最近在做一个分类任务,根据电池的充放电数据,预测电池绝缘报警是否为虚报,就是一个二分类任务。这里使用逻辑回归进行分类。
1. 数据预处理
在进行模型训练之前,需要对数据进行预处理。因为多个特征之间的量纲不同,在训练的时候收敛会很慢,所以需要将不同特征值转换为同一量纲。这里将离散特征和连续特征分别处理。
1.1. 特征值连续
对于连续值的预处理主要分为2个:归一化和标准化。这2个操作主要是为了使得不同的特征在同一个量纲,对目标的影响是同级的。归一化和标准化都是先对数据先缩小一定的比例,然后再平移。这2者本质上都是对数据进行线性变换,线性变换不会改变原始数据的数值大小排序。即一个数在原始数据最大,经过归一化和标准化这个数还是最大。这篇博客。
将特征值缩放到相同的区间可以获得性能更好的模型。就梯度下降而言,一个特征值的范围在1-10之间,另一个特征值范围在1-10000之间,训练的目标是最小化平方误差,所以在使用梯度下降算法的过程中,算法会明显偏向第二个特征,因为它的取值范围更大。在K近邻算法中,使用的欧式距离,也会导致偏向第二个特征。对于决策树和随机森林以及xgboost算法而言,特征缩放对它们没有什么影响,像逻辑回归和支持向量机算法和K近邻,需要对数据进行特征缩放。 在分类,聚类算法中,需要使用距离来度量相似性的时候,standardization表现更好。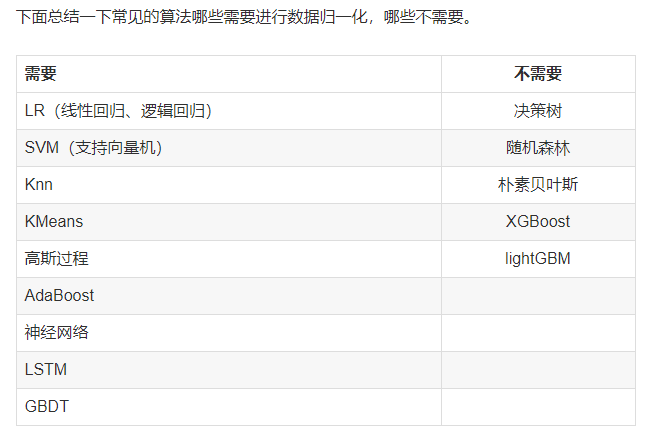
1.1.1. 归一化(normalization)
归一化将每一个属性值映射到[0,1]之间。需要计算训练集的最大值和最小值,当有新样本加入时,需要重新计算最值。
- 特点:多使用于分布有明显边界的情况,如考试成绩,身高,颜色的分布等,都有明显的范围边界,不适用没有范围约定,或者返回非常大的数据。
- 缺点:受异常值影响较大。归一化的缩放就是将数据拍扁统一到一个区间中,仅有极值决定,而标准化的缩放更加弹性和动态,和整体的分布有关。归一化只用到了最大值和最小值,而标准化和每一个值有关。

1.1.2. 标准化(standardization)
标准化又叫做Z-score。将所有的数据映射到均值为0,方差为1的正态分布中。 要求原始数据的分布可以近似为正态分布,否则标准化的结果会很差。 标准化表示的是原始值与均值之间差几个标准差,是一个相对值,也有去除量纲的作用,同时还有2个附加好处:均值为0,标准差为1。均值为0的好处是使得数据以0为中心左右分布。
- 适用范围:在分类和聚类算法中,需要使用距离来度量相似性时,例如支持向量机,逻辑回归,或者使用PCA进行降维时,Z-score表现更好。
- 推荐先使用标准化。

1.1.3. RobustScaler
在某些情况下,加入数据中有离群点,可以使用standardization进行标准化,但是标准化后的数据并不理想,因为异常点的特征往往在标准化后容易失去离群特征,此时就要使用RobustScaler针对离群点进行标准化处理 。此方法对数据中心化和缩放健壮性有更强的参数控制能力。
1 | #RobustScaler标准化 |
1.2. 特征值离散
离散值就是特征值是离散的,不是连续的,例如性别是离散值,只有female和male,颜色是离散的。机器学习算法不能直接处理离散值,需要对其进行一些转换。离散值可以是文本(red,black)或者数值(1,2)。
离散数据有2大类:定序(Ordinal)和定类(Nominal)。定序的数据存在一定的顺序意义,例如衣服的尺寸按大小分类(xs,s,m,l),在定类的数据中,属性值之间没有顺序的要求。
对于定序的数据,没有统一的模块将这些顺序自动转换成映射,可以自定义一些映射规则,比如xs对应1,s对应2,自定义的规则。
对于文本的定类数据,可以先把文本分类至转换为数字,比如red转换为1,black转换为2,然后对这些数据使用one-hot编码。
主要是使用LabelEncoder和OneHotEncoder这2个模块。
1 | from sklearn.preprocessing import LabelEncoder |
除了sklearn中的OneHotEncoder,还可以使用pandas中的get_dummies对离散值进行one-hot编码,比OneHotEncoder好的一点是:转换之后可以直观的看出当前列对应哪个属性。
参考博客:
