- 1. 重要概念和术语
- 2. 执行模式
- 3. 创建sc
- 4. RDD转换
- 5. 分区
- 6. 创建RDD
- 7. map和flatMap
- 8. flatMap和flatMapValues
- 9. reduceByKey和groupByKey
- 10. sortBy和SortByKey
- 11. 将Spark计算的结果存储在文件中
1. 重要概念和术语
- Master和Worker是物理节点,Driver和Executor是进程。
搭建Spark集群的时候我们就已经设置好了Mater节点和Worker节点。一个集群有多个Master节点和多个Worker节点。
Master节点常驻Mater守护进程,负责管理worker节点,我们从master节点提交应用。
Worker节点常驻Worker守护进程,与Master节点通信,并且管理Executor进程。
PS:一台机器可以同时作为master和worker节点(举个例子:你有四台机器,你可以选择一台设置为master节点,然后剩下三台设为worker节点,也可以把四台都设为worker节点,这种情况下,有一个机器既是master节点又是worker节点) Driver / Driver Program
运行main函数并且创建SparkContext的程序。客户端的应用程序,Driver Program类似于wordcount程序中的mian函数。
当我们提交应用程序后,便会启动一个对应的Driver进程。Driver会根据我们设置的参数占用一定的资源(主要是CPU核数、内存)。
程序启动时,Driver进程首先会向集群资源管理者(Standalone,Mesos,Yarn)申请Spark应用所需的资源,也就是Executor,然后集群管理者会根据Spark应用所设置的参数在各个Worker上分配一定数量的Executor,每个Executor都占用一定数量的CPU和Memory。在申请到应用所需的资源后,Driver就开始调度和执行我们的程序了。Driver进程会把我们编写的Spark程序拆分成多个stage,每个stage执行一部分代码片段,并为每个stage创建一批task,然后将这些task分配到各个Executor中执行。
Executor进程在Worker节点上,一个Worker可以有多个Executor,每个Executor都有一个进程池,每个进程执行一个task。Executor执行完task之后将结果返回给Driver,每个Executor执行的task属于一个spark程序。此外Executor还有一个功能是为应用程序中的RDD提供内存,RDD是直接缓存在Executor进程内的。
这篇博客讲的很好1
spark-submit --master yarn --num-executors 32 --executor-memory 8G --executor-cores 8 --jars ../jars/spark-examples_2.10_my_converters_test-1.6.0.jar spark_streaming_all.py
其中参数的含义:
- num-executors:创建多少个 executor
- executor-memory:各个 executor 使用的最大内存,不可超过单机的最大可使用内存
- executor-cores:各个 executor 使用的并发线程数目,也即每个 executor 最大可并发执行的 Task 数目
- Cluster Manager
集群的资源管理器,在集群上获取资源的外部服务,例如Standalone,Mesos,Yarn。
拿Yarn举例,客户端程序会向Yarn申请运行我这个任务需要多少,多少CPU等,然后Cluster Manager会通过调度告诉客户端可以使用,然后客户端就可以把程序送到每个Worker Node上面执行。
2. 执行模式
运行spark程序有3种模式,local,standalone,yarn。在使用spark-submit命令提交程序时,需要指定一些参数。
- —master:如spark://host:7077, mesos://host:port, yarn, yarn-cluster,yarn-client, local
- —calss CLASS_NAME 应用程序的主类
- —name NAME 应用程序的名称,这个可以在程序中通过setAppName(“kafka_hbase”)指定
- —jars JARS 逗号分隔的本地jar包,后面添加jar的路径
- —driver-memory MEM Driver内存,默认1G
- —num-executors NUM,启动的executor的个数,默认为2,在yarn中使用。
- —executor-core NUM,每个executor的核数。在yarn或者standalone下使用
