- 1. Suffle数据集
- 2. 归一化
- 3. batch_size
- 4. 划分数据集
- 5. 验证集的使用
- 6. 交叉验证
- 7. Conv输入和输出维度
- 8. 激活函数
- 9. GPU运行程序
- 10. 使用多GPU运行
- 11. NDArray和numpy
- 12. tensorboard使用
- 13. Dropout的使用
- 14. 调参经验
- 15. EarlyStopping
- 16. 卷积尺寸大小变化
- 17. 反卷积尺寸大小变化
- 18. 固定随机数种子
1. Suffle数据集
先划分数据集再shuffle。先将数据集划分成训练集、验证集、测试集。然后在DataLoader划分mini-batch时对训练集进行shuffle得到batch。对验证集和测试集不需要shuffle。不对训练集进行shuffle容易造成过拟合。
只对train进行shuffle,对val和test不进行shuffle
2. 归一化
先划分数据集,再归一化。将数据划分成训练集,验证集,测试集,然后计算训练集的平均值和标准差。使用训练集的平均值和标准差对验证集和测试集进行归一化。模型不应该知道关于测试集的任何信息,所以要用训练集的均值和标准差对训练集归一化。
划分数据集—>归一化—>对训练集shuffle
1 | from sklearn.model_selection import train_test_split |
一般都是把数据归一化成[0,1]或者减去均值除以标准化。默认是对每一列进行归一化,即axis=0。很少用sklearn的标准化方法,都是自己写一个方法用来标准化。
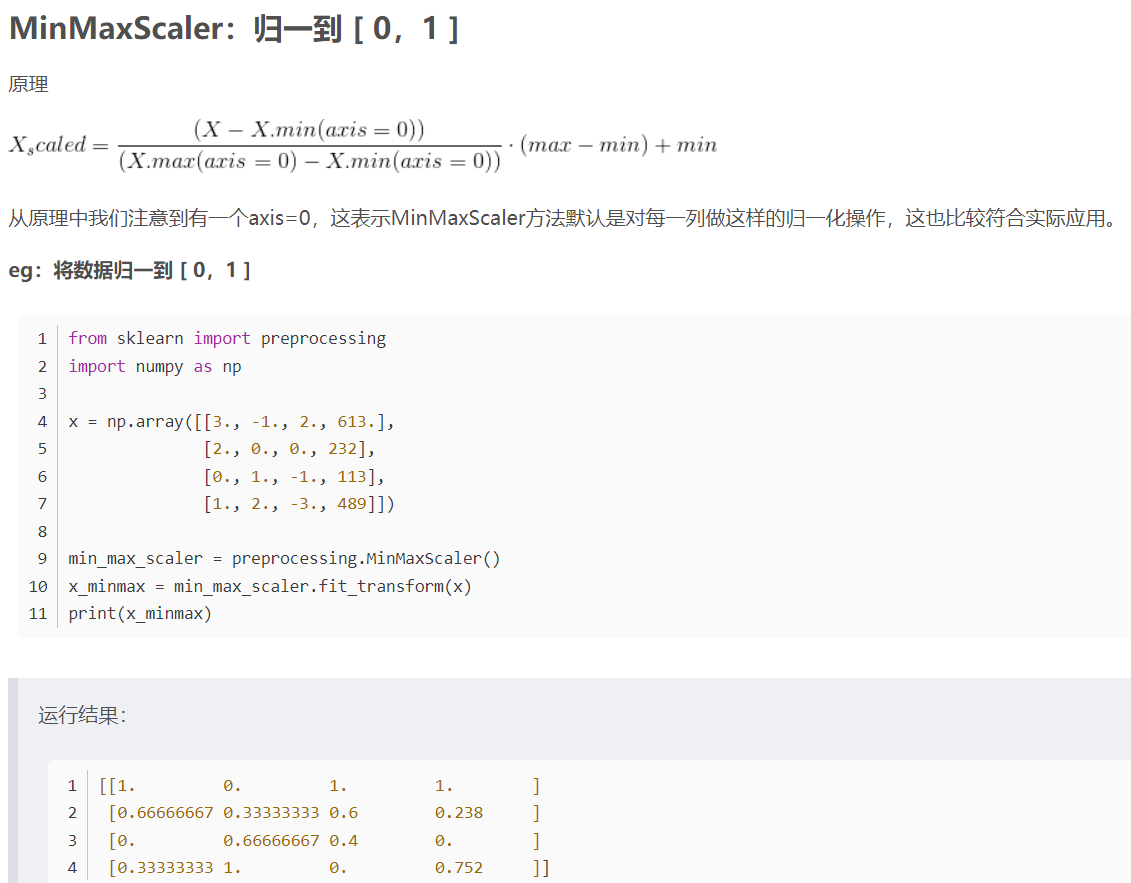
在实际中对train,val,test归一化有2种方法,
方法1:同时传入train,val,test参数,返回归一化后的trian,val,test和训练集的mean、std。
1 | def normalize(x): |
方法2:
如果使用(data-mean)/std进行标准化,需要计算train的平均值和标准差,但是怎么将train的平均值和标准差保留用在val和test上呢?下面自定义一个标准化的类
1 | class Scaler: |
然后在用到Scaler这个类时,scaler = utils.Scaler(train),则scaler对象则保留了train的平均值和标准差,使用scaler.mean和scaler.std即可以获得train的平均值和标准差。
1 | scaler = utils.Scaler(train) |
在计算loss时,不需要反归一化。在计算评价指标时需要反归一化。在计算评价指标时,比如RMSE,MAE等,首先根据归一化后的test_new得到预测结果predict,然后将predict根据scaler的inverse_transform反归一化,然后使用真实量级的predict和label再计算评价指标。
【注意】对特征和y归一化有2种方式:
- 只对特征进行归一化,y不进行归一化,模型预测的结果和真实y是同一量纲,模型的loss会偏大,计算评价指标时,不需要反归一化
- 对特征和y都归一化,y归一化到[0,1]之间,在计算loss时,不需要反归一化,loss相对方法1会偏小,在计算评价指标时,需要对真实y和预测y进行反归一化,再计算MAE等指标