https://blog.csdn.net/wotui1842/article/details/80697444
https://blog.csdn.net/cymy001/article/details/79154135
https://blog.csdn.net/m0_37324740/article/details/77169771
https://blog.csdn.net/wxyangid/article/details/80209156
1.3. 预处理步骤
- 首先使用pandas从csv中读取数据,从数据中取出特征值和目标值,分别存储在X和Y中。
- 从X中取出离散特征值dis_feature,剩下的是连续特征值con_feature。
- 对离散特征值dis_feature进行one-hot编码,形成新的特征值new_dis_feature。然后将新的特征值new_dis_feature和原先的连续特征值con_feature进行拼接形成新的特征值new_X
- 然后对new_X和Y划分为训练集和测试集,然后对训练集进行标准化,使用训练集的均值和标准差再对测试集进行标准化。
- 使用训练集对模型进行训练,对测试集进行验证。
1.4. 交叉验证
sklearn中有2中交叉验证方法,KFold,StratifiedKFold
1 | from sklearn.model_selection import KFold,StratifiedKFold |
StratifiedKFold和KFold类似,但是StratifiedKFold是分层采样,确保训练集、测试集各类样本的比例与原始数据集中相同。比如原始数据集中正例:负例=2:1,则训练集和测试集中正例:负例=2:1。
KFold和enumerate联合使用
enumerate()函数用于将一个可遍历的数据对象(如列表,元组或str)组合成一个序列索引,同时列出数据和数据下标。一般在for循环中使用。
语法:enumerate(sequence,[start=0])
其中sequence表示一个序列,迭代器或可遍历对象,start表示下标起始位置
1 | for fold_, (train_, test_) in enumerate(kfold.split(X_array, y_array): |
1.5. 特征工程
- 特征缩放
使用归一化或标准化对特征进行缩放,使得不同特征值在同一量纲
1 | #使用 sklearn中的 scale 函数 |
1 | #Since most of our data has already been scaled we should scale the columns that are left to scale (Amount and Time) |
- 解决样本不均衡问题
欠采样或过采样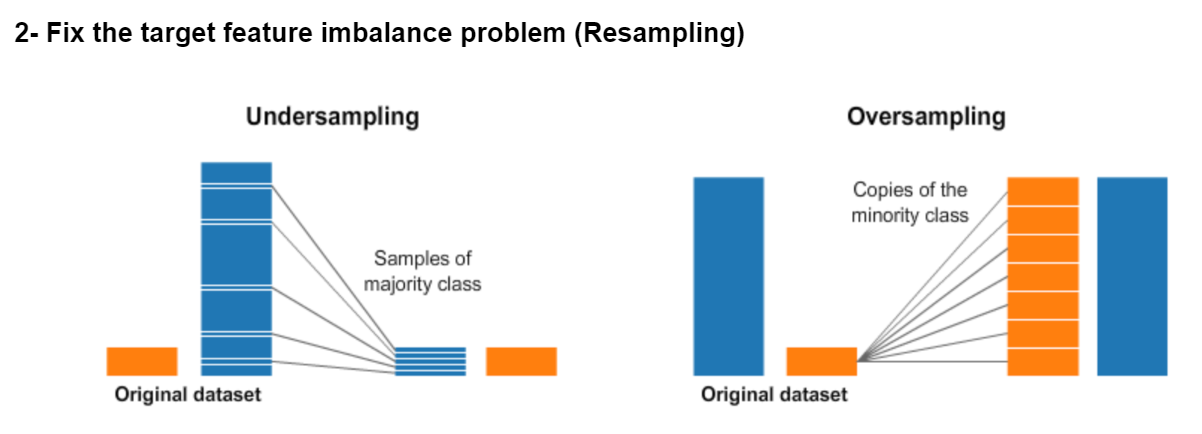
检测和删除异常点
划分数据集
划分数据集:训练集,验证集,测试集
2. 模型评价指标
- 拟合模型
model.fit(X_train, y_train) - 模型预测,对于分类任务,输出最大可能的类别
model.predict(X_train)model.predict(X_test) - 对于分类任务,输出所属每个类别的概率,返回的是一个二维数组,每一行加起来为1
prob = model.predict_proba(X_train)model.predict_proba(X_test)
获取样本属于正例的概率prob[:,1] - 获得这个模型的参数
model.get_params() - 为模型进行打分
线性回归问题返回预测的确定系数R2
逻辑回归(分类)根据给定数据与标签返回分类准确率的均值model.score(X_train, y_train)model.score(X_test, y_test) - 计算分类准确率,和score返回值一样
train_predicted = model.predict(X_train)model.accuracy_score(y_train.flatten(),train_predicted) - 返回分类准确率,和上面的结果一样
np.mean(train_predicted == y_train)np.mean(test_predicted == y_test) 召回率
