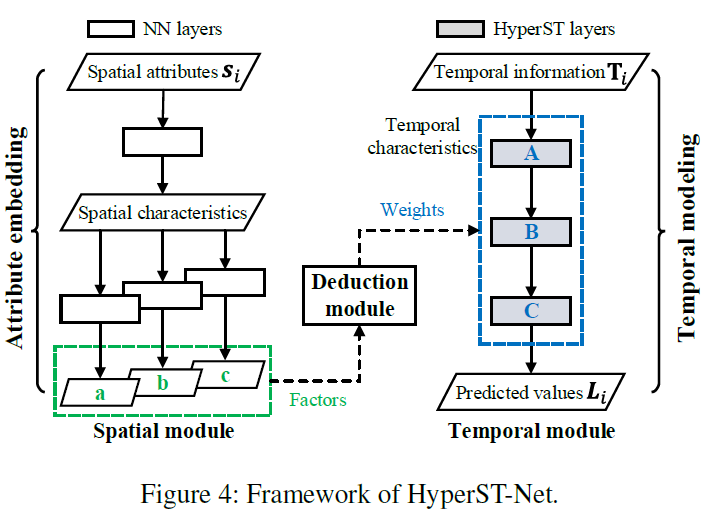
Spatial module:两阶段模块,在第一阶段,将spatial attribute建模成spatial characteristic。在第二阶段,生成多个独立的因素,deduction module使用它们来建模时间模块中对应神经网络的参数。例如a—》A,b—》B,c—》C。空间模块像一个hypernetwork。
Temporal module:应用不同的HyperST层,HyperST层的参数由deduction module计算得到,可以被看做object的时间characteristic。
Deduction module:连接空间和时间模块,空间和时间的内在因果关系被考虑进去。
3.2. RESTFul: Resolution-Aware Forecasting of Behavioral Time Series Data(2018CIKM)
基于不同粒度的行为时间序列数据预测
行为数据,例如购买行为,邮件行为。
现在的预测方法经常仅仅使用一种时间粒度(天或周),然而现在的行为时间数据经常有多重时间粒度模式,每种时间模式之间相互依赖。本篇论文提出RESolution-aware Time series Forecasting(RESTFul),使用循环神经网络来编码不同粒度的时间模式成一个低维表示。不同时间粒度的表示在融合阶段,使用卷积融合框架。最终学到的conclusive embedding向量输入到MLP中用来预测行为时间序列数据。
这是第一篇使用多时间粒度来预测时间序列数据。
不同粒度的时间序列长度是一样的,比如为5,就表示最近3天,5周。
- 定义
- Behavioral Time Series:表示一段时间段内的行为数据,$X=[x_1,x_2…x_t,…x_T],其中t \in [1,2,…T],x_t是一个标量,数值或离散值,表示第t个时间段的行为数据$
- Behavioral Time Series Forecasting:给定历史行为时间序列数据,给定前k个时间段的历史数据$[x_T-k,…x_T],预测x_{T’},其中T’ >= T$
- Interval Resolution $\alpha$:$s_t和s_{t+1}之间的时间差距$,如果为1天,表示1天测量一次,如果为1周,表示1周测量一次。
- Remporal Resolution $\beta$:如果$\beta=week$表示一次测量1周,如果为1day,表示一次测量1天。
- 限制$\alpha >= \beta$ 如果$\alpha=1week,\beta=1day,表示1周测量1次,1次测1天。 \alpha=1week,\beta=1week,表示1周测量1次,1次测1周。其中x_t = g(x_t,x_{t+1}…x_{x+\beta})的聚合值,例如一周的平均值或最大值$
- 模型
RESTFul有2个阶段,第一个阶段,使用循环神经网络来编码不同时间粒度的时间模式。第2个阶段,使用卷积融合模块来融合不同时间粒度的表示。
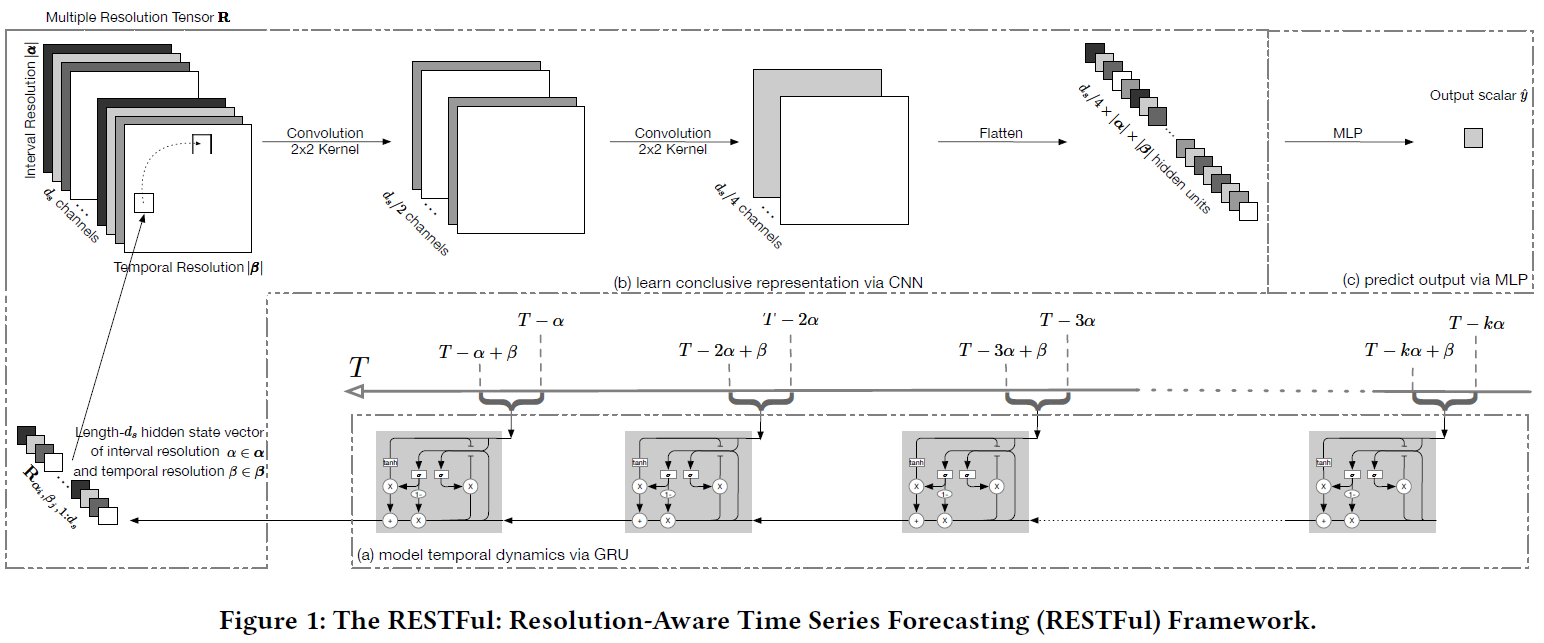
$\alpha,\beta \in {day:1,week:7},这样<\alpha,\beta>就有3种组合,分别是<1,1>,<7,1>,<7,7>$,对于每种组合都有一组行为时间序列数据,对于每组时间序列数据,都使用GRU来这个序列进行时间建模,得到最后一个时间步的隐藏状态向量。将每种组合得到的隐藏状态拼接起来,最终得到一个张量,维度是$R^{|\alpha|\times|\beta|\times d_s}$。然后使用卷积操作,先使用2次2*2的卷积,同时使用padding保证得到的结果大小不变,只改变通道的大小,最终得到的结果是$R^{|\alpha|\times|\beta|\times d_s/4}$,然后展开得到一个$|\alpha|\times|\beta|\times d_s/4$的向量,输入到MLP中,最终可以用来预测回归任务和分类任务。回归任务的损失函数是均方差,分类任务的损失函数是交叉熵。
- 总结:
考虑不同时间粒度,对不同时间粒度的序列使用GRU建模,将最后一个时间步的隐藏状态拼接起来使用CNN。使用2维卷积对时间数据进行建模,不太合适,可以考虑时间3维卷积。
