1. Attention
Attentions详细讲解
Attention一般有2种,(1):Location-based Attention,这里的attention没有其他额外需要关注的对象,即多个$h_i$内部做attention。(2)Concatenation-based Attention:有额外需要关注的对象,即多个$h_i$对$h_t$的attention。我们平时用第2种比较多一些。
2. Attention的计算公式
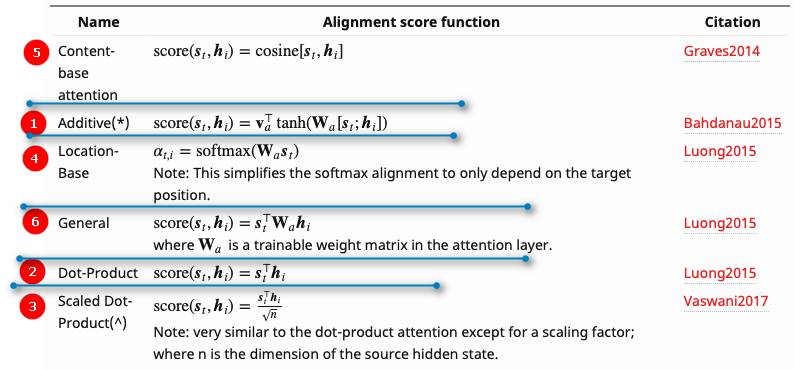
在计算Attention分数时,有很多中计算方式,包括addictive,concat,dot product。其中涉及点积运算的评分函数的思路是度量2个向量间的相似度。 以下展示了6种计算Attention分数的方法:
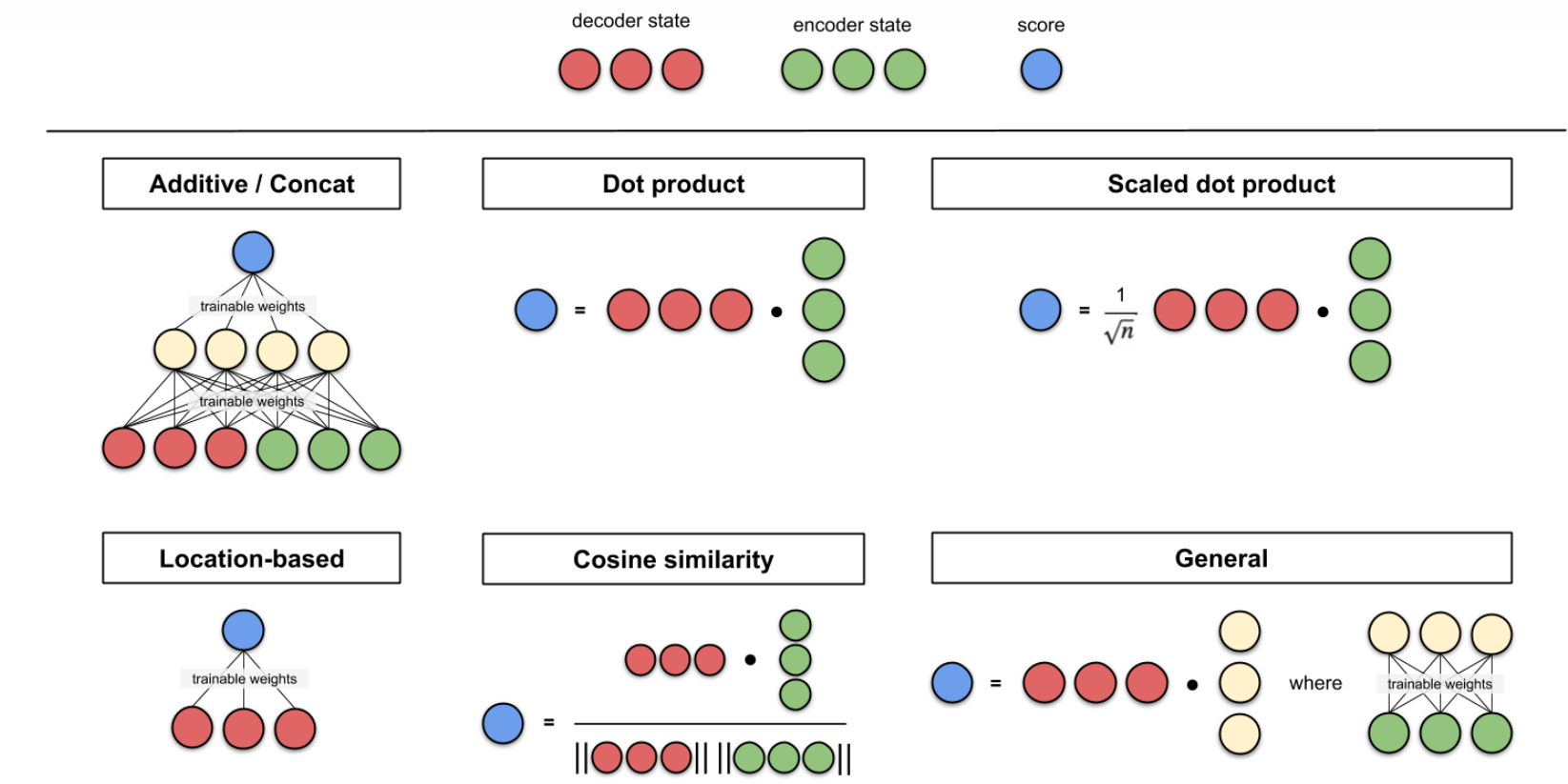
- Additive/Concat:将2个向量拼接在一起,然后输入到全连接中,得到attention分数,$score=W[h_i:h_j]$
- Dot product:2个向量点积计算attention score,$score = h_i . h_j^T$
- Scaled dot product:缩放点积,$score = \tfrac{h_i . h_j^T}{\sqrt{n}}$
- Location-based Attention:这里Attention涉及的对象只有1个,自己和自己Attention计算得到分数。
- Cos:2个向量Cos运算
- General
3. Attention在NLP的应用
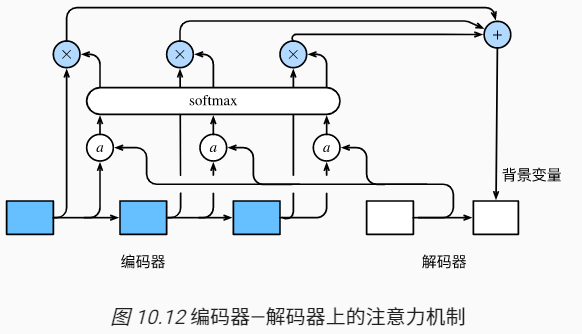
在上面的编码器-解码器中,从编码器传到解码器的背景变量$c$是不变的。就是说解码器在翻译第一个词和第二个词是c是不变的。但是实际情况中,比如英语they are watching。翻译成法语是:IIs regardent。比如在翻译IIS时,和they are更相关,在翻译regardent和watching更相关,所以希望把背景变量$c$设置成一个变化的值。当翻译IIS时,对编码器的隐藏变量$h_1,h_2$更看重,当翻译regardent对隐藏变量$h_3$更看重,所以就需要在解码器中,在不同时间步时,对编码器的隐藏变量$h_1,h_2,h_3$分配不同的权重,加权平均得到背景变量$c$。
