看了很久关于图卷积的内容,但总觉得自己理解不深刻,在这里把自己的一些想法写出来,也算把图卷积的内容梳理一下。
在介绍图卷积之前,先介绍一下卷积神经网络。
1. 卷积神经网络
卷积神经网络在图像上用的比较多。因为图像的一些重要的性质是:(1)局部性;(2)稳定性;即平移不变性和有大量相似的碎片;(3)多尺度性,简单的结构组合形成复杂的抽象结构。
图像本来就是一个规范的形状,可以形式化成一个规则的矩阵,再定义一个卷积核,卷积核在图像矩阵上滑动,把周围的几个像素值整合成一个值,获取了图像的局部性。可能会有多个卷积核,用来识别图像中不同的特征,比如下面例子所示,第一个卷积核用来识别左右的边缘,第二个卷积核用来识别上下的边缘。
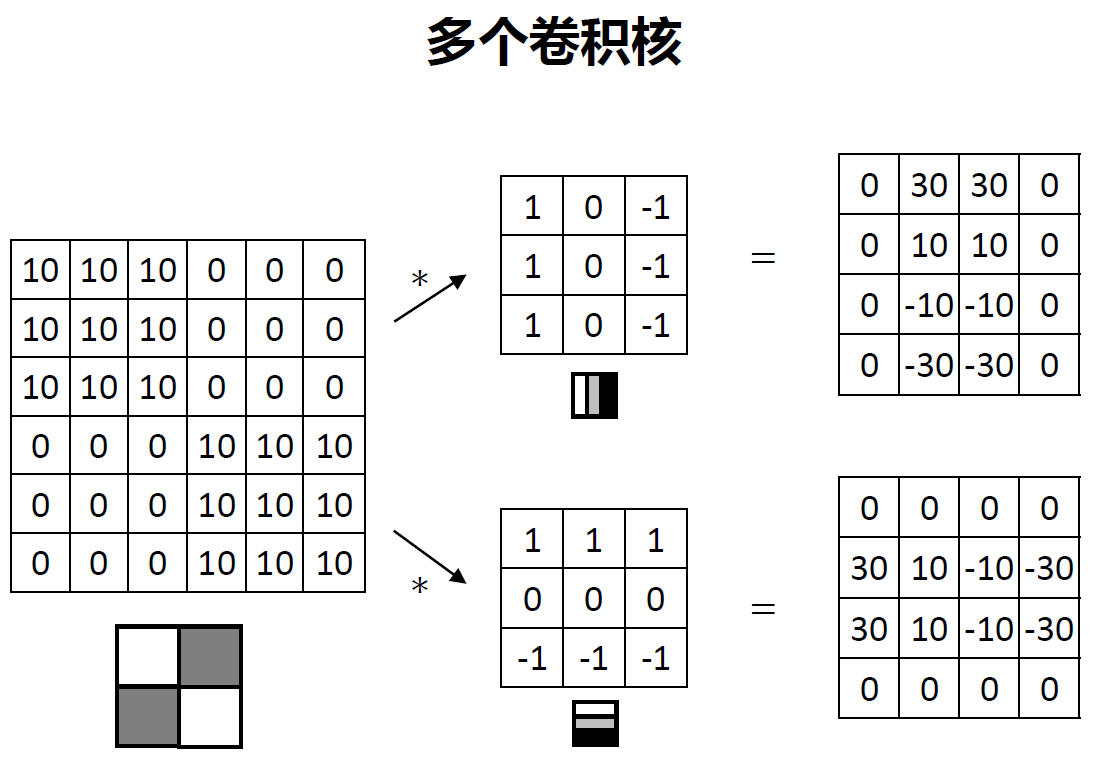
- 在卷积神经网络中,需要训练的参数是卷积核。
- 在卷积神经网络中,卷积层后面通常跟一个池化层,防止参数越来越多。
- 卷积核的大小通常是3x3和5x5
- 池化层如果是3x3,步长为2,那么图像大小会变成原来的一半,变成原先图像的多少和步长有关。
- 在图卷积层的最后一层是全连接层,可以使用1x1的卷积核来代表全连接,比如最后池化层输出是5x5x16,表示一层是5x5,一共有16层(通道),经过全连接变成一个400x1的向量.