3.3. Spatiotemporal Multi-Graph Convolution Network for Ride-hailing Demand(2019AAAI)
时空论文阅读笔记一
预测出租车流量,对一个区域在空间上考虑neighbor,function similarity,road connectivity。
3.4. Revisiting Spatial-Temporal Similarity: A Deep Learning Framework for Traffic Prediction(AAAI2019)
- 挑战:空间依赖性时动态的,随着时间变化,比如早上居住区和工作区的联系强烈,晚上联系较弱。时间上不是严格的周期性,存在dynamic temporal shifting。比如早高峰在7点值9点,每天可能不一样。
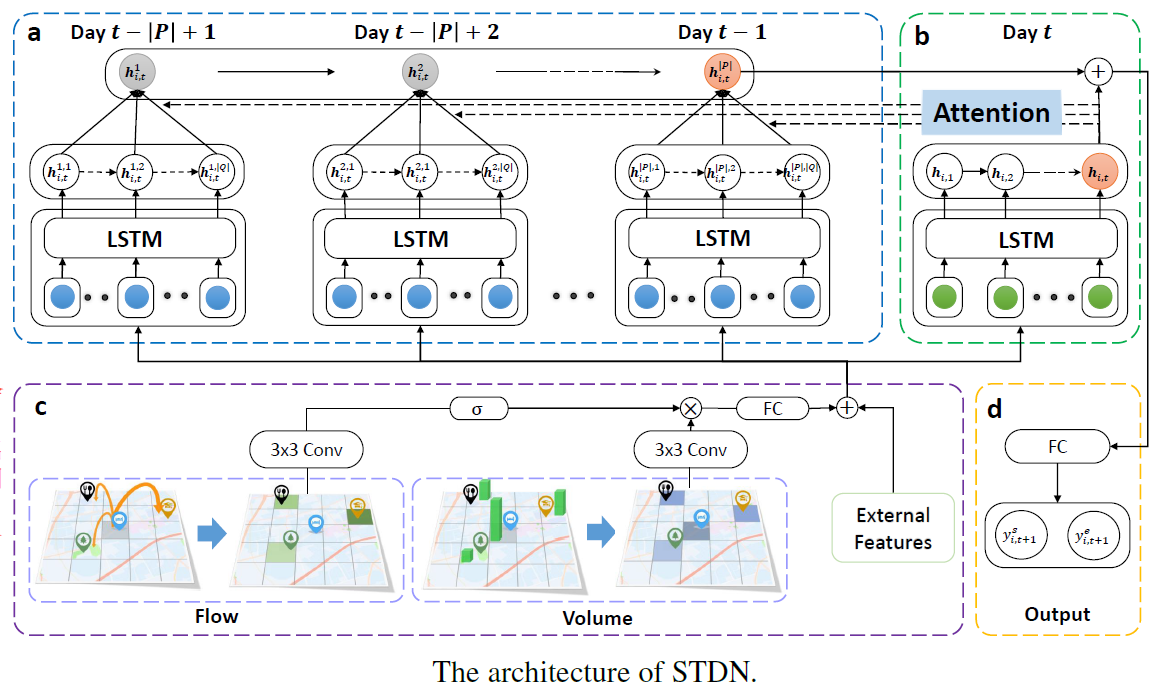
- 模型:Spatial-Temporal Dynamic Network(STDN),流量门控机制学习location之间动态相似性,periodically shifting attention机制捕获长期周期时间shifting。
- 将一个城市划分成a*b=n个网格,将一个时间段(eg.一个月)划分成m个长度相等的时间段。
traffic volume:区域$i$的start流量$y^s_{i,t}$:在第$t$个时间段离开这个区域的trip个数,区域$i$的end流量$y^e_{i,t}$:在第$t$个时间段到达这个区域的trip个数。
traffic flow:从在第$t$个时间段从区域$i$出发,在第$\tau$个时间段到达$j$区域的traffic flow使用$f^{j,\tau}_{i,t}$表示。 - 目标:给定时间段t及其之前的traffic volume和traffic flow,预测第$t+1$个时间段的start and end traffic volume。
- 模型:使用Local CNN和LSTM捕获时间和空间关系。
在提出本文的组件之前,先介绍一下2个base model。
空间 Local CNN
使用traffic volume来获取空间相关性,使用local CNN得到区域表示。
Short-term 时间依赖,短期比如说预测今天9:00~9:30的traffic volume,输入是今天7:00~8:30。
使用LSTM来获取短期时间依赖。
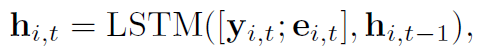
- 下面提取本文的改进,
Local CNN—》Flow Gate Mechanism
Short-term temporal—》Periodically Shifted Attention Mechanism
Spatial Dynamic Similarity: Flow Gating Mechanism(空间动态相似性)
在local CNN中,local spatial dependency主要是traffic volume。Y表示traffic volume。 但是traffic volume是静态的,不能完全反映目标区域和周围邻居的关系,traffic flow可以更加直接的反应区域之间的联系。两个区域之间的flow越多表示2个区域联系越强(eg.这2个区域越相似)。设计Flow Gating Mechanism(FGM)捕获区域间的dynamic spatial dependency。
traffic flow分为2种:inflow和outflow。
给定一个目标区域$i$,获取该区域历史$l$个时间段的traffic flow(从$t-l+1到t$),将历史$l$个时间段的inflow和outflow拼接在一起,形成一个三维张量$F_{i,t} \in \mathbb{R}^{S \times S \times 2l}$,其中$S$表示邻近区域,使用CNN建模区域之间的空间相关性。其中$F_{i,j}$作为第一层的输入。
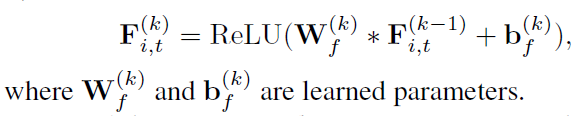
在每一个卷积层,使用traffic flow信息来捕获区域之间的动态相似性,通过一个流量门来限制空间信息。每一层的输出是空间表示$Y^{i,k}_t$,受流量门调整。