- —executor-memory MEM 每个executor的内存,默认是1G
- —total-executor-cores NUM,所有executor总共的核数,仅仅在mesos或standalone中使用
- driver-cores NUM Driver的核数,默认是1,这个参数只在standalone模式下使用
2.1. standalone模式
运行一个pyspark程序,使用standalone模式来提交程序,需要使用的参数有:
- —master spark://hz4:7077
- —jars xxx1.jar,xxx2.jar
不使用—num-executors,这个在yarn中使用 - —executor-memory MEM,每个executor占用的内存,如果一个executor占用4G,有5个executor,那这个程序占用20G
- —executor-core NUM,表示每个executor的核数
- —total-executor-cores NUM,所有的executor占用的核数。使用total-executor-cores / executor-core得到executor的个数,假设total-executor-cores设置为30,executor-core为6,则表示运行这个程序一共有5个executor,分别在不同worker上。一个worker可以有多个executor。 假设有5个executor,2个worker,那么一个worker上有多个executor。如果不指定—total-executor-cores,程序会把worker上的核全都占用,这样别人提交程序的时候就没有办法运行。
运行一个程序的命令:spark-submit —master spark://hz4:7077 —executor-memory 4G —executor-cores 6 —total-executor-cores 30 —jars ../jars/spark-examples_2.10_my_converters-1.6.0.jar spark_streaming.py
2.2. Yarn模式
yarn模式可以用的参数有:
- —master yarn
- —jars xxx1.jar,xxx2.jar
- —num-executors NUM, 启动的executor的个数,默认为2,不要使用默认,会很慢。在yarn中使用。yarn资源管理器会在不同的worker上分配executor给程序。
- —executor-memory MEM,每个executor占用的内存,如果一个executor占用4G,有5个executor,那这个程序占用20G
- —executor-core NUM,表示每个executor的核数,如果有5个executor,每个executor占用4G,那这个程序运行时占用20G内存。
运行一个程序的命令:spark-submit --master yarn --num-executors 20 --executor-memory 4G --executor-cores 4 --jars ../jars/spark-examples_2.10_my_converters-1.6.0.jar spark_streaming.py
2.3. 参数调优
num-executors:该参数用于设置Spark作业总共要用多少个Executor进程来执行,Driver在向YARN集群管理器申请资源时,YARN集群管理器会尽可能按照你的设置来在
集群的各个工作节点上,启动相应数量的Executor进程。
参数调优建议:
每个Spark作业的运行一般设置50~100个左右的Executor进程比较合适,设置太少或太多的Executor进程都不好。设置的太少,无法充分利用集群资源;
设置的太多的话,大部分队列可能无法给予充分的资源。executor-memory:该参数用于设置每个Executor进程的内存。Executor内存的大小,很多时候直接决定了Spark作业的性能,而且跟常见的JVM OOM异常,也有直接的关联。
参数调优建议:
每个Executor进程的内存设置4G~8G较为合适。但是这只是一个参考值,具体的设置还是得根据不同部门的资源队列来定。可以看看自己团队的资源队列
的最大内存限制是多少,num-executors乘以executor-memory,是不能超过队列的最大内存量的。此外,如果你是跟团队里其他人共享这个资源队列,
那么申请的内存量最好不要超过资源队列最大总内存的1/3~1/2,避免你自己的Spark作业占用了队列所有的资源,导致别的同学的作业无法运行。executor-cores:该参数用于设置每个Executor进程的CPU core数量。这个参数决定了每个Executor进程并行执行task线程的能力。因为每个CPU core同一时间只能执行一个