原先解码器隐藏层变量的计算是上一时刻的输出$y_{t’-1}$,上一时刻的隐藏状态$s_{t’-1}$以及背景变量$c$,在加入attention机制后,这里的背景变量变成了$c_{t’}$,每一步的背景变量都不一样。
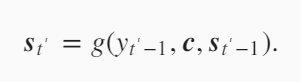
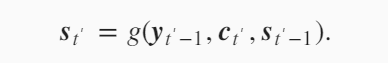
下面看一下$c_{t’}$是怎么设计的。 就是编码器的不同时刻的隐藏状态的加权平均。只是这里的权重$\alpha_{t’t}$在每一个时刻是一个变化的值。 注意这里的$t’$是输出(解码器)的时间戳,$t$是输入(编码器)的时间戳。首先我们先固定$t’$,下面的式子中$t’$是不变的。在计算$c_{t’}$时,变化$t从1到T$,遍历所有的$h_t$,然后给定一个$h_t$,怎么求$h_t$对应的权重$\alpha_{t’t}$。
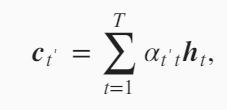
例如计算解码器在第$t’$个时间步的背景向量$t’$,使用解码器$t’-1$个时间步的隐藏状态$S_{t’-1}$作为query,将编码器所有时间步的隐藏状态$h_0,…h_t$作为key和value,先将$S_{t’-1}$和$h_0,…h_t$做Attention,然后将Attention score使用$softmax$归一化,再和$h_0,…h_t$加权求和,得到解码器中第$t’$个时间步的背景向量$c_{t’}$
下面我们看一下$\alpha_{t’t}$是怎么来表示。加权平均就要使所有的权值加起来为1,所以用到softmax运算。softmax中的每一个值是
$e$,这个是怎么计算的.$e_{t’t}$通过解码器上一时刻的隐藏变量$s_{t’-1}$和编码器所有时间步的隐藏变量$h_t$计算得到。
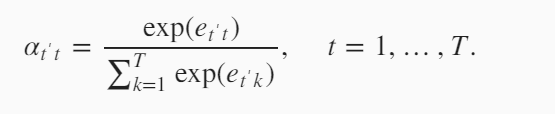
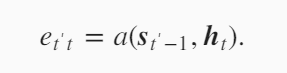
注意力机制对函数$a$设计有很多。下面是一种设计方法。首先一定要有$s_{t’-1}$和编码器所有时间步的隐藏状态$h_t$。然后引入了3个模型参数$v^T,W_s,W_h$,这3个参数通过训练得到。对$s_{t’-1}$做一个projection,对$h_t$做一个projection,使得projection之后的向量长度相等,这样就可以加在一起,然后使用tanh激活函数,这时的向量长度还是projection之后的长度,但是我们希望$e_{t’t}$是一个标量,那就再引入向量$v^T$,和右边的向量做一个点乘得到一个标量。其实注意力可以通过多层感知机(全连接层)得到。