即对上式的traffic volume,通过traffic flow来控制。 $\sigma$的取值是[0,1],对traffic volume起到门控机制。
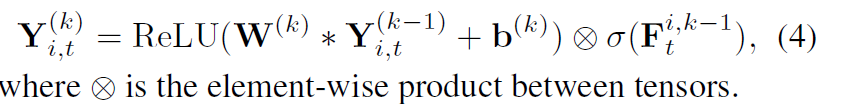
Temporal Dynamic Similarity:Periodically Shifted Attention Mechanism(时间动态相似性)
以前的LSTM没有考虑长期依赖(例如:周期),比如预测第$t$天9点的volume,考虑昨天或前天这个时间段的数据。但是traffic volume并不是严格周期的,在时间上会有平移,图a显示了在天之间的时间平移,图b显示了在周之间的时间平移。
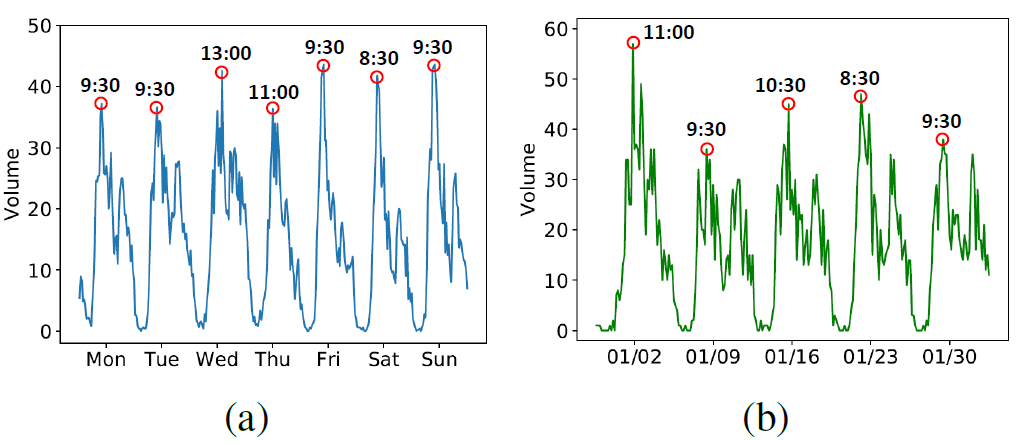
因为时间具有shifting,因此设计了Periodically Shifted Attention Mechanism(PSAM),这里只考虑天周期性,不考虑周周期。从前P天对应时间段的数据来预测,为了解决time shifting,获取每一天的$Q$个时间段,假设预测的时间段是9:00~9:30,$Q=5$,则获取该时间段前后1个小时的数据8:00~10:30。
即获取前P天的数据,并且从每天中获取Q个时间段。如模型图所示,对于每一天都有Q个时间段,可以获取每个时间段的traffic volume和traffic flow,然后使用图卷积,即可以得到一个区域每个时间段的表示。每一天都有一个自己的LSTM,每个LSTM都有Q个时间步,每个时间步都会得到一个隐藏状态向量,即会得到Q个隐藏状态,使用Attention,将Q个隐藏状态整合成一个隐藏状态,用$h^p_{i,t}$表示。其中attention中的$\alpha^{p,q}_{i,t}$表示在第$p$天,第$q$个时间段的重要性。$\alpha^{p,q}_{i,t}$根据长期的隐藏状态和被预测天的短期隐藏状态$h_{i,t}$计算得到。
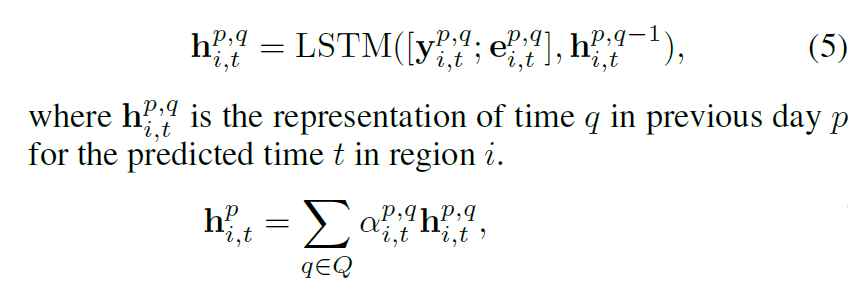

经过attention之后,P天会得到P个隐藏状态,然后再经过一个LSTM来保存周期的序列信息,最终得到长期依赖表示$\hat{h}^p_{i,t}$。
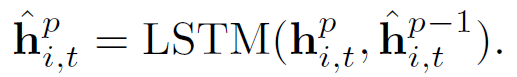
Joint Traning
将短期表示$h_{i,t}$和长期依赖$\hat{h}^p_{i,t}$拼接得到$h^c_{i,t}$,送到一个全连接神经网络中,得到最终的输出,表示为$y^i_{s,t+1}$$y^i_{e,t+1}$作为start volume和end volume。

3.5. Deep Spatio-Temporal Residual Networks for Citywide Crowd Flows Prediction(AAAI2017)
预测flow of crowd,提出ST-ResNet,使用残差网络来建模traffic crowd的时间邻近,周期,区域属性,对每一种属性,设计一个残差卷积单元,建模traffic crowd的空间属性。ST-ResNet对3个残差神经网络的输出分配不同的权重,动态地结合3个输出,在整合3个输出的时候同时考虑外部因素,例如天气,day of week。在这篇论文中,预测2种crowd flow:inflow和outflow。inflow是在一个时间段内从其他区域进行到目标区域的crowds。outflow是在一个时间段内离开目标区域的corwds。inflow和outflow是行人数量、车的数据、公共交通系统上的人数量或者3个的总和。
- gloal:给定历史t个时间段所有区域的inflow和outflow,预测第t+1个时间段所有区域的inflow和outflow。
将一个city网格划分成$I*J$,下面定义inflow和outflow

inflow:从其他区域进入到(i,j)
outflow:从(i,j)出发到其他区域
其中$Tr:g1—>g2…—>g_{|Tr|}$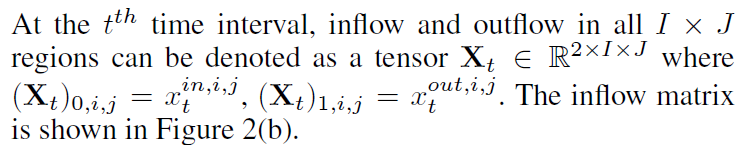
其中X是所有区域的inflow和outflow矩阵。
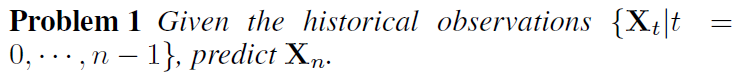