task线程,因此每个Executor进程的CPU core数量越多,越能够快速地执行完分配给自己的所有task线程。
参数调优建议:
Executor的CPU core数量设置为2~4个较为合适。同样得根据不同部门的资源队列来定,可以看看自己的资源队列的最大CPU core限制是多少,再依据设置的
Executor数量,来决定每个Executor进程可以分配到几个CPU core。同样建议,如果是跟他人共享这个队列,那么num-executors * executor-cores不要超过
队列总CPU core的1/3~1/2左右比较合适,也是避免影响其他同学的作业运行。driver-memory:该参数用于设置Driver进程的内存。
参数调优建议:
Driver的内存通常来说不设置,或者设置1G左右应该就够了。唯一需要注意的一点是,如果需要使用collect算子将RDD的数据全部拉取到Driver上进行处理,
那么必须确保Driver的内存足够大,否则会出现OOM内存溢出的问题。—conf spark.default.parallelism:该参数用于设置每个stage的默认task数量。这个参数极为重要,如果不设置可能会直接影响你的Spark作业性能。
参数调优建议:
Spark作业的默认task数量为500~1000个较为合适。很多同学常犯的一个错误就是不去设置这个参数,那么此时就会导致Spark自己根据底层HDFS的block数量
来设置task的数量,默认是一个HDFS block对应一个task。通常来说,Spark默认设置的数量是偏少的(比如就几十个task),如果task数量偏少的话,就会
导致你前面设置好的Executor的参数都前功尽弃。试想一下,无论你的Executor进程有多少个,内存和CPU有多大,但是task只有1个或者10个,那么90%的
Executor进程可能根本就没有task执行,也就是白白浪费了资源!因此Spark官网建议的设置原则是,设置该参数为num-executors * executor-cores的2~3倍
较为合适,比如Executor的总CPU core数量为300个,那么设置1000个task是可以的,此时可以充分地利用Spark集群的资源。
2.4. Executor
在运行pyspark程序时出错: Container killed by YARN for exceeding memory limits. 16.9 GB of 16 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead”这个错误总会使你的job夭折。它的意思是:因为超出内存限制,集群停掉了container。
Spark的Excutor的Container内存有两大部分组成:Excutor内存和堆外内存
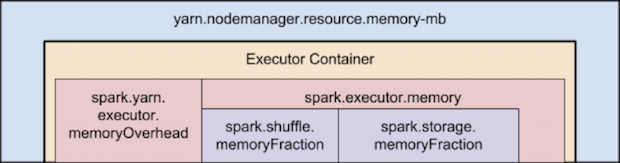
Spark底层shuffle的传输方式是使用netty传输,netty在进行网络传输的过程会申请堆外内存(netty是零拷贝),所以使用了堆外内存,即spark.yarn.executor.memoryOverhead。
Executor内存
又spark.executor.memory参数设置,在spark-shell中由—executor-memory指定,分为2部分,shuffle.memoryFraction和storage.memoryFraction。
spark.shuffle.memoryFractio
该参数用于设置shuffle过程中一个task拉取到上个stage的task的输出后,进行聚合操作时能够使用的Executor内存的比例,默认是0.2。也就是说,Executor默认只有20%的内存用来进行该操作。shuffle操作在进行聚合时,如果发现使用的内存超出了这个20%的限制,那么多余的数据就会溢写到磁盘文件中去,此时就会极大地降低性能。
参数调优
如果Spark作业中的RDD持久化操作较少,shuffle操作较多时,建议降低持久化操作的内存占比,提高shuffle操作的内存占比比例,避免shuffle过程中数据过多时内存不够用,必须溢写到磁盘上,降低了性能。此外,如果发现作业由于频繁的gc导致运行缓慢,意味着task执行用户代码的内存不够用,那么同样建议调低这个参数的值。spark.storage.memoryFractio
该参数用于设置RDD持久化数据在Executor内存中能占的比例,默认是0.6。也就是说,默认Executor 60%的内存,可以用来保存持久化的RDD数据。根据你选择的不同的持久化策略,如果内存不够时,可能数据就不会持久化,或者数据会写入磁盘。
参数调优