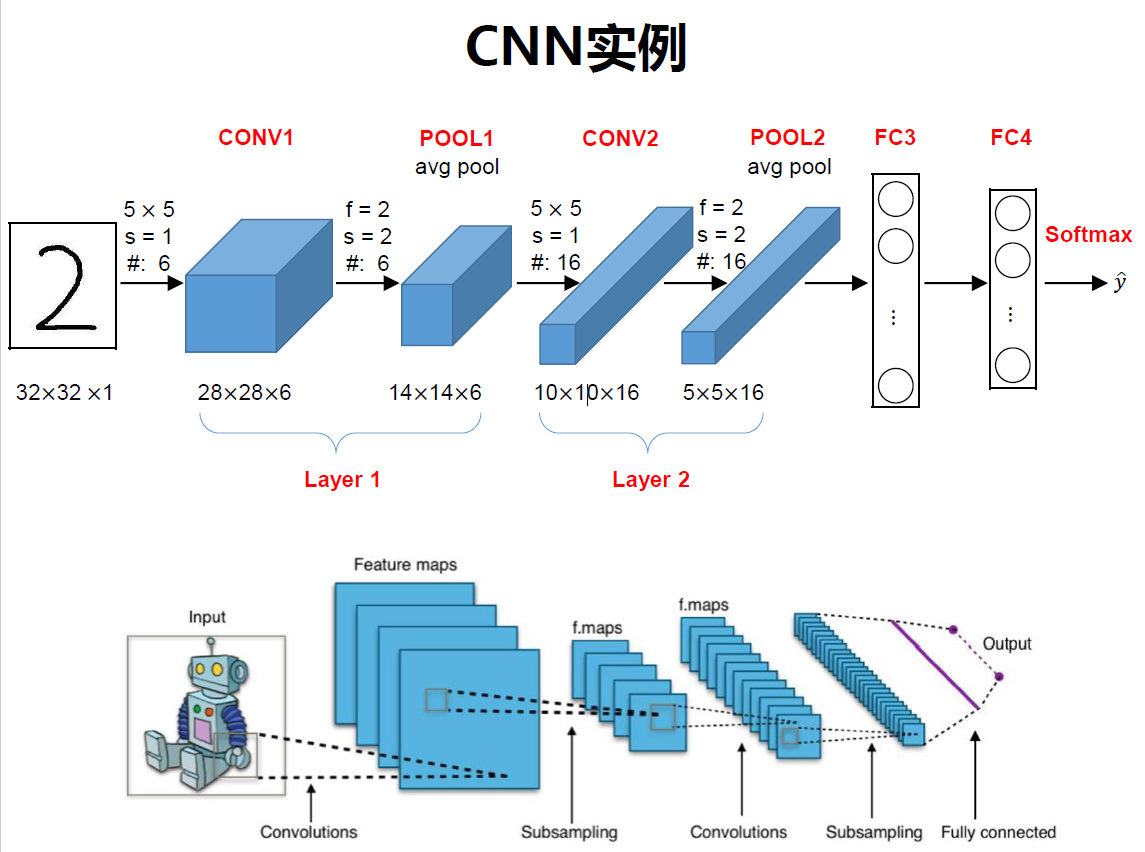
使用卷积神经网络对一张图片进行分类时,首先给定这张图片的特征,比如是32x32x3和这样图片的实际类别,如果是10个类,这张图片是第2个类,那么就是一个[0,1,0,…]的向量。将图片输入卷积层中,卷积核刚开始是随机初始化的,输入X和卷积核做卷积操作,经过池化层,再经过一个卷积层和池化层,然后是一个全连接层,最后一个全连接层的输出结点个数是10,表示10个类别,如果输出的结果和实际的类别有偏差,然后通过误差反向传播,更新卷积核,直到误差最小,得到模型参数:卷积核。卷积核的参数通过优化求出才能实现特征提取的作用
2. 图卷积神经网络
有了卷积神经网络,为什么还要引入图卷积神经网络?
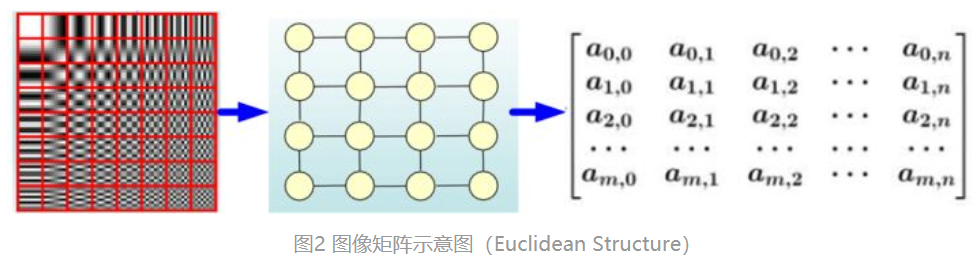
因为卷积神经网络处理的是规则的矩阵,像图像和视频中的像素点都是排列整齐的矩阵,也是论文中提到的欧式结构(Euclidean Structure)。
但在科学研究中,还有很多非欧式结构(Non Euclidean Structure)的数据,例如社交网络、信息网络。

实际上,这样的网络结构就是图论中抽象意义上的拓扑图。
为什么要研究GCN,原因如下三个:
- 卷积神经网络CNN无法处理非欧式结构的数据,在非欧式结构数据中,图中每个顶点的相邻顶点个数可能不同,无法用一个同样尺寸的卷积核进行卷积运算。
- 由于卷积神经网络CNN无法处理非欧式结构的数据,但是又希望在这样的数据结构上有效地提取空间特征来进行机器学习,所以GCN成为了研究的重点。
- 拓扑结构的数据在生活中很常见,社交网络、交通领域都涉及到非欧式结构的数据。
图卷积网络GCN的本质目的是提取拓扑图的空间特征。图卷积神经网络中有2种:顶点域和谱域。这是提取拓扑图空间特征的两种方式,就是给定非欧式结构数据,从中构建图的两种方法。
2.1. 顶点域(Vertex Domain)
空间图卷积直接将卷积操作定义在每个节点的连接关系上,它和传统的卷积CNN更相似。代表方法有:GraphSage,DCRNN
提取拓扑图上的空间特征,就是把每个顶点的邻居找出来。这里的问题是:(1)按照什么条件去找中心顶点的邻居,也就是如何确定感受野?(2)确定了邻居,按照什么方式处理包含不同数据邻居的特征?