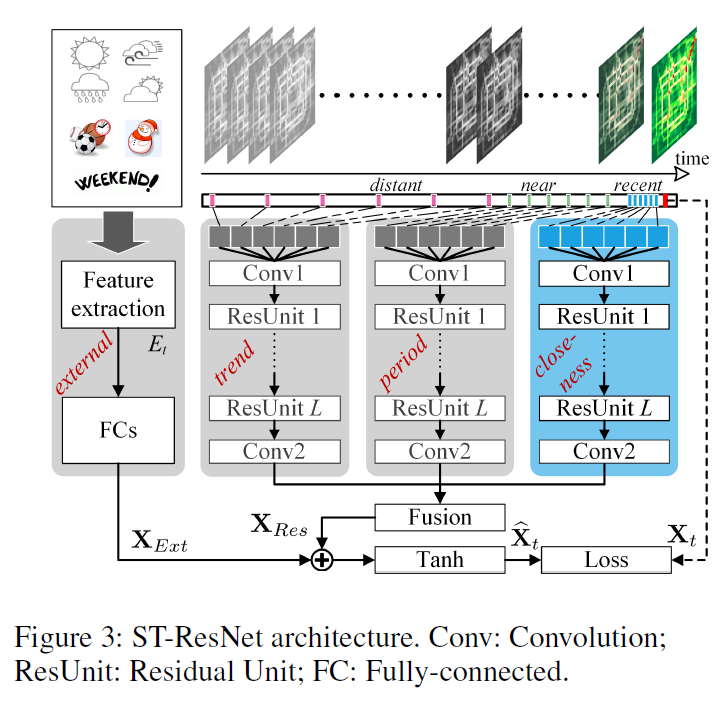
这个模型由4个组件构成:temporal closeness,period,trend和external。
每个时间段内都有一个网格图,2通道,表示所有区域的inflow和outflow。多个时间段按照时间排列会有多个图。在时间段上划分为3部分:recnet、near、distant,分别送到3个模块中:closeness,period,trend,然后对三个模块的输出分配不同的权重融合,再和external信息融合送到Tanh中。
Conv-ResNet
前3个模块内部是相同的结构,由2部分组成:卷积和残差单元
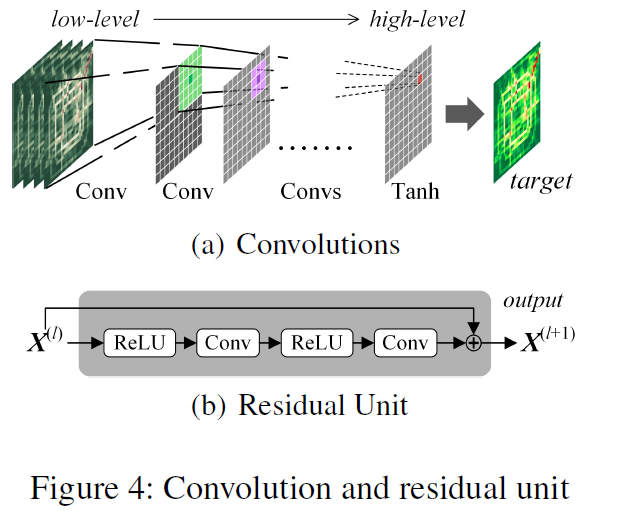
拿closeness模块举例,首先使用Conv来捕获near和distant区域的关系。 将closeness的图拼接在一起,closeness一共有$l_c$个时间段,每个时间段有2个通道,将这$l_c$时间段的图拼接在一起,变成$2l_c I * J$的数据送入到第一层卷积层。

根据上述结构分别对period和trend进行编码
External Component
主要考虑以下的外部因素,使用2层全连接提取外部因素。第一层是嵌入层,第二层是转换低维到高维,和$X_t$的维度一样。
Fusion
所有的区域都被closeness,period,trend影响,但是不同的区域影响程度不同,

Fusion the external component
将3个closeness,period,trend的输出融合,然后再和被预测时间段t的外部因素融合。

3.6. Attention Based Spatial-Temporal Graph Convolutional Networks for Traffic Flow Forecasting(2019AAAI)
使用时空图卷积预测所有节点在未来n个时间步的traffic flow。将traffic flow分为3个时间粒度级别:recent,daily,weekly,3个时间粒度的数据使用3个相同的module来建模,每个module有2个submodule:时空Attention和时空GCN
3.7. UrbanFM: Inferring Fine-Grained Urban Flows(2019KDD)
从粗粒度级的flow推断细粒度级的flow。比如给出的是33区域的flow,需要推断6\6区域的flow.大的区域称为superregion,划分的小区域称为subregion,同时考虑superregion和subregion的flow约束关系,加起来和superregion的flow相等。
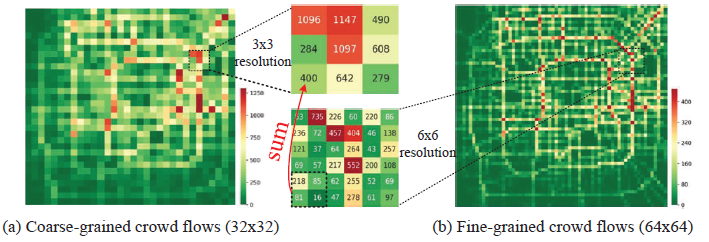
模型的总体框架如下:
主要分为2个部分:inference network和external factor subnet。其中推断网络由2个模块组成,特征提取模块和分布上采样模块。
在推断网络中,输入是$I \times J$的flow,先经过卷积和M个残差块,捕获空间相关性。在分布上采样模块,每个网格区域需要划分为$NN$个区域,所以分布上采样主要是改变特征图的大小,从原来的$FIJ$变成$FNINJ$,对于每个网格区域,经过分布上采样模块,输出的$NN$的flow分布概率。原始的输入$X_c$的维度是$IJ$,经过近邻上采样,会将原始的输入变成维度为$NINJ$,就是将每个区域的$flow$复制$NN份$,然后和分布上采样输出的概率相乘,得到每个细粒度区域的flow。
**需要注意外部因素,输入是一个向量,经过特征提取模块,输出也是一个向量,为了将外部因素和粗粒度级的flow和细粒度级的flow拼接,也需要将外部因素reshape成$IJ或NINJ$的形状。我原先以为是将外部因素复制$IJ或NJNJ$份,其实并不是,是使用reshape函数。*

3.8. Deep Multi-View Spatial-Temporal Network for Taxi Demand Prediction(2018AAAI)
将一个城市进行网格划分,时间段:30min。预测一个网格区域的taxi demand。
注意:根据多个区域,多个时间段,预测一个区域,一个区域的taxi demand