1
2precision, recall, F1, _ = precision_recall_fscore_support(y_test, pred_test, average="binary")
print ("精准率: {0:.2f}. 召回率: {1:.2f}, F1分数: {2:.2f}".format(precision, recall, F1))AUC&&ROC
只针对二分类。通过model.predict_proba(X_test)[:,1]可以获取测试集属于正例的概率,将预测概率从大到小排序,然后以每个预测概率作为阈值,即可得到属于2类的样本数。对应计算每个阈值下的”False Positive Rate”(FPR)和”True Positive Rate”(TPR),以”False Positive Rate”为横轴,以”True Positive Rate”为纵轴,画出ROC曲线,ROC曲线下的面积就是AUC值.
“False Positive Rate”(FPR)=负例被划分为正例个数/真正负例个数(负例被分错的个数/真正负例)
“True Positive Rate”(TPR)=正例被划分为正例/真正正例个数(正例被分对的个数/真正正例)
当阈值取最大时,所有的样本被分为负样本,对应(0,0),当阈值取最小时,所有的样本被分为正样本,对应于(1,1),随着阈值从最大到最小变化,横坐标和纵坐标都在变大,表示被划分为正例的个数越来越多。
AUC用来衡量ROC曲线的好坏。如果分类器能完美的将样本分对,那么AUC=1,如果模型是随机猜测的,那么AUC=0.5,对应着y=x直线。分类器越好,则AUC越大。
sklearn给了画ROC曲线的函数。1
2
3
4
5
6
7fpr, tpr, thresholds=sklearn.metrics.roc_curve(y_true_label,y_prob,pos_label=None,sample_weight=None,drop_intermediate=True)
#其中test_true_label表示数据集真实的标签,{0,1}或{-1,1}
#y_prob表示数据集被分为正例的概率
# 返回值
#thresholds: array, shape = [n_thresholds]所选取的不同的阈值,按照从大到小的排序,阈值越大,横纵坐标越小。
#fpr,tpt:根据 thresholds算出来的横坐标和纵坐标。在此基础上可以画ROC曲线,
#通过auc(fpr,tpr)可以求出AUC的值
3. GridSearchCV
1 | class sklearn.model_selection.GridSearchCV(estimator, param_grid, scoring=None, fit_params=None, n_jobs=1, iid=True, refit=True, cv=None, verbose=0, pre_dispatch=‘2*n_jobs’, error_score=’raise’, return_train_score=’warn’) |
GridSearchCV参数介绍:
- estimator:使用的分类器,并且传入除需要确定最佳的参数之外的其他参数
- param_grid:值为字典或者列表,即需要最优化的参数的取值,param_grid = {‘n_estimators’:list(range(10,71,10))}
- scoring :准确度评价标准,默认None,表示“GridSearchCV”与“cross_val_score”都会去调用“estimator”自己的“score”;或者如scoring=’roc_auc’,根据所选模型不同,评价准则不同。字符串(函数名),或是可调用对象,需要其函数签名形如:scorer(estimator, X, y);如果是None,则使用estimator的误差估计函数。scoring参数选择如下:
cv :交叉验证参数,默认None,使用三折交叉验证。指定fold数量,默认为3,传入的参数可以是int型,也可以是yield训练/测试数据的生成器。
1
2kflod = StratifiedKFold(n_splits=10, shuffle = True,random_state=7)#将训练/测试数据集划分10个互斥子集,