Learning Convolutional Neural Networks for Graphs是2016年在ICML中发表的一篇论文,这是PPT讲解。由于CNN并不能有效的处理非欧式结构数据,这篇paper的motivation就是想将CNN在图像上的应用generalize到一般的graph上面。
本文提到的算法思想是:将一个图结构的数据转化为CNN能够高效处理的结构。处理的过程主要分为三个步骤:(1)从图结构中选出一个固定长度具有代表性的结点序列;(2)对于选出的每一个结点,收集固定大小的邻居集合。(3)对由当前节点及其对应的邻居构成的子图进行规范化,作为卷积结构的输入。算法具体分为4个步骤。
2.1.1. 图中顶点的选择Node Sequence Selection
首先对于输入的一个Graph,指定中心顶点的个数,然后确定确定图中的中心结点,确定中心结点主要采取的方法是:centrality,也就是中心化的方法,就是越处于中心位置的点越重要。这里的中心位置不是空间上的概念,应该是度量一个点的关系中的重要性的概念,简单的举例说明。如图5当中的两个图实际上表示的是同一个图,对其中红色标明的两个不同的nodes我们来比较他们的中心位置关系。比较的过程当中,我们计算该node和其余所有nodes的距离关系。我们假设相邻的两个node之间的距离都是1。
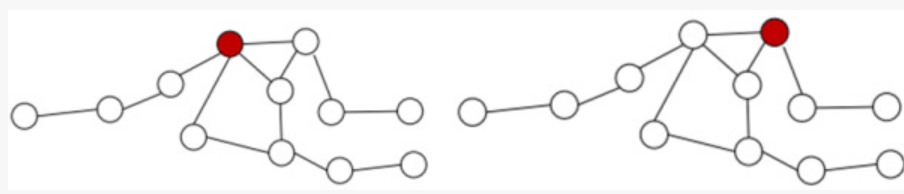
那么对于左图的红色node,和它直接相连的node有4个,因此距离+4;再稍微远一点的也就是和它相邻点相邻的有3个,距离+6;依次再相邻的有3个+9;最后还剩下一个最远的+4;因此我们知道该node的总的距离为23。同理我们得到右边的node的距离为3+8+6+8=25。那么很明显node的选择的时候左边的node会被先选出来。
当然,这只是一种node的排序和选择的方法,其存在的问题也是非常明显的。Paper并没有在这次的工作当中做详细的说明。
2.1.2. 找到中心结点的邻域Neighborhood Assembly
选出目标node之后,我们之后就要为目标node确定感受野大小。但是在确定之前,我们先构建一个candidate set,然后在从这个candidate set中选择感受野的node。这些感受野的candidate set,称为目标node的neighborhood。如下图所示,为每个目标node选择至少4个node(包括自己,k即为感受野node的个数)。接下来对选出来的每一个中心结点确定一个感受野receptive filed,以便进行卷积操作。但是在这之前,首先找到每个结点的邻域区域(neighborhood filed),然后再从当中确定感受野当中的结点。假设感受野的大小为k,那么对于每个结点会有2种情况:邻域结点的个数不够k个,或者邻域结点个数大于k个。
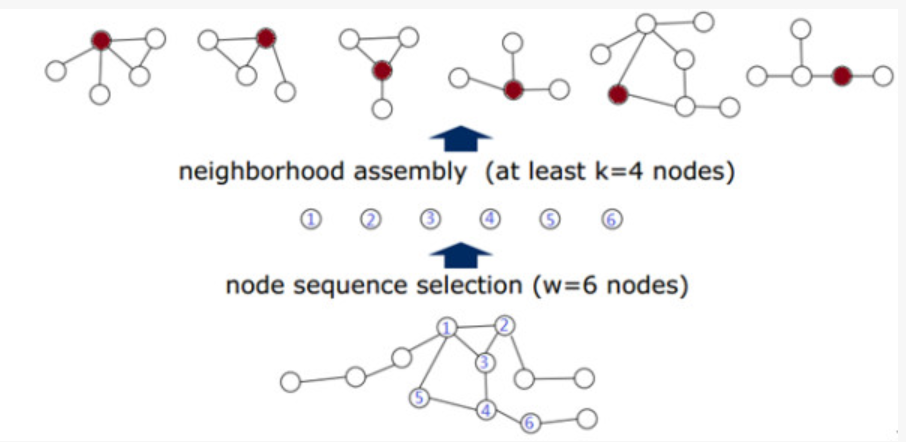
如上图所示,选出6个中心结点,对于每个中心结点,首先找到与其直接相邻的结点(被称为1阶邻居),如果还不够再增加2阶邻居,那么对于1阶邻居已经足够的情况下,先全部放在候选 的区域中,在下一步中通过规范化做最终的选择。
2.1.3. 图规范化过程Graph Normalization
这一步的目的在于将从candidate中选择感受野的node,并确定感受野中node的顺序。最终的结果如下图所示:假设上一步选择邻域过程中一个中心结点的邻居(一阶或者二阶)有N个,那么N可能和感受野大小K不相等。因此,normalize的过程就是要对N个邻居打上排序标签并进行选择,并且按照该顺序映射到向量中。
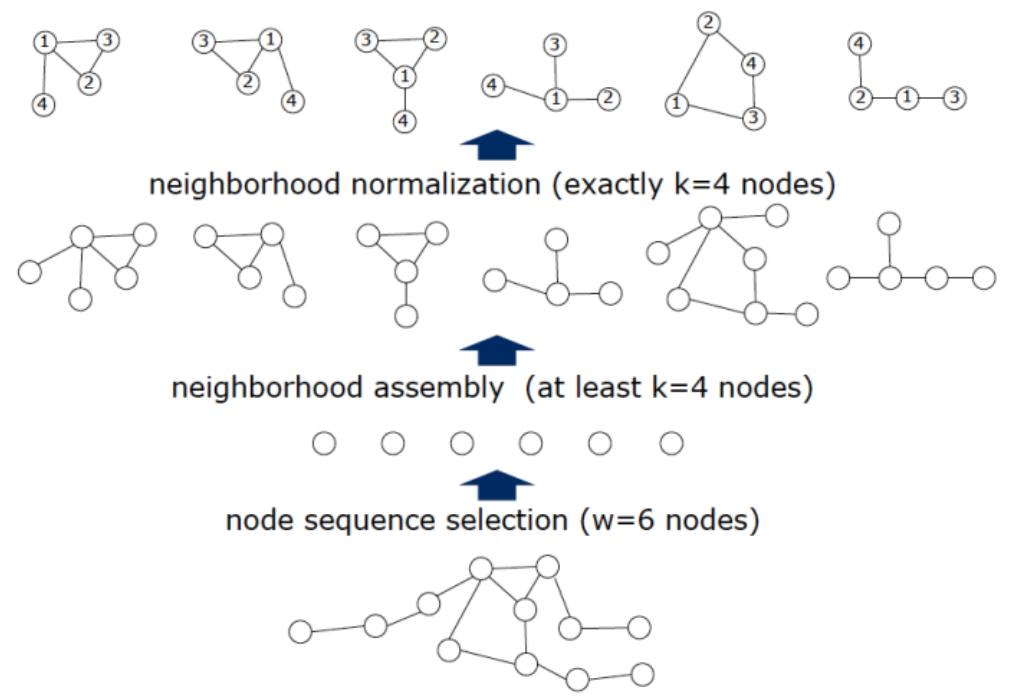
如果这个中心结点的邻居个数不够k个的话,直接把所有的邻居全部选上,不够补上哑结点(dummy nodes),但还是需要排序的。如果中心结点的邻居个数N大于感受野k,则需要按照排序截断后面的结点。如上图所示,表示从中心结点到选邻居的整个过程。Normalize进行排序之后就能够映射到一个vector中,因此这一步最重要的是对结点进行排序。