关于上面是否需要对y进行归一化。如果模型收敛(loss一直在下降),可以不对y进行归一化。如果模型不收敛(数值过大),则需要对y进行归一化。
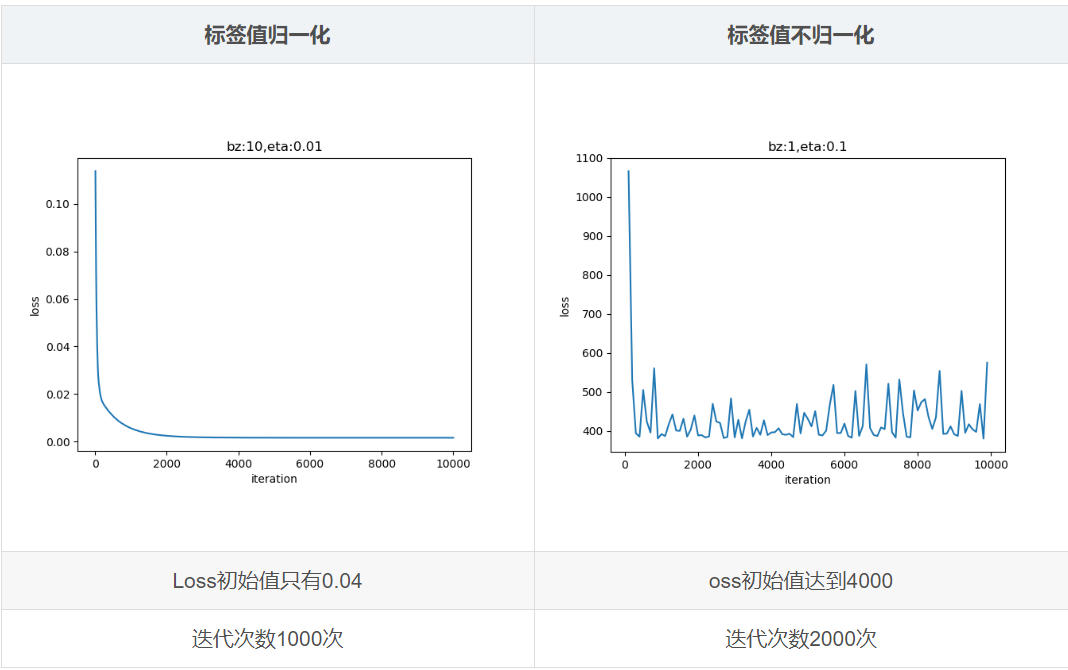
如果对y进行归一化,loss初始值很小,模型训练时很快就会收敛loss不再下降。不对y归一化,loss初始值很大,在训练过程中,训练很多轮loss才开始收敛,可能还会造成训练过程不稳定,loss上下震荡。
3. batch_size
当数据量较大时,向网络中传入所有的数据来计算loss和梯度,更新参数会造成内存溢出。所以每次向网络中值传入一个batch的数据,说过这一个batch的数据来更新权重,输出这个batch里面所有样本的平均loss。下次再使用另一个batch,更新网络参数,直到所有的数据全都输入,完成一个epoch。
4. 划分数据集
如果数据充足的情况下,通常采用均匀随机抽样的方法将数据集划分为3部分,训练集,验证集和测试集,这三个集合不能有交集,常见的比例是8:1:1,6:2:2。需要注意的是,通常都会给定训练集和测试集,而不会给验证集,一般的做法是从训练集中抽取一部分数据作为验证集。
5. 验证集的使用
在训练时,仅使用训练集的数据进行训练,使用验证集评价模型。当选中最好的模型超参数之后,再使用训练集+验证集来训练模型,以充分利用所有的标注数据,然后再测试集上测试
训练模型时,使用一个bacth来训练模型更新模型参数,记录下batch的loss。当训练完一个epcoh时,记录下模型的参数和梯度。并在验证集上计算验证集的误差,在测试集上计算测试集的MAE和MSE。
在训练的时候,每个batch记录训练的时间,
使用 tensorboard,训练模型时,每一个batch记录一下train_loss,每一个epoch记录一下模型梯度,在验证集上的loss和评价指标,在测试集上的loss和评价指标,和模型的参数(只保存在val上效果最好的那组参数,其余的删掉)。至于使用val的loss还是评价指标来选择最好的模型,这个需要自己选择
在模型训练的时候记录训练集/验证集/测试集的loss,以及验证集/测试集的评价指标。
为训练集,验证集,测试集创建3个SummaryWriter。
mxboard中log文件夹下的目录结构为:
—logs
$\qquad$—时间1文件夹
$\qquad\qquad$—train文件夹
$\qquad\qquad$—valid文件夹
$\qquad\qquad$—test文件夹
$\qquad$—时间2文件夹
$\qquad\qquad$—train文件夹
$\qquad\qquad$—valid文件夹
$\qquad\qquad$—test文件夹
1 | timestamp = datetime.now().strftime("%Y%m%d%H%M%S") |
ST-MetaNet这篇论文的代码在使用验证集验证的过程是:
- 在for循环中遍历所有的的epoch
- 在每个epoch中,使用训练集训练模型,使用该epoch训练的模型对val进行验证,记录当前模型在val的metric(eg. MAE,MSE)和该模型的参数。
- 进行下一个epoch,重复步骤2
- 等到所有的epoch都结束了,选出在val上MAE或MSE最好的那个epoch的模型参数,重新给model加载这个epoch的参数,对测试集进行测试,输出metrics。