下面介绍计算解码器的隐藏变量时的函数$g$是什么?g可以看到是一个GRU单元。

其中$y_{t’-1}$是解码器上一时间步的输出,可以看做当前时间步的输入,$s_{t’-1}$是解码器上一时间步的隐藏状态,$c_{t’}$是当前时间步的背景向量。
这里总结一下模型的参数都有哪些:编码器中的W和b,上式中解码器中的W和b,还有计算attention中的$v^T,W_s,W_h$。
4. Attention分类
4.1. Soft Attenion
《Show, Attend and Tell: Neural Image Caption Generation with Visual Attention》提出了hard/soft Attention
加权求和,可以求导,可以放到模型中训练,用的比较多
4.2. Hard Attention
Hard attention 是一个随机的过程,Hard attention不会选择整个encoder的隐层输出作为其输入,Hard Attention会依赖概率$𝑆_𝑖$来采样输入端的隐状态的一部分来进行计算,而不是整个encoder 的隐状态。由于其是一个随机过程,所以不能直接求导,为了实现梯度的反向传播,需要采用蒙特卡洛采样等方法来估算模块的梯度。
4.3. Global Attention
《Effective Approaches to Attention-based Neural Machine Translation》提出了local/glocal Attention
Global attention和传统的attention model是一样的,所有的hidden state都被用于计算Context vector的权重,其长度等于Encoder输入的长度。
缺点:encoder很长时计算量大
4.4. Local Attention
并不是使用Encoder中所有时间步的隐藏状态做Attention,只使用一部分和decoder做Attention。
4.5. Self Attention
Q,K,V都是自己本身,即自己对自己的注意力机制。有以下优点:
- 可以捕获同一个句子中单词之间的句法特征和语义特征。
- 更容易捕获句子中长距离的相互依赖特征,而RNN则需要依次按顺序计算,捕获的可能性降低。
- self attention 计算中将句子中任意两个单词通过一个计算步骤连接,远距离依赖之间的距离被极大缩短。
- 对于增加计算的并行性有直接的帮助作用。
【参考资料】
Attention? Attention!