对于任意一个中心结点求解它的感受野的过程。这里的卷积核的大小为4(2x2的卷积核),因此最终要选出4个邻居,包括中心结点本身。因此,需要给这些结点打标签(排序)。怎样打标签才是最好的?如上图要在7个结点中选出4个结点组成一个含有4个结点的图集合。作者认为,在一种标签下,就是已经给图中的节点排好序了,随机从集合中选出2个图,计算它们在向量空间的图距离和在图空间的图距离的差异的期望,如果这个期望越小那么就表示标签越好。得到最好的标签之后,就能够按着顺序将结点映射到一个有序的向量中,也就得到了感受野。
2.1.4. 卷积网络结构Convolutional Architecture
文章使用的是一个2层的卷积神经网络,将输入转化为一个向量vector之后便可以用来进行卷积操作了。具体的操作所示。

首先最底层的灰色块为网络的输入,每一个块表示的是一个node的感知野(receptive field)区域,也是前面求解得到的4个nodes。其中an表示的是每一个node的数据中的一个维度(node如果是彩色图像那就是3维;如果是文字,可能是一个词向量……这里表明数据的维度为n)。粉色的表示卷积核,核的大小为4,但是宽度要和数据维度一样。因此,和每一个node卷季后得到一个值。卷积的步长(stride)为4,表明每一次卷积1个node,stride=4下一次刚好跨到下一个node。(备注:paper 中Figure1 当中,(a)当中的stride=1,但是转化为(b)当中的结构后stride=9)。卷积核的个数为M,表明卷积后得到的特征图的通道数为M,因此最终得到的结果为V1……VM,也就是图的特征表示。有了它便可以进行分类或者是回归的任务了。
2.1.5. 伪代码

这个算法用来选择要进行卷积操作的node,其中w为要选择的node的个数。s为stride的大小。其中一个关键在于graph labeling procedure l。labeling算法用来确定一个graph中node的次序。这个算法可以根据node degree来确定,或者根据其他确定centrality的测量方式,比如:between centrality, WL algorithm等。或者其他你认为可行的算法。
这个算法非常简单,就是一个BFS算法,对每个目标node,寻找离node最近的至少k个node。
这是整个论文的重点,这个步骤的目的在于将目标node无序的neighbors映射为一个有序的vector。这个label要实现一个目的:assign nodes of two different graphs to a similar relative position in the respective adjacency matrices if and only if their structural roles within the graph are similar. 也就是说,对于两个不同的graphs, 来自这两个graph的子结构g1和g2,它们在各自的graph中有相似的结构,那么他们label应该相似。为了解决这个问题,论文中定义了一个optimal graph normalization问题,定义如下:

这个等式的解在于寻找一个一个labeling L, 使得从图的集合中任意选取两个图G1和G2,它们在vector space距离差距和它们在graph space的距离差距最小化。但是这个问题是NP-hard的问题,所以作者选择找一个近似解。即它比较了各种labeling方法,并从其中找出最优解。具体如下: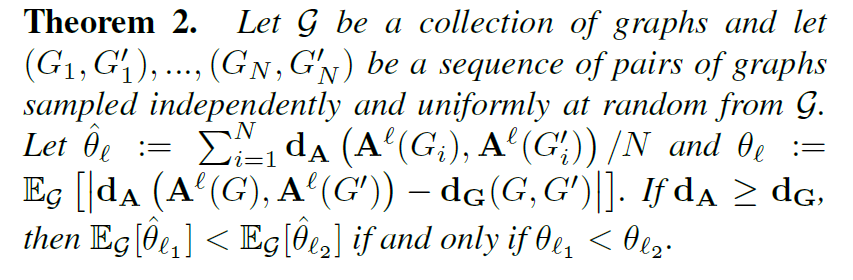