根据前$t-h,….t$个时间段的taxi demand和外部因素,预测第$t+1$个时间段的taxi demand。

文章的标题是multi-view分别是spatial view、temporal view和semantic view(城市功能),其中spatial view考虑的是target的邻近区域,但是有些区域离target很远,但是城市功能(居民区、商业区)和target相似,通过semantic view来捕获。
1. Spatial view:Local CNN
仅考虑空间近邻的区域,邻居区域大小$SS,例如77$,通道数为1,表示taxi demand,表示为$Y^{i,0}_t \in R^{S \times S \times 1}$,经过K个卷积层,输出变成$Y^{i,K}_t \in R^{S \times S \times \lambda}$,然后reshape成一个向量维度为$S^2\lambda$,输入到全连接$FC中,输出一个d维的向量$。时间段有$t-h,….t$,每个时间段的$SS1$的网格都输入到Conv中,然后再经过全连接$FC$,所以最终输出$t-h,….t$个时间步,每个时间步是$d维。$
细节:对于城市的边界区域,使用0来填充邻居。
2. Temporal view:LSTM
经过spatial view输出每个时间步的表示,再和每个时间步的外部信息(天气,hour of day,day of week)拼接,共同输入到LSTM中,最终输出最后一个时间步的隐藏状态。
3. Semantic View:Structural Embedding
根据区域之间的城市功能相似性来构建graph,图中的节点是所有的区域,共$L个$,边:2个区域之间的相似性。相似性的计算是通过$Dynamic \quad Time \quad Warping \quad (DTW)$。 下图中给出了2个区域相似性的计算公式。根据区域$i 和 j$在工作日的taxi demand的时间序列,计算2个时间序列的相似性,即2个区域的相似性。根据区域间的相关性构建了一个全连接图$G$,使用$Embed$嵌入层,本文使用$LINE对图中的节点进行嵌入$,得到每个节点的低维特征表示,然后再次送入全连接中。
注意:构建的是一个全连接图,即任意2个节点之间都有边,因为任意2个节点都可以达到。
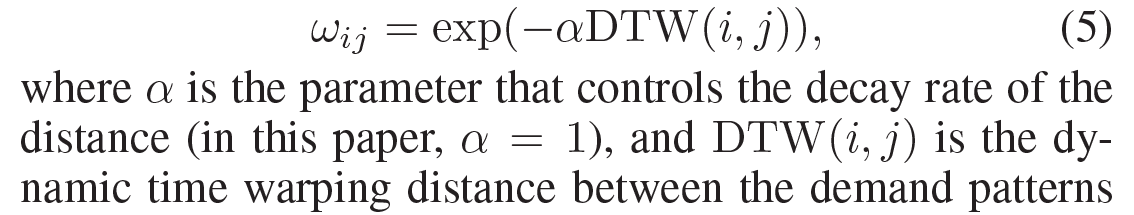
4. Prediction Component
将LSTM中最后一个时间步的隐藏状态和target区域的节点表示$m^i$拼接,送入到全连接中,经过$sigmoid函数,$最终输出的值在[0,1]之间,然后再反归一化得到真实的taxi demand。

5. Loss Function
注意:损失函数有参考意义。
损失函数中包含2部分,一个是输出的taxi demand的均方差,一个是MAPE,前面更关注一些大的值,为了避免模型被一些大的值控制,后面加入MAPE。
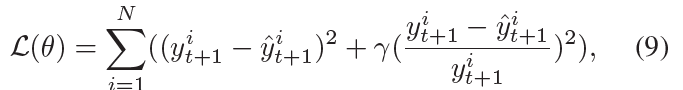
6. 数据集
使用广州2个月的taxi数据,$区域划分2020,每个区域700m700m$,
(1)使用$Min-Max归一化为[0,1]之间,同时也对y进行归一化到[0,1]之间。$模型预测的输出也在$[0,1]之间,$然后对$y$使用反归一化得到真实的taxi demand。
(2)邻居大小设置为$9*9$
(3)时间段:30min,根据前8个时间段(4h)预测下一个时间段
(4)最后FC的激活函数是$Sigmoid$,其余FC的激活函数是$Relu$
3.9. Urban Traffic Prediction from Spatio-Temporal Data Using Deep Meta Learning(2019KDD郑宇)
通过时空数据,使用深度元学习,进行城市交通预测
论文代码:https://github.com/panzheyi/ST-MetaNet
Abstract