grid_search = GridSearchCV(model,param_grid,scoring = 'neg_log_loss',n_jobs = -1,cv = kflod)
- refit :默认为True,程序将会以交叉验证训练集得到的最佳参数,重新对所有可用的训练集与开发集进行,作为最终用于性能评估的最佳模型参数。即在搜索参数结束后,用最佳参数结果再次fit一遍全部数据集。
- iid:默认True,为True时,默认为各个样本fold概率分布一致,误差估计为所有样本之和,而非各个fold的平均。
- verbose:日志冗长度,int:冗长度,0:不输出训练过程,1:偶尔输出,>1:对每个子模型都输出
- n_jobs: 并行数,int:个数,-1:跟CPU核数一致, 1:默认值。
常用的方法
- grid.fit(X, y=None, groups=None, **fit_params):运行网格搜索,与所有参数组合运行。
cv_results_:旧版本是“grid_scores_”,cv_results_是详尽、升级版。内容较好理解,包含了’mean_test_score’(验证集平均得分),’rank_test_score’(验证集得分排名),’params’(dict形式存储所有待选params的组合),甚至还有在每次划分的交叉验证中的得分(’split0_test_score’、 ‘split1_test_score’等),就是输出的内容稍显臃肿。内容以dict形式输出,我们可以转成DataFrame形式,看起来稍微养眼一点。
1
cv_result = pd.DataFrame.from_dict(clf.cv_results_)
1
2
3
4means = grid_result.cv_results_['mean_test_score']
params = grid_result.cv_results_['params']
for mean,param in zip(means,params):
print("%f with: %r" % (mean,param))1
2from IPython.display import display
display(pd.DataFrame(grid.cv_results_).T)参考资料:https://blog.csdn.net/sinat_32547403/article/details/73008127
- best_estimator_ : estimator或dict;由搜索选择的估算器,即在左侧数据上给出最高分数(或者如果指定最小损失)的估算器。 如果refit = False,则不可用。
- best_params_ : dict;在保持数据上给出最佳结果的参数设置。对于多度量评估,只有在指定了重新指定的情况下才会出现。
- best_score_ : float;best_estimator的平均交叉验证分数,对于多度量评估,只有在指定了重新指定的情况下才会出现。
- get_params([deep]):这个和‘best_estimator_ ’这个属性相似,但可以得到这个模型更多的参数
- inverse_transform(Xt)使用找到的最佳参数在分类器上调用inverse_transform。
- predict(X)调用使用最佳找到的参数对估计量进行预测,X:可索引,长度为n_samples;
- score(X, y=None)返回给定数据上的分数,X: [n_samples,n_features]输入数据,其中n_samples是样本的数量,n_features是要素的数量。y: [n_samples]或[n_samples,n_output],可选,相对于X进行分类或回归; 无无监督学习。
1 | cv_params = {'n_estimators': [100, 125, 150, 175, 200]} |
网格搜索建立在交叉验证的基础上。交叉验证将训练集分成N份,其中N-1份做训练,1份做测试。先选定一个待验证的参数,然后做N次训练和测试,得到平均值,然后再选定下一个参数,做N次训练和测试。
4. 样本不均衡问题
分类问题时,样本不均衡,正例和负例的样本数不均衡,为了实现样本均衡,需要对样本比较少的那类数据进行过采样。
一文教你如何处理不平衡数据集