即这篇的val是用来早停的,选出效果最好的epoch的模型参数。
ASTGCN这篇论文的代码在使用没有选出最好效果的epoch,而是每个epoch在val上计算loss。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19for epoch in range(epochs):
for batch in train_loader:
start_time = time()
output = model(input)
loss = loss_funtion(output,label)
loss.backward()
trainer.step(batch_size)
train_loss = loss.mean().asscalar()
#一个batch,使用sw记录train_loss
sw.add_scalar(train_loss)
print('每个batch需要的时间和train_loss')
#一个epoch,使用sw记录model的梯度
sw.add_histogram(param.grad())
#一个epoch,使用val进行验证,并使用sw记录val的loss
compute_val_loss(net, val_loader)
#一个epoch,计算test的metric,并使用sw记录test的MAE等值
compute_metrics(net,test_loader)
#一个epoch保存模型参数
net.save_param()完整代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57global_step = 1
for epoch in range(1, epochs + 1):
for train_w, train_d, train_r, train_t in train_loader:
start_time = time()
with autograd.record():
output = net([train_w, train_d, train_r])
l = loss_function(output, train_t)
l.backward()
trainer.step(train_t.shape[0])
training_loss = l.mean().asscalar()
sw.add_scalar(tag='training_loss',
value=training_loss,
global_step=global_step)
print('global step: %s, training loss: %.2f, time: %.2fs'
% (global_step, training_loss, time() - start_time))
global_step += 1
# logging the gradients of parameters for checking convergence
for name, param in net.collect_params().items():
try:
sw.add_histogram(tag=name + "_grad",
values=param.grad(),
global_step=global_step,
bins=1000)
except:
print("can't plot histogram of {}_grad".format(name))
# compute validation loss
compute_val_loss(net, val_loader, loss_function, sw, epoch)
# evaluate the model on testing set
evaluate(net, test_loader, true_value, num_of_vertices, sw, epoch)
params_filename = os.path.join(params_path,
'%s_epoch_%s.params' % (model_name,
epoch))
net.save_parameters(params_filename)
print('save parameters to file: %s' % (params_filename))
# close SummaryWriter
sw.close()
if 'prediction_filename' in training_config:
prediction_path = training_config['prediction_filename']
prediction = predict(net, test_loader)
np.savez_compressed(
os.path.normpath(prediction_path),
prediction=prediction,
ground_truth=all_data['test']['target']
)
6. 交叉验证
原先对交叉验证使用的数据集一直都理解错了。
参考资料
交叉验证使用的数据集是训练集,而不是全部的数据集。在交叉验证的时候把训练集分成K个集合,其中K-1份用来训练,1份用来验证。
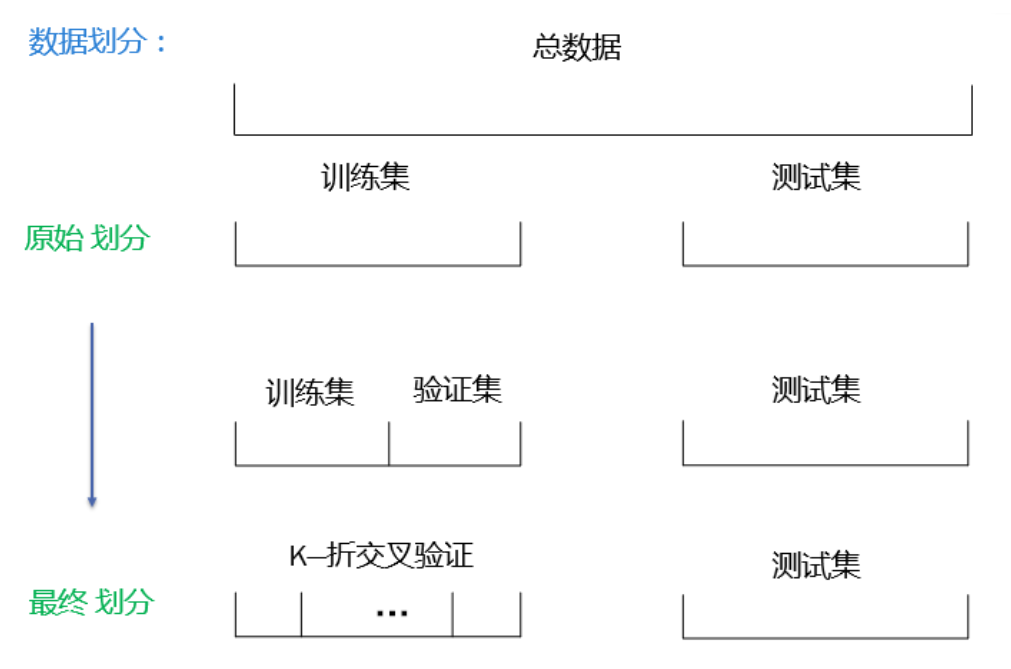
比如使用5折交叉验证,使用不同的5个训练集和测试集,训练得到5个模型,但是我们最后使用的模型并不是这5个模型中的一个。我们仍然认为这5个模型是一个模型,虽然参数不同,只是它们的输入不同而已。交叉验证只是为了验证这个模型的性能,交叉验证的目的并不是为了得到最终的模型。
假设我们有2个模型:线性回归和MLP。怎么说哪个模型更好呢?我们可以使用K折交叉验证来证明哪个模型更好,一旦我们选择了更好模型,例如MLP,那我们就用全部的数据来训练这个模型。
先使用网格搜索选择超参数,然后使用交叉验证输出这个模型的预测结果。
交叉验证有2个用处:
- 准确的调整模型的超参数。超参数不同模型就不同。使用交叉验证来选出最好的超参数。
- 比如分类问题,有多个算法,逻辑回归,决策树,聚类等方法,不确定使用哪个方法时,可以使用交叉验证。
7. Conv输入和输出维度
- 在gloun中Dense的输入是二维的,(batch_size,feature),比如输入是(64,120)表示一个batch有64个样本,每个样本有120个特征。如果训练集中的X不是二维的,可以使用reshape()将X变换成(-1,全连接输入单元个数)
- 卷积神经网络,卷积的输入和输出形状是