在特征选择阶段,只有第一层和传统的CNN有区别,之后的卷积层和传统的一样。下面来举例来说明PATCHY-SAN如何提取顶点特征和边特征。我们假设a_v为顶点特征的个数,a_e为边特征的个数。w为目标node的个数,k为感受野中node的个数。对于每个输入图结构,运用上面的一系列normalization算法,我们可以得到两个tensor (w,k,a_v)和(w,k,k,a_e),分别对应于顶点特征和边特征。这两个tensor可以被reshape成(wk, a_v)和(wk^2, a_e),其中a_v和a_e可以分别看成是CNN中channel的个数。现在我们可以对它们做一维度的卷积操作,其中第一个的感受野大小为k,第二个感受野大小为k^2。而之后的卷积层的构造和传统的CNN一样了。
2.1.6. 算法流程
输入:任意一张图
输出:每个channel输出w个receptive field
Step1: graph labeling(对图的节点做标记,比如可以用节点的度做标记,做图的划分,也 可以叫做color refinement or vertex classification)
文中采用The Weisfeiler-Lehman algorithm做图的划分。由此可以得到每个节点的rank 值(为了不同的图能够有一个规范化的组织方式)
Step2:对labeling好的节点排序,取前w个节点,作为处理的节点序列。(这样就可以把不 同size的graph,变成同一个size)若不足w个节点,则,在输出中加全零的receptive field,相当于padding
Step3:采用stride=s来遍历这w个节点。文中s=1(若s)1,为了输出有w个receptive field, 也用step2的方式补全)
Step4:对遍历到的每个节点v(称作root),采用bfs的方式获得此节点的k个1-neighborhood, 如果不k个,再遍历1-neighborhood的1-neighborhood。直到满足k个,或者所有的 邻居节点都遍历完。此节点和他的k个邻居节点就生成了neighborhood graph。
Step5: step4就生成了w个(s=1)neighborhood graph。需要对着w个graph 进行labeling, 根据离root节点v的远近来计算每个节点的rank,根据算法4是离v越近,r越小。 如果每个neighborhood graph不足k个节点,用0节点补充
Step6:规范化step5得到了已经label好的graph,因为需要把它变成injective,使每个节点 的标签唯一,采用nauty的算法通过这w个receptive field就能得到一个w(k+1)维的向量。
2.2. 谱域Spectral Domain
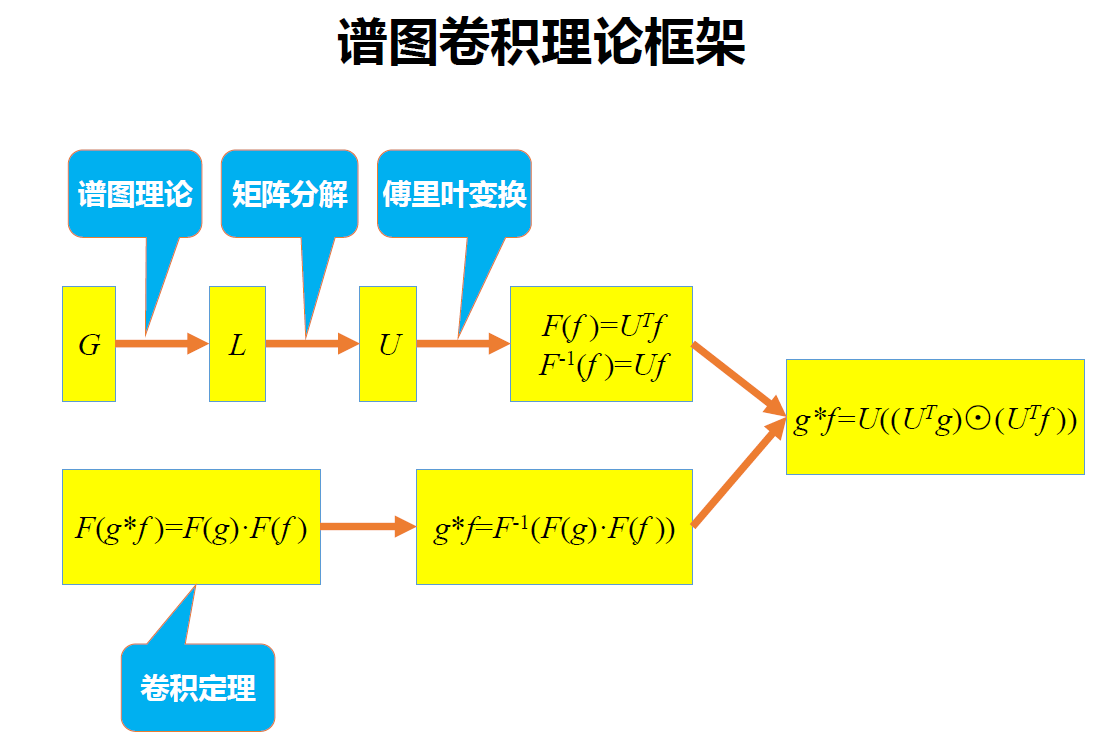
谱域就是GCN的理论基础了。这种思路就是借助图谱的理论来实现卷积操作。
- 首先定义图上的傅里叶变换
- 从而定义图上的卷积
- 最后提出谱图卷积
代表方法有:ChebNet
谱图理论就是借助图的拉普拉斯矩阵的特征值和特征向量来研究图的性质。
在这里需要明确一点:谱图和顶点域的本质完全不一样。顶点域其实还是先对图进行处理,然后像类似卷积核在图上滑动来计算。这里谱域就没有卷积核在图上滑动的这个概念了。里面的卷积运算就理解成矩阵之间的运算,不要再去想卷积核滑动的思想了。
2.2.1. 图卷积运算
2.2.1.1. 卷积定理
由传统的卷积定理—>图上的卷积,因为在计算传统的卷积时需要用到傅里叶变换,所以在计算图上的卷积时也需要用到图上的傅里叶变换。
- 下图中的$F$表示的是傅里叶变换,
- $g*f$表示卷积运算,
- 可以看到$g*f$的傅里叶变换=$g$的傅里叶变换乘上$f$的傅里叶变换。
- 其中$f$是待卷积的函数,就是一个待卷积的图,$g$就是卷积核。
- 从傅里叶变换—>卷积公式
- 把图上的傅里叶变换代入到下面中,就可以得到图上的卷积运算。

2.2.1.2. 图上的傅里叶变换
由传统的傅里叶—>图上的傅里叶变换,我们不需要知道怎么由传统的傅里叶变换得到图上的傅里叶变换,只需要知道图上的傅里叶变换
其中$f$是待变换的函数,$F(f)$是$f$傅里叶变换之后的函数。$U$是图的拉普拉斯进行特征值分解得到的特征向量矩阵。
图上的傅里叶的逆变换:
- 谱图卷积为什么使用拉普拉斯矩阵的特征向量作为变换的基?