预测城市traffic有以下挑战:(1)复杂的时空相关性,(2)时空相关性的多样性,每个location的POI和路网信息都不一样。提出deep-meta-learning模型(深度元学习),叫做ST-MetaNet,同时预测所有location的traffic,使用seq2seq架构,包含encoder来学习历史信息,decoder来一步接一步的预测,encoder和decoder有相同的架构,都包含RNN来编码历史traffic数据,一个meta graph attention来捕获各种的空间关系,一个meta RNN来考虑各种的时间相关性。
Introduction
ST相关性的Complex:
traffic随着location变化,不同的location,traffic也不同。同一个location,不同的时间点的traffic也不一样。构建一个geo-graph表示空间结构,节点:location,边:location之间的关系。
在空间上,一些location会相互影响,例如图1(a)中的$S3$发生了accident,那么$S1,S2,S4$可能会发生交通阻塞。
在时间上,一个location的traffic会受到recent或far时间的影响。例如$S4$举办一个演唱会,$S4$的inflow变大,并且会持续一段时间。ST相关性的Diversity:
在上面构建的geo-graph中,有节点特征和边特征。节点:location,节点特征:这个location的POI、路的密度。边:location之间的关系。边特征:location的连通性和距离。比如图1(b)和(c)中,$R1和R3$有相同的POI,都是商业区,$R2$是住宅区,所以它们的flow的时间模式也不一样。
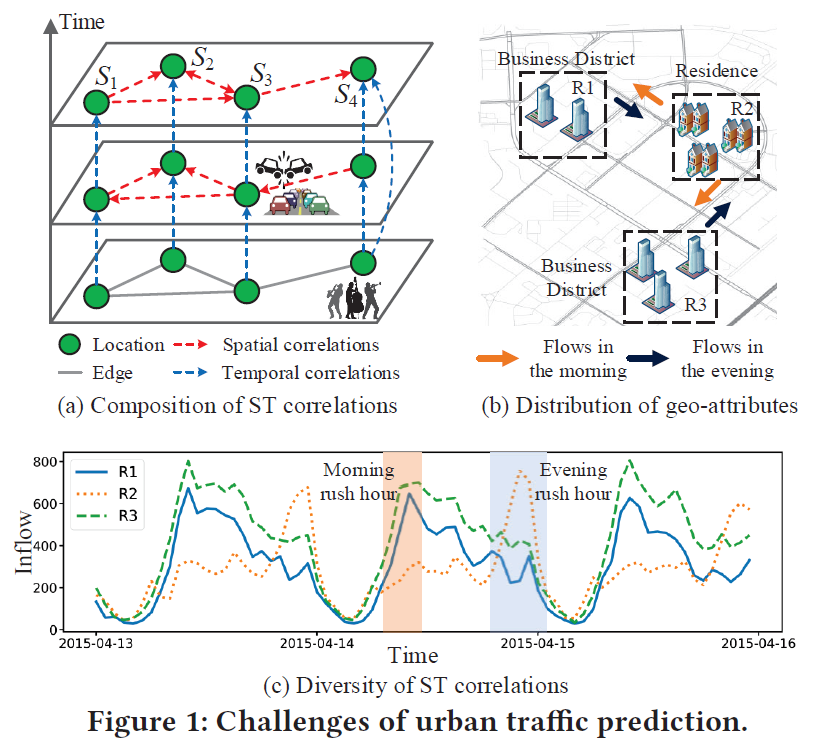
为了解决以上的挑战,提出ST-MetaNet,首先从geo-graph中的节点和边的特征中提取meta knowledge,从中生成预测网络的权重。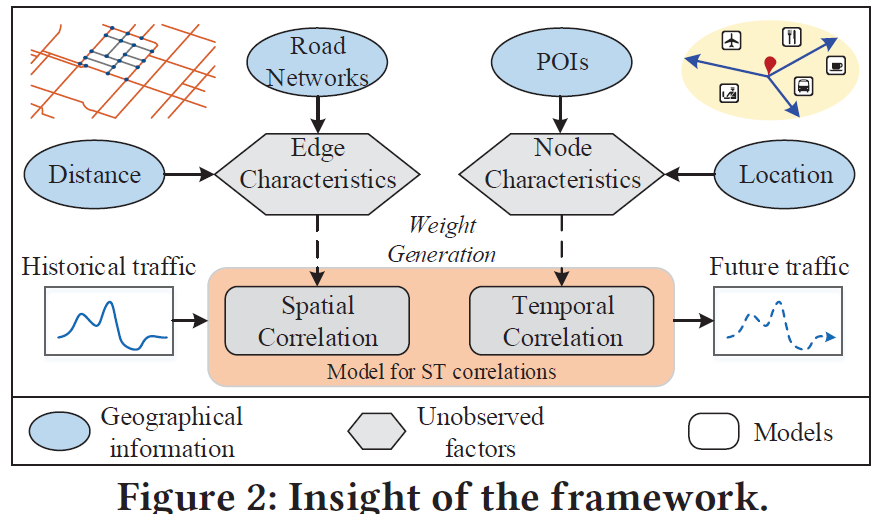
文章的贡献有4个:
(1)提出一个新颖的deep meta learning模型,预测城市traffic,ST-MetaNet利用从geo-graph中提取的meta knowledge,生成graph attention network和RNN seq2seq的权重。
(2)提出一个meta graph attention网络来建模空间相关性,Attention机制可以捕获location之间的动态关系,attention网络中的权重是从geo-graph的meta knowledge中提取出来的。
(3)提出meta gated RNN,生成
(4)在traffic flow和traffic speed做实验
Preliminaries
一共有$N_l个location,每个location有N_t个时间步,traffic一共有D_t类$
Ubran Traffic:可以表示为以下的张量
其中$X_{t}=\left(x_{t}^{(1)}, \ldots, x_{t}^{\left(N_{l}\right)}\right)$表示在时间步$t$所有区域的traffic信息。
Geo-Graph 特征:分为节点特征和边特征,其中 $G=\{\mathcal{V}, \mathcal{E}\}$ 表示一个有向图,$\mathcal{V} = \{v^{(1)},\ldots,v^{(N_l)}\}$表示所有节点,$\mathcal{E} = \{e^{(ij)} | 1 \leq i, j \leq N_l\}$表示所有的边,使用$\mathcal{N}_i表示节点i的邻居。$
问题定义:给定前$\tau_{in}$个时间段的$\left(X_{t-\tau_{i n}+1}, \ldots, X_{t}\right)$所有location在所有时间段的traffic特征,和geo-graph特征$\mathcal{G}$,预测在接下来$\tau_{out}$个时间段所有节点的traffic信息,表示为$\left(\hat{Y}_{t+1}, \ldots, \hat{Y}_{t+\tau_{o u t}}\right)$。
Methodologies
ST-MetaNet是Seq2Seq结构,由encoder(蓝色)和decoder(绿色)组成, encoder编码输入序列$\left(X_{t-\tau_{i n}+1}, \ldots, X_{t}\right)$,生成隐藏状态$\{H_{RNN},H_{Meta-RNN}\}$,用来初始化decoder的状态,预测输出序列$\left(\hat{Y}_{t+1}, \ldots, \hat{Y}_{t+\tau_{o u t}}\right)$。