(batch_size,通道,高,宽),如果后面接的是全连接,就要转换成二维(batch_size,每个样本特征=通道\*高*宽),但是不需要人去手动转换形状,Dense会自动转换。如果是keras,从卷积层到全连接层,形状不会自动转变,所以需要自己加一个Flatten()层。 - 如果是一个分类问题,比如mnist数字识别,最后一层是一个神经单元个数为10的全连接层,然后把输送入到softmax,将每一行的10个值都变成在[0,1]之间小数。损失函数是交叉熵损失损失。在gluon中,最后一层Dense只需要指定输出神经单元个数即可,即
Dense(10),在预测的时候,输出predict,这时的predict并没有归一化到[0,1]的范围内,我们直接把predict和true_label输入到loss中,在loss函数中,才会对predict进行softmax计算,将predict归一化到[0,1]范围内。 在keras中,和gluon不同,会在最后一层的输出指定softmax激活函数,即
Dense(10,activation='softmax')。
循环神经网络的输入形状为
(时间步数,batch_size,特征个数)
通俗易懂的RNN图解
8. 激活函数
在使用激活函数的时候,一般都是
net.add(nn.Dense(10,activation=’relu’)),在定义层的时候直接加上activation,
也可以使用,但是不常用
net.add(nn.Dense(10),
nn.Activation(‘relu’)
)
或者net.add(nn.Conv2D(channels=6, kernel_size=5, activation=’sigmoid’))
只有当在该层和激活函数之间有其余的操作时,才会分开写,例如在卷积计算之后,激活函数之前加上批量归一化层,写成
1
2
3
4
5
6
7
net.add(nn.Conv2D(6, kernel_size=5),
BatchNorm(),
nn.Activation('sigmoid'))
或者
n.Dense(120),
BatchNorm(),
nn.Activation('sigmoid')
什么时候用激活函数
- 如果是回归问题,最后一层不需要激活函数(当然,如果数据归一化,可以加激活函数,也可以不加)
- 如果是分类问题,最后一层的激活函数使用sigmoid(二分类),softmax(多分类)
大部分问题上,使用Relu会得到较好的性能。现在已经很少使用sigmoid激活函数了,sigmoid函数的输出范围在[0,1]之间,x轴在[-5,5]之间的梯度非常高,当x在该范围之外时,梯度很好,接近于0,在反向传播时,容易出现梯度消失问题,无法完成深层网络的训练。
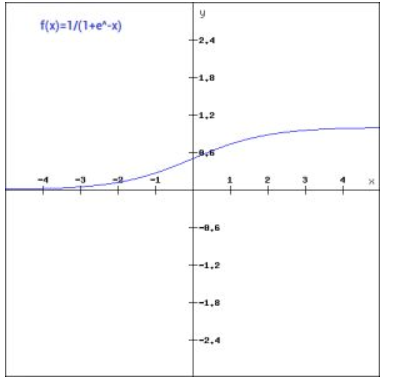
由于梯度消失问题,尽量避免使用sigmoid和tanh激活函数
- Relu是一个通用的激活函数,在大多数情况下都可以使用
- 注意:Relu只能在隐藏层中使用,不可以在输出层使用
- 使用softmax作为最后一层的激活函数时,前一层最好不要使用relu激活,而是使用tanh代替,否则最终的loss很可能变成nan
For the output units, you should choose an activation function suited to the distribution of the target values:
- For binary (0/1) targets, the logistic function is an excellent choice (Jordan, 1995).