如果Spark作业中,有较多的RDD持久化操作,该参数的值可以适当提高一些,保证持久化的数据能够容纳在内存中。避免内存不够缓存所有的数据,导致数据只能写入磁盘中,降低了性能。但是如果Spark作业中的shuffle类操作比较多,而持久化操作比较少,那么这个参数的值适当降低一些比较合适。此外,如果发现作业由于频繁的gc导致运行缓慢(通过spark web ui可以观察到作业的gc耗时),意味着task执行用户代码的内存不够用,那么同样建议调低这个参数的值。- spark.yarn.executor.memoryOverhead
executor执行的时候,用的内存可能会超过executor-memoy,所以会为executor额外预留一部分内存。spark.yarn.executor.memoryOverhead代表了这部分内存。这个参数如果没有设置,会有一个自动计算公式(位于ClientArguments.scala中),代码如下:
其中,MEMORY_OVERHEAD_FACTOR默认为0.1,executorMemory为设置的executor-memory, MEMORY_OVERHEAD_MIN默认为384m。参数MEMORY_OVERHEAD_FACTOR和MEMORY_OVERHEAD_MIN一般不能直接修改,是Spark代码中直接写死的。
关于Executor 计算的相关公式,见源码org.apache.spark.deploy.yarn.Clent,org.apache.spark.deploy.yarn.ClentArguments
主要部分如下
1 | var executorMemory = 1024 // 默认值,1024MB |
解决方案
在参数中设置spark.yarn.executor.memoryOverhead=4096,单位是MB,一般是2的幂,这里使用4G,默认申请的堆外内存是Executor内存的10%,真正处理大数据的时候,这里都会出现问题,导致spark作业反复崩溃,无法运行;此时就会去调节这个参数,到至少1G(1024M),甚至说2G、4G)
1 | spark-submit --master yarn --num-executors 20 --executor-memory 4G --executor-cores 4 --conf spark.yarn.executor.memoryOverhead=4096 --jars ../jars/spark-examples_2.10_my_converters-1.6.0.jar feature_extraction.py |
executor-memory+spark.yarn.executor.memoryOverhead<MonitorMemory
指定的 ExecutorMemory与MemoryOverhead 之和大于 MonitorMemory,则会导致Executor申请失败,程序直接不能运行;若运行过程中,实际使用内存超过上限阈值,Executor进程会被Yarn终止掉(kill)。
在运行程序中发现CPU的占用率不高,,增加num-executors的个数,减少executor-cores的个数
参考资料:
https://www.cnblogs.com/haozhengfei/p/5fc4a976a864f33587b094f36b72c7d3.html
https://blog.csdn.net/hammertank/article/details/48346285
https://www.jianshu.com/p/10e91ace3378
3. 创建sc
在服务器中的命令行中,输出:pyspark,会打开spark-shell交互窗口,这时spark-shell会自动创建一个sc,不用再创建sc,手动创建了也不能用,会出错。如果在py文件中写程序,首先需要手动创建一个sc。
1 | from pyspark import SparkConf, SparkContext |
或者使用
1 | from pyspark import SparkConf, SparkContext |
首先创建一个SparkConf对象来配置应用,然后基于该SparkConf来创建一个SparkContext对象。.setMaster()给定了集群的URL,高速spark如何连接到集群上,这里的local表示让spark运行在单机单变成上。
也可以是.setMaster('spark://192.168.1.11:7077')表示使用standalone运行spark程序。.setAppName()给出应用的名字,当连接到一集群上时,这个值可以帮助你找到你的应用。
4. RDD转换
RDD被创建好之后,在后续使用过程中有2中操作:
- 转换(Transformation):基于现有的RRD创建一个新的RDD