encoder和decoder有相同的网络架构,包含以下4个组件。
(1)RNN:使用RNN来对历史traffic进行嵌入,捕获长期的时间依赖。
(2)Meta-knowledge learner:使用2个全连接FCNs,分分别叫做NMK-Learner和EMK-Learner,从节点特征(POI和GPS位置)和边特征(location的道路连通性和距离)学习meta-knowledge,得到的meta-knowledge用来学习GAT和RNN的权重。
(3)Meta-GAT:由Meta-Learner和GAT组成,使用FCN作为Meta-Learner,它的输入是所有节点和边的meta knowledge,输出是GAT的权重。Meta-GAT可以捕获多样的空间相关性。
(4)Meta-RNN:由Meta-Learner和RNN组成,Meta-Learner是FCN,输入是所有节点的meta knowledge,输出是每一个节点在RNN的权重,Meta-RNN可以捕获多样的时间相关性。
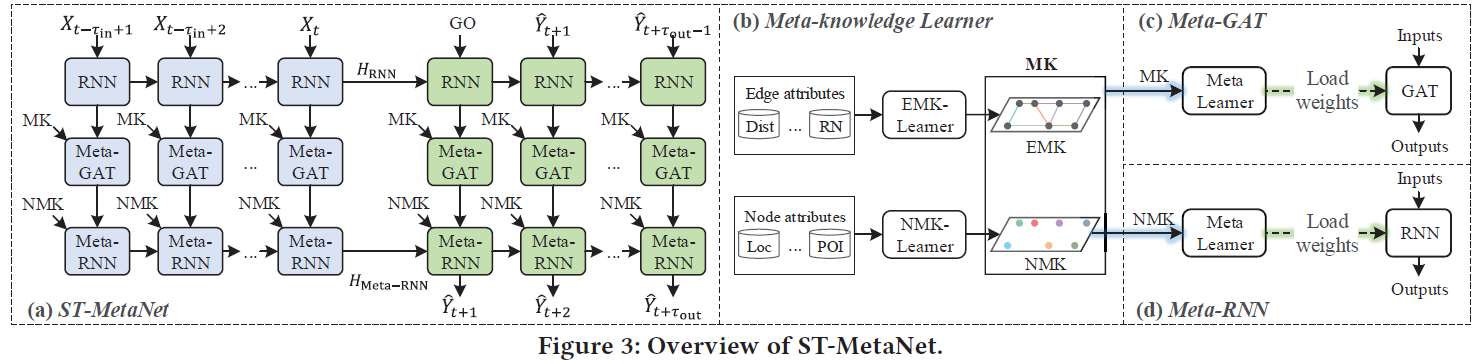
- RNN(GRU)组件
编码所有的location的traffic信息,RNN网络对所有的location共享相同的参数,每次GRU输入的是一个location所有时间步的traffic信息,输出这个location的隐藏状态,下一次再输入另一个location所有时间步的traffic,所有的location共享GRU的参数。GRU输出所有location的隐藏状态$H_{t}=\left(h_{t}^{(1)}, \ldots, h_{t}^{\left(N_{l}\right)}\right)$ - Meta-Knowledge Learner
提出2个meta-knowledge learner:NMK-Learner和EMK-Learner,就是2个FCN,输入是一个节点或一条边的特征,输出是节点或边的向量嵌入表示,这些嵌入表示被用来生成GAT和RNN的权重,捕获时空相关性。使用NMK$(v^{(i)})$和EMK$(e^{(ij)})$表示节点和边的嵌入表示。
4. 图卷积
4.1. Semi-Supervised Classification with Graph Convolutional Networks(2017ICLR)
4.2. Diffusion Convolutional Recurrent Neural Network Data-Driven Traffic Forecasting(2018ICLR)
4.3. Graph Attention Networks(2018ICLR)
4.4. Deeper Insights into Graph Convolutional Networks for Semi-Supervised Learning(2018AAAI)
5. Time Series Forecasting
5.1. Multi-Horizon Time Series Forecasting with Temporal Attention Learning(2019KDD)
5.2. Enhancing the Locality and Breaking the Memory Bottleneck of Transformer on Time Series Forecasting(2019NIPS)
6. traffic accident预测
6.1. Learning Deep Representation from Big and Heterogeneous Data for Traffic Accident Inference(2016AAAI)