- For categorical targets using 1-of-C coding, the softmax activation function is the logical extension of the logistic function.
- For continuous-valued targets with a bounded range, the logistic and tanh functions can be used, provided you either scale the outputs to the range of the targets or scale the targets to the range of the output activation function (“scaling” means multiplying by and adding appropriate constants).
- If the target values are positive but have no known upper bound, you can use an exponential output activation function, but beware of overflow.
- For continuous-valued targets with no known bounds, use the identity or “linear” activation function (which amounts to no activation function) unless you have a very good reason to do otherwise.
9. GPU运行程序
ctx=mx.gpu(2),下标从0开始
需要用到ctx的地方:
数据集需要放到gpu上。有2种方法。
(1)在创建数据的时候,指定ctx,在gpu上创建数据。1
2
3
4
5
6
7
8
9
10train_loader = gluon.data.DataLoader(
gluon.data.ArrayDataset(
nd.array(all_data['train']['week'], ctx=ctx),
nd.array(all_data['train']['day'], ctx=ctx),
nd.array(all_data['train']['recent'], ctx=ctx),
nd.array(all_data['train']['target'], ctx=ctx)
),
batch_size=batch_size,
shuffle=True
)(2)在训练的时候,使用as_in_context()将train_loader,val_loader,test_loader,数据拷贝到gpu上
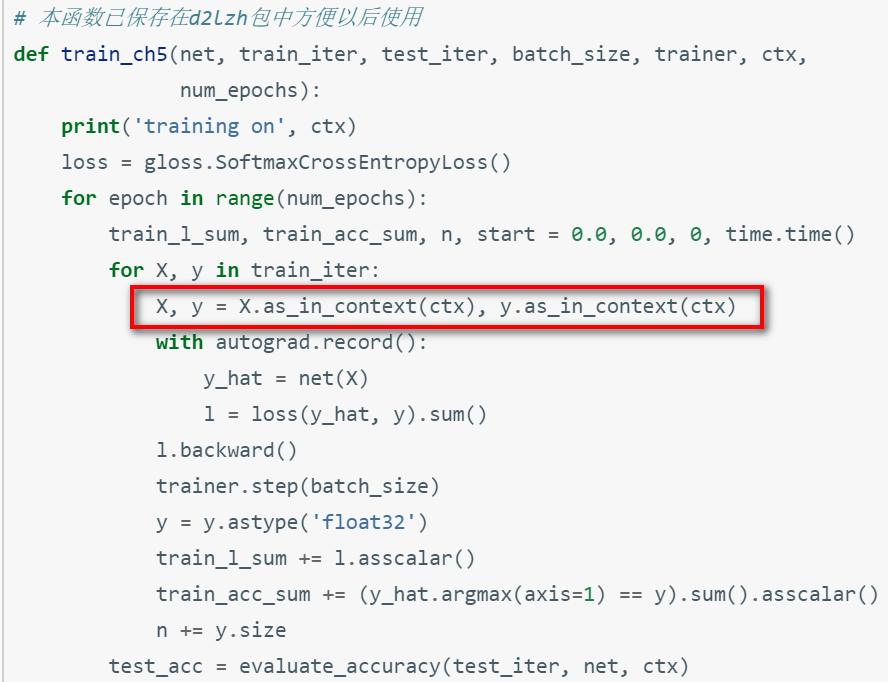
模型初始化的时候,通过ctx指定gpu设备,将模型参数初始化在gpu上。
1
2
3net = nn.Sequential()
net.add(nn.Dense(1))
net.initialize(ctx=mx.gpu())
10. 使用多GPU运行
假设ctx=[mx.gpu(1),mx.gpu(2)],则需要调整以下内容
(1)模型初始化,使用net.initialize(init=init.Normal(sigma=0.01), ctx=ctx)
(2)split_and_load函数,将一个batch_size的数据再次划分成子集,并复制到各个GPU上,比如batch_size=6,有2个GPU,那么每个GPU上有3个样本,
1 | x = nd.random.uniform(shape=(4, 1, 28, 28)) |
11. NDArray和numpy
使用gluon运行程序,gluon中的数据结构是NDArray,普通的python程序中的数据是numpy。什么时候用nd.array?什么时候用np.array?