- 行动(Action):在数据集上进行运算,返回计算值
4.1. 转换操作
对于RDD而言,每一次转换操作都会产生不同的RDD,如果说rdd2 = rdd1.map(lamda x : x+1),rdd1的值不会改变,通过转换操作返回一个新的rdd供下一个转换操作。转换得到的RDD是惰性的,也就是说,整个过程只记录了转换的轨迹,并不会发生真正的计算,只有遇到Action操作时,才会发生真正的计算。开始从血缘关系源头开始,进行物理的转换操作。
下面列出一些常见的转换(Transformation)操作。
- filter(func):筛选出满足函数func的元素,并返回一个新的数据集
- map(func):将每个元素传递到函数func中,并将结果返回为一个新的数据集
- flatMap(func):与map()相似,但每个输入元素都可以映射到0或多个输出结果
- groupByKey():应用于(K,V)键值对的数据集时,返回一个新的(K, Iterable)形式的数据集
- reduceByKey(func):应用于(K,V)键值对的数据集时,返回一个新的(K, V)形式的数据集,其中的每个值是将每个key传递到函数func中进行聚合
4.2. 行动操作
行动操作是真正触发计算的地方。Spark程序执行到行动操作,才会执行真正的计算,从文件中加载数据,完成一次有一次转换操作,最终,完成行动操作得到结果。在触发Action操作时,开始真正的计算,这时,Spark会把计算分解成多个任务在不同机器上执行,每台机器上运行位于属于它自己的map和reduce,最后把结果返回给Driver Program。
下面给出一些常见的行动(Action)操作
- count() 返回数据集中的元素个数
- collect() 以数组的形式返回数据集中的所有元素
- first() 返回数据集中的第一个元素
- take(n) 以数组的形式返回数据集中的前n个元素
- reduce(func) 通过函数func(输入两个参数并返回一个值)聚合数据集中的元素
- foreach(func) 将数据集中的每个元素传递到函数func中运行
4.3. 持久化
在Spark中,RDD采用惰性的机制,每次遇到Action操作,都会从头开始执行计算。如果整个Spark程序只有一次Action操作,当然不会又什么问题。但是,在一些情况下,我们需要对一个RDD多次调用不同的Action,这就意味着,每次调用Action操作,都会触发一次从头开始的计算,代价很大,并且这些Action操作都是对一个RDD而言,所以可以把这个RDD持久化。
比如下面是多次对一个RDD进行Action操作
1 | list = ['a','b','c'] |
上面代码执行过程中,前后共触发了2次从头到尾的计算。
实际上,可以通过持久化(缓存)机制避免这种重复计算的开销。可以使用persist()方法对一个RDD标记为持久化,之所以说“标记为持久化”,是因为出现persist()语句的地方,并不会马上计算RDD并把它持久化,而是要等到第一个Action操作触发时,才开始计算RDD,并把RDD的内容进行持久化。持久化的RDD将会被保留在计算节点的内存中,以便被后面的Action操作重复使用。
persist()方法可以传入持久化级别参数
- persist(MEMOEY_ONLY)表示将RDD作为反序列化的对象存储在JVM中,如果内存不足,就要按照LRU原则替换缓存中的内容。
- persist(MEMORY_AND_DISK)表示将RDD作为反序列化的对象存储在JVM中,如果内存不足,超出的分区将会被存储在硬盘上。
- 一般使用cache()方法时,会调用persist(MEMORY_ONLY)
1 | list = ['a','b','c'] |
最后,可以使用unpersist()方法手动地把持久化的RDD从缓存中移除。
5. 分区
RDD是弹性分布式数据集,通常RDD很大,会被分成很多个分区,分别保存在不同的节点上。RDD的一个分区原则是使得分区的个数尽量等于集群中CPU核心(core)数目。
对于不同的Spark部署而言(local,Standalone,yarn,Mesos),都可以通过设置spark.default.parallelism这个参数的值,来配置默认的分区数据,一般而言:
- local模式:默认为本地机器的CPU数目,若设置了local[N],则默认为N
- Standalone和yarn:max(集群中所有CPU核心数目总和,2)作为默认值
- Mesos:默认的分区数为8
1 | scala>val array = Array(1,2,3,4,5) |
对于textFile而言,如果没有在方法中指定分区数,则默认为min(defaultParallelism,2),其中,defaultParallelism对应的就是spark.default.parallelism。