在这篇论文中,使用数据:7个月的accident数据和1.6 million的用户GPS数据。使用堆叠降噪自编码器SDA来学习用户GPS的层次特征。这些特征被用来accidentrisk level的预测。这个模型一旦训练好,给定用户的移动轨迹,就可以模拟对应的accident risk地图。但是导致accident的因素很多。例如司机行为,天气,道路情况等。其他的研究尽管考虑到这些因素,但是没有揭示accidentrisk随着这些因素的变化。这篇论文的问题就是:能否通过实时的位置数据来评accident risk。商业和娱乐区有较高的accident risk,因为这些区域有较高的人流密度和人流量。accident因为受到很多因素的影响使得仅仅给定人类的移动情况,变得不好预测。因此我们推断一个accident的risk,而不是这次accident会不会发生。因为这是一个回归问题,而不是分类问题。
我们的模型利用降噪自编码器来学习人类移动的层次特征表示。在预测accident risk任务中,经过自编码器学出来的人类移动特征比原始数据更有效。最终,根据人类移动数据的实时输入,我们的模型可以仿真大规模的accident risk地图。有high risk的区域会高亮显示。
这篇论文的贡献有3个:
- 第一篇在城市级别上预测accident risk。
- 构造深度学习框架
- 在accident risk上的模拟是非常有效的。
使用的数据:
- traffic accident 数据。收集了三十万日本从2013.1.1~2013.7.31的traffic accident数据。每条记录包括事故发生的地点和小时,严重程度。其中严重程度被划分为3级,轻度受伤:1,重度受伤:2,致命:3
- 人类移动数据。收集了大约1.6million用户的GPS记录,在日本2013.1.1~2013.7.31。
accident的risk可以通过事故的频率和严重程度计算。定义risk level=每一个accident的严重程度的和。 时间划分:1个时间作为一个时间段,一天划分24个时间段。空间划分:每个区域500m*500m。时间索引t,空间索引r表示一个区域。即每1个小时统计一次risk level。 同时每小时统计一次该区域的人流密度density。risk level使用$g_{r,t}$表示,人流密度使用$d_{r,t}$表示。问题是通过$d_{r,t}$来预测$g_{r,t}$。每个区域每个时间段的(d,g)作为一个样本。
总结
- 没有考虑时间和空间特征,没有考虑外部因素
- 使用的特征太单一,只考虑区域的人流密度
6.2. A Deep Learning Approach to the Citywide Traffic Accident Risk Prediction(2018IEEE-ITSC)
traffic risk受很多因素的影响。例如不同的区域有不同的accident rate,天气因素,交通量,时间因素。本文结合
accident,traffic flow,天气,空气质量的历史短期和周期特征本文提出的模型用来预测短期的accident risk。和AAAI2016一样,本文是回归问题,预测accident risk。将accident分为3级。模型输入的特征是最近的traffic accident,traffic flow,weather,和air quality。最近指的是前几个小时或者昨天或者上星期。
将城市网格划分,每个网格区域1000m*1000m,每个时间段是30min或者60min。
这篇文章是预测一个区域未来n天的accident平均发生频率。输入有2个,第1个是这个区域历史n个时间段发生的accident的次数,第2个是这个区域的经纬度坐标。
这篇论文的前身《A Deep Learning Approach to the Prediction of Short-term Traffic Accident Risk》比这篇传入的特征更多,但是不明白为啥没中。
这篇文章说traffic accident具有day和week周期性。所以考虑了hour,day,week共3个级别的数据。这篇文章是预测1个区域的risk level,和上一篇不同,上一篇是预测frequency。这篇文章使用的特征有,accident risk,traffic flow,holiday,time period(处于1天的哪个时段,论文中将1天分为7个时段),weather,air quality。将这个区域的以上这6个特征拼接在一起,表示为$I_r(t)$。分别获取这个区域hour,day,week共3个级别的$I_r$,作为LSTM的时间步,每个时间步的特征个数是6个特征拼接起来形成的$I_r$。