因为在图上做傅里叶变换,需要找到图的连续正交基,对应与傅里叶变换的基,所以选用拉普拉斯的特征向量。拉普拉斯的特征向量相互正交。
首先计算$f$的傅里叶变换为$U^Tf$,卷积核的傅里叶变换写成对角矩阵的形式为:是L的特征值的函数
两者的傅里叶变换乘积即为
再乘上$U$求两者傅里叶变换乘积的逆变换,则求出$f和g的卷积$
很多论文中会把上式写成$(f*g)_G=U((U^Tg)\odot(U^Tf))$
可以看出$U$为特征向量组成的特征矩阵,
$f$为待卷积函数,在图中就是图信号矩阵,
重点在于设计可训练、共享参数的卷积核$g$。
2.2.1.3. 拉普拉斯矩阵


给出一个无向图,可以写出这个图的邻接矩阵$A$,无向图的邻接矩阵是一个对称矩阵,其中对角线上全是0。度矩阵$D$是一个对角矩阵,只有对角线上有值,其余全是0,$D_{i,i}=\sum_jA_{i,j}$,把$A$中的每一行加起来就是这个点的度。拉普拉斯矩阵$L=D-A$,拉普拉斯矩阵是一个对称矩阵,只有中心节点和一阶相连的顶点非0,其余位置全为0。对角线上表示这个节点有几个一阶邻居(不包括自己),这一行中值为-1的表示是该节点的一阶邻居。

后面的论文都是在研究怎么设计出卷积核,即怎么表示$U^Tg$
很多论文中会把上式写成$(f*g)_G=U((U^Tg)\odot(U^Tf))$
2.2.2. 第一代图卷积SCNN
第一代图卷积模型SCNN是在2014年发表在NIPS中的Spectral Networks and Deep Locally Connected Networks On Graph提出来的。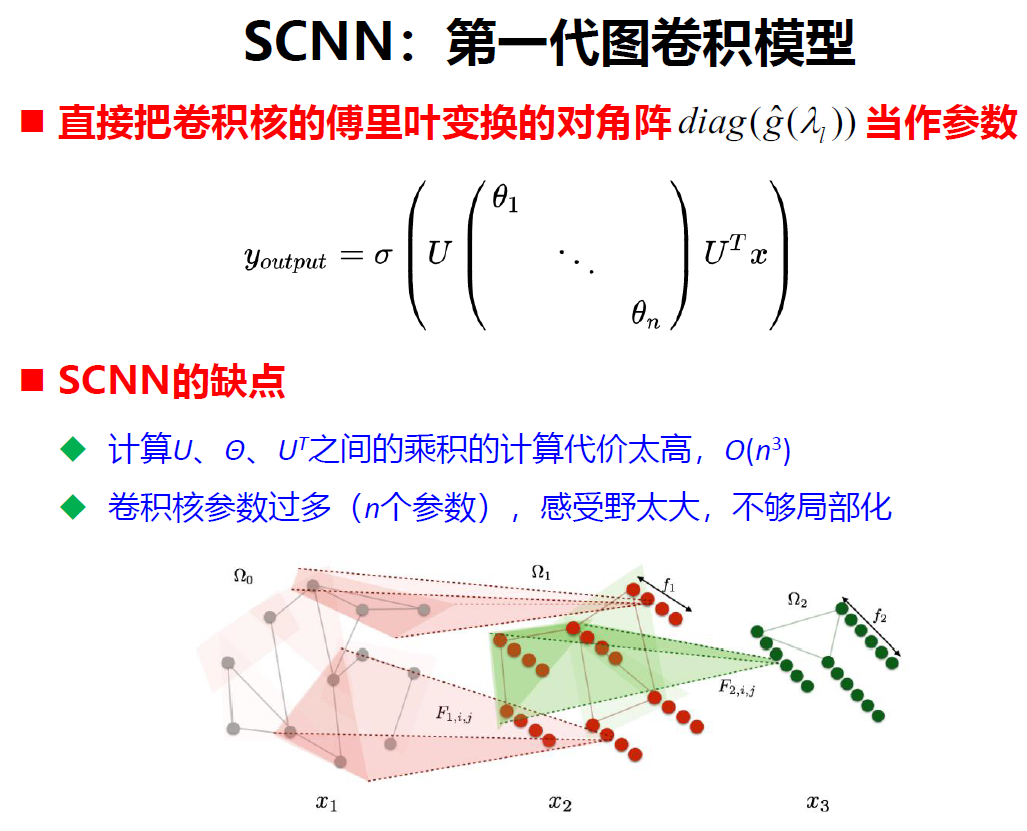

第一代卷积。谱图卷积就是给定一个图信号,和一个卷积核。图信号就是假设有一个图,如果有200个节点,每个节点有3个特征,x就是一个2003的矩阵,这个矩阵就是图信号矩阵。卷积核就是一个参数𝜃,谱图卷积的定义就是对归一化的拉普拉斯矩阵特征分解,得到特征值组成的矩阵$\Lambda$和特征向量组成的矩阵U,由于L是对称矩阵,所以U-1等于UT。谱图卷积的定义:在欧式空间内卷积的定义是傅里叶变换乘积的逆变换,研究图上的卷积是怎么来的,将图上的信号做一个图傅里叶变换,将卷积核做一个图傅里叶变换,将这两个做一个内积,然后再做一个图上的逆傅里叶变换。所以一个卷积核在图信号的谱图卷积就定义出来了。这个式子直接把卷积核g的傅里叶变换的对角矩阵当做参数,此时的卷积核不需要训练,因为右式中的所有值都是已知的。U已知,中间的对角矩阵的值 $\theta$ *就是傅里叶算子,也是已知的,图信号矩阵x也是已知的。这种方式太简单,这个卷积核不具有局部性,不能捕获局部关系。并且这个式子的时间复杂度很高,是n的立方,第二个是参数过多。所以后人对其进行改进。
2.2.3. 第二代图卷积ChebNet

将卷积核变成特征向量的多项式,则卷积计算就变成下面的形式:


第二代图卷积。$g_\theta$是关于特征值的一个函数,以前是直接把特征值变成卷积核,现在把每一个特征值上都乘上一个特征值矩阵的k次幂,然后把0到k-1次幂加到一起,构造成一个新的卷积核。把这个卷积核代入,得到右侧这个式子,右边这个式子不需要做特征值分解,直接把L连乘k次就可以了。这个卷积核是需要训练的,其中的参数是$\theta_k$通过初始化赋值再通过反向传播进行调整。所以这个一个改进,这个式子比前面那个式子的时间复杂度低。但是右边的这个时间复杂度也不低,因为涉及到L的k次幂,现在就想办法把右边这个式子的时间复杂度降低。
2.2.4. 第三代图卷积
ICLR2017Semi-supervised Classification with Graph Convolutional Networks这篇论文就对上面那个式子进行改进,让K=1,最大特征值=2,这个式子就变成了右边这个式子,继续化简,让$\theta_0$和$\theta_1$互为相反数,称为一个权重,为什么能这么变呢,因为他相信训练的时候卷积核就可以学出互为相反数的参数。这样只考虑一阶邻居,如果堆叠2个卷积层的话,就可以考虑2阶邻居了。
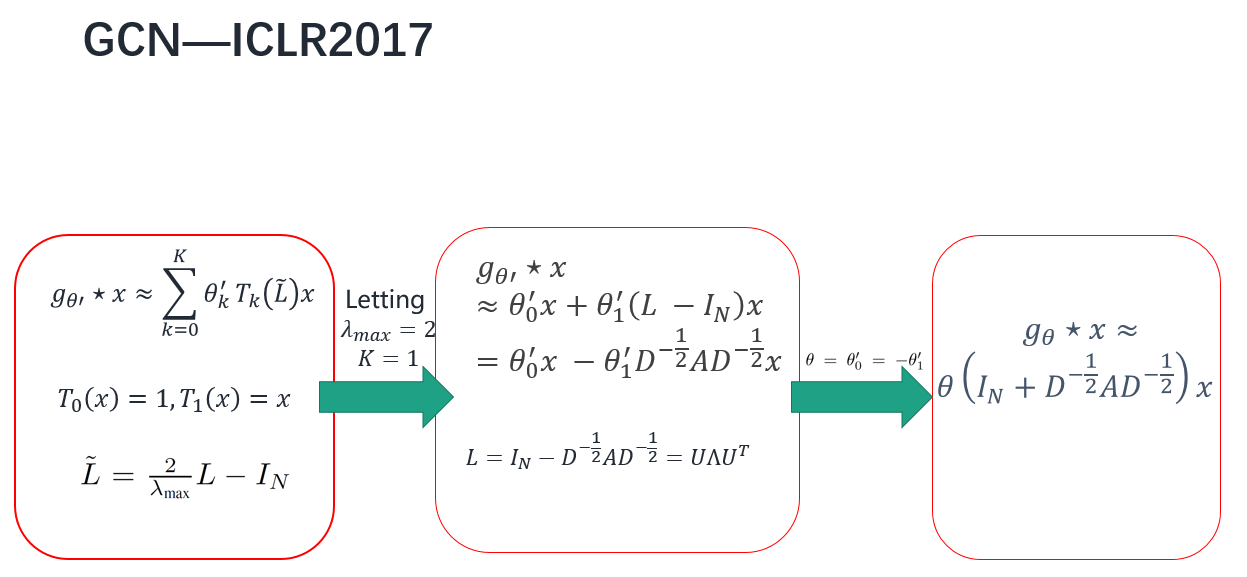
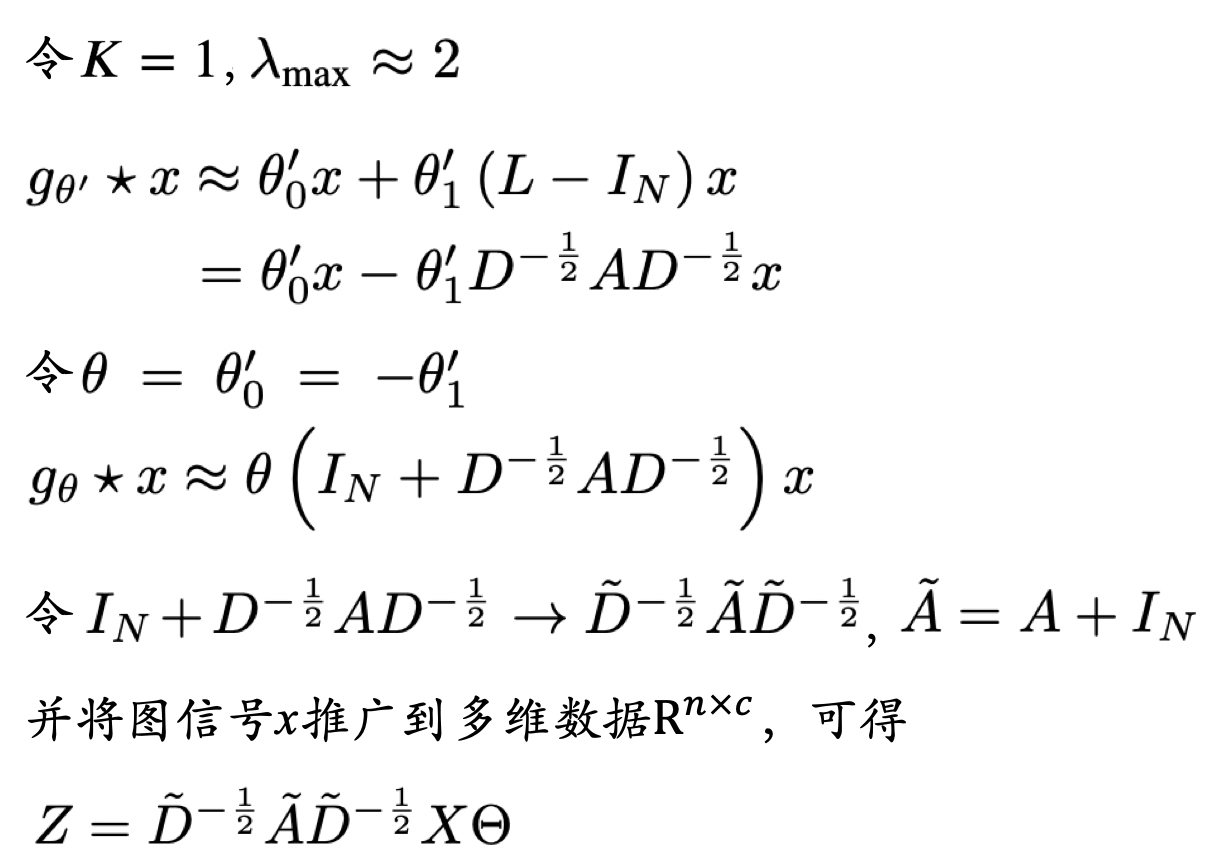

然后这篇论文又对刚刚的那个式子作一个归一化的trick,就是把邻接矩阵A加上一个单位矩阵,原先A是一个邻接矩阵,对角线上全为0,现在加上一个1,就是说节点自己到自己是没有边的,现在是自己有一条边又到达了自己,也就是增加一个自连接,然后重新计算一个度矩阵,然后就得到重新归一化的拉普拉斯矩阵,然后代入化成矩阵相乘的形式就是右边这个式子。这样卷积就定义完了,其中输入就是图信号X,卷积核就是Θ,前面的东西就是一个常量,只要拥有这三部分就可以得到GCN的卷积。卷积定义完了,然后加一个relu激活函数,这样一层图卷积就定义完了,如果要叠加一层,就是把上一层图卷积输出后的表示作为图卷积的输入,再做一次卷积。因为这篇论文做的是分类任务,所以要输出每个节点属于某个类的概率,所以用一个softmax就可以输出概率。
形象的解释:每个节点拿到邻居节点信息然后聚合到自身Embedding上。在上面的公式中,$\tilde{D}^{-\frac{1}{2}}\tilde{A}\tilde{D}^{-\frac{1}{2}}$可以看做是归一化后的邻接矩阵。$X\Theta$相当于对原始节点的Embedding做一次线性变换,左乘邻接矩阵表示对每个节点来说,该节点的特征变为邻居节点特征相加后的结果。
这就是现在谱图卷积计算的式子,实际
2020.2.17更新
2.2.5. 图卷积多种形式
1. $f(H^{(l)},A) = \sigma(AH^{(l)}W^{(l)})$ 直接将$AH$做矩阵相乘,然后再通过一个权重矩阵$W^{(l)}$做线性变换,之后再经过非线性激活函数$\sigma(·)$,例如$ReLU$,最后得到下一层的输入$H^{(l+1)}$。表示每次只聚合其邻居,将邻居的值加起来作为中心结点新的特征表示。 有以下**问题**: - 虽然获取了周围节点的信息,但是**自身的信息却没了**,除非邻接矩阵中有自连接。解决方案:对每个节点手动增加一条`self-loop`到每一个节点,即$\hat{A}=A+I$,其中$I$是单位矩阵 2. $f(H^{(l)},A) = \sigma(\hat{A}H^{(l)}W^{(l)})$在邻接矩阵中加入自连接,每次聚合邻居和自身的值,加起来作为中心结点新的特征表示。$\hat{A}=A+I$,其中$I$是单位矩阵