如果是从HDFS中读取文件,则分区数为文件分片数(比如,128MB/片)。
6. 创建RDD
创建RDD有2种方式,一种是通过列表创建,一种是通过读取文件创建。RDD的内部其实是一个Iterator\
6.1. 通过paralize创建RDD
1 | string='a\nb\nc\na\nd\ne' |
b是一个list列表,通过列表b可以创建一个RDD。
6.2. 读文本文件创建RDD
读取文本文件获取RDD,可以从服务器本地读取(其他节点也可以),也可以从hdfs上读取文件。文本每行的内容以字符串的形式作为RDD的一个元素。
从服务器本地读取文件时,需要加上file://
1 | rdd1 = sc.textFile("file:///file0/input/test.txt") |
从HDFS上读取文件
1 | rdd1 = sc.textFile('hdfs://master:8020/pc2/data.csv') |
7. map和flatMap
map是对RDD中的每个元素执行一个函数,每个元素返回一个list,然后把每个元素的list再组成一个大的list,例如[[a,a],[b,b]],然后flatMap就是先对每个元素执行一个函数,每个元素返回一个list,然后把每个元素的list的内容取出来,组成一个大的list,例如[a,a,b,b]。
这篇博客讲解的比较好。说明flatMap中的函数返回类型一定是一个可迭代的类型,先把元素生成一个列表,然后再把每个列表中的元素取出来拼接成一个大的列表。
这篇也讲的很好
8. flatMap和flatMapValues
flatMap针对的RDD中的每个元素先做map操作,再做flatten操作,最后形成超大的list返回。flatMapValues只针对元素是
9. reduceByKey和groupByKey
推荐使用reduceByKey,这篇博客对于两者的区别进行了解释。
groupByKey涉及数据的shuffle操作,shuffle是spark重建数据的机制,将来自不同分区的数据进行分组,开销很大。
10. sortBy和SortByKey
sortByKey针对(key,value)对中的key进行排序。
sortBy可以根据我们需要的值进行排序,不一定是key,比如统计单词出现的次数,然后按照次数进行排序(key,value),我们就是对value进行排序,可以使用sortBy函数。
sortBy()中有3个参数,第一个参数是一个函数,第二个参数是ascending,表示升序还是降序,默认是True(升序)。第三个参数是numPartitions,该参数决定排序后的RDD的分区个数,默认排序后的分区个数和排序之前的个数相等。
11. 将Spark计算的结果存储在文件中
11.1. 写入到服务器本地文件中
假设pyspark计算的结果存储在results变量中,然后将results的内容存储在文件中。
1 | # 将结果写入到服务器本地的文件中 |
11.2. 写入到HDFS文件中
spark将RDD中的每个元素作为一行写入到文本文件中。在写入到HDFS之前,首先把results中的每个元素转成字符串的形式。
比如rdd1为[('b',3),('a',2),('c',1)],rdd1中的每个元素是一个元组,需要把每个元素转换成字符串类型。rdd2 = rdd1.map(lamda x: x[0]+","+str(x[1])) ,然后使用rdd2.saveAsTextFile('/tmp/word_count_result'),把结果存储到word_count_result这个文件中,这个文件没有后缀名。
11.3. 打印RDD元素
在实际编程中,我们经常需要把RDD中的元素打印输出到屏幕上(标准输出stdout),一般会采用语句rdd.foreach(println)或者rdd.map(println)。当采用本地模式(local)在单机上执行时,这些语句会打印出一个RDD中的所有元素。但是,当采用集群模式执行时,在worker节点上执行打印语句是输出到worker节点的stdout中,而不是输出到任务控制节点Driver Program中,因此,任务控制节点Driver Program中的stdout是不会显示打印语句的这些输出内容的。为了能够把所有worker节点上的打印输出信息也显示到Driver Program中,可以使用collect()方法,比如,rdd.collect().foreach(println),但是,由于collect()方法会把各个worker节点上的所有RDD元素都抓取到Driver Program中,因此,这可能会导致内存溢出。因此,当你只需要打印RDD的部分元素时,可以采用语句rdd.take(100).foreach(println)。