- nd.array
- 在模型内部的运算,使用的都是nd。比如模型的数据输入,在创建DataLoader时,数据需要转换成nd.array()类型。
- 自定义的compute_val_loss()计算验证集的loss时,传入的数据是val_loader,是nd.array类型,但是在返回loss的时候,需要转换成np.array(),
- 自定义的evaluate计算数据,返回的值是np.array()
- np.array
- 在metrics.py中计算MSE,RMSE,MAE等指标时,输出和输出都是np.array类型。
nd.array和np.array转换
nd.array—>np.array:
1
2a = np.arange(10)
b = a.asnumpy()np.array—>nd.array
1
c = nd.array(b)
12. tensorboard使用
- 在训练集上每次epoch之后,验证模型在验证集上的平均loss,对验证集上的每个batch中的每个样本都求出一个loss,将所有样本的loss放在list中,最后求list的平均值得到验证集的平均loss。
- 在训练集上每次epoch之后,写一个evaluate函数,验证模型在测试集上的RMSE或MSE等指标。tensorboard中tag相同的会被显示在同一张图中。为了显示训练集,验证集和测试集的loss,tag都被设置为loss,但是SummaWriter的logdir不同
13. Dropout的使用
丢弃层会将隐藏单元中的值以一定的概率丢弃,即被设置为0,起到正则化的作用,用来应对过拟合。在测试模型时,为了拿到更加确定的结果,一般不使用丢弃法,只在训练模型下才使用dropout。在训练模型时,将靠近输入层的丢弃概率设的小一点。dropout一般放在全连接层后面
14. 调参经验
15. EarlyStopping
早停是在模型在val_loss,或者val_acc,val_mae等指标上进行。传入2个参数,patience和delta。
- 如果val_loss在连续patience epoch内,val_loss都大于最好的val_loss,即val_loss在增大,模型出现过拟合。
当前val_loss>最好的val_loss-delta,有2种情况
- 当前val_loss上升,counter+1
- val_loss虽然减少,但是减少很小,基本可以视为不变,counter+1
当前val_loss <= 最好的val_loss-delta,说明val_loss一直在下降,即更新最高的val_loss
- 总结:即val_loss在连续patience内,都没有显著下降(current_loss <= best_loss - delta),则停止训练
16. 卷积尺寸大小变化
- 2D卷积,输入和输出形状一样:一般kernel_size=(3,3),padding=1,stride=1,输入和输出的形状一样
- 2D卷积,输入和输出高和宽减半:kernel_size=(3,3),padding=1,stride=2,输出的形状是输入一半
- 3D卷积,一般kernel_size=(3,3,3),padding=1,stride=1,输入和输出的形状一样
- 3D卷积,一般kernel_size=(1,1,1),padding=0,stride=1,输入和输出的形状一样
17. 反卷积尺寸大小变化
2D反卷积
原先尺寸(batch_size,32,W,H)—>(batch_size,64,2W,2H)1
nn.ConvTranspose2d(in_channels=32, out_channels=64, kernel_size=3, stride=2, padding=1, out_padding=1),
原先尺寸(batch_size,32,W,H)—>(batch_size,64,W,H)
1
nn.ConvTranspose2d(in_channels=32, out_channels=64, kernel_size=3, stride=1, padding=1),
如果想让尺寸变化,从(W,H)—>(2W,2H),还可以使用下面方式
1
2nn.ConvTranspose2d(in_channels=32, out_channels=64, kernel_size=3, stride=1, padding=1),
nn.Upsample(scale_factor=2, mode='nearest'),
2020.2.4 更新
18. 固定随机数种子
mxnet版本
1
2
3
4seed = 2020
mx.random.seed(seed)
np.random.seed(seed)
random.seed(seed)pytorch版本
1
2
3
4
5
6seed = 2020
torch.manual_seed(seed) # cpu
torch.cuda.manual_seed(seed) #gpu
torch.backends.cudnn.deterministic=True#cudn,cpu/gpu结果一致
np.random.seed(seed)#numpy
random.seed(seed)#ramdom