这里直接将权重矩阵$A$和图信号矩阵$H$相乘,表示对于每个节点,将其邻居的特征加起来作为其新的表示。
有以下问题:
- $A$没有归一化,经过一层变换,每个节点特征都会变成邻接特征之和,这样得到的输出会越来越大,即特征向量$X$的scale会改变,在经过多层的变化之后,和输入的scale差距越来越大。
解决方案:原先邻接矩阵$A$中的值非0即1,现在对邻接矩阵$A$做归一化,使得每一行之和为1,使得$AH$获得的是weighted sum,做法是:将$A$的每一行除以行的和(即每个节点的度),这就可以得到normalized的$A$,则新的邻接矩阵表示为$A=D^{-1}A$,对于邻接矩阵中的每个值变成$A_{ij}=\frac{A_{ij}}{d_i}$。$\boldsymbol{D}^{-1} \boldsymbol{A}$表示扩散卷积中的转移矩阵。$(\boldsymbol{D}^{-1} \boldsymbol{A})^k$表示$k$步转移
- 但是在实际运用中,我们通常使用对称的
normalization,
$A=D^{-\frac{1}{2}}AD^{-\frac{1}{2}}$,对于$A_{ij}=\frac{A_{ij}}{\sqrt{d_i}\sqrt{d_j}}$
结合公式2和公式4,将邻接矩阵$A$加上自连接变成$\hat{A}$,同时使用对称 normalization,得到公式5
【注意】图卷积实质上就是全连接,filter的个数就是全连接中神经单元个数
3. 动态图
一般的图卷积的输入维度是(batch_size,N,C),即只有一个时间段,但如果输入的是动态图即(batch_size,T,N,C),该怎么办?
(batch_size,T,N,C)-->(batch_size,T*N,C)-->(T*N,batch_size,C),例如《Spatial-Temporal Synchronous Graph Convolutional Networks: A New Framework for Spatial-Temporal Network Data Forecasting》(AAAI2020),将时间T乘到节点N上,需要对邻接矩阵进行变换成(TN,TN)的形式,才可以和h相乘。不常用,除非对邻接矩阵A进行变换(batch_size,T,N,C)-->(batch_size,N,T*C),可以先经过一个FCN,将其转换为(batch_size,N,D),然后再输出到GCN中,也可以不经过FCN,直接输入到GCN中。较常用,例如《RiskOracle: A Minute-level Citywide Traffic Accident Forecasting Framework》(AAAI2020)
【参考资料】
图卷积网络(GCN)入门详解
4. 总结
- 顶点域和谱域的区别:谱域需要用到对拉普拉斯矩阵分解,找到一组基U。顶点域不需要使用基
- 图卷积的核心思想是利用『边的信息』对『节点信息』进行『聚合』从而生成新的『节点表示』
- 谱图卷积由于L具有对称性,只能用在无向图中

