在做项目的过程中用到了HBase,遇到了一些问题,当数据过大的时候,向HBase中会出现热点问题。
1. 问题描述
HBase默认建表时有一个分区(region),这个region的rowkey是没有边界的,即没有startkey和endkey,hbase的中的数据是按照字典序排序的,在数据写入时,所有数据都会写入这个默认的region,随着数据量的不断增加,此region已经不能承受不断增长的数据量,当一个region过大(达到hbase.hregion.max.filesize属性中定义的阈值,默认10GB)时,会进行split,分成2个region。在此过程中,会产生两个问题:
- 数据往一个region上写,会有写热点问题。
- region split会消耗宝贵的集群I/O资源。
2. 解决方案
基于此我们可以控制在建表的时候,创建多个空region,并确定每个region的起始和终止rowky,这样只要我们的rowkey设计能均匀的命中各个region,就不会存在写热点问题。自然split的几率也会大大降低。当然随着数据量的不断增长,该split的还是要进行split。像这样预先创建hbase表分区的方式,称之为预分区,下面给出一种预分区的实现方式:
解决这个问题,关键是要设计出可以让数据分布均匀的rowkey,与关系型数据库一样,rowkey是用来检索记录的主键。访问hbase table中的行,rowkey 可以是任意字符串(最大长度 是 64KB,实际应用中长度一般为 10-100bytes),在hbase内部,rowkey保存为字节数组,存储时,数据按照rowkey的字典序排序存储。
预分区的时候首先需要指定按什么来划分rowkey,
设计的rowkey应该由regionNo+messageId组成。设计rowkey方式:随机数+messageId,如果想让最近的数据快速get到,可以将时间戳加上,原先我们设计的行键是数据产生的时间,格式为2018-01-21 12:23:06,没有设置预分区,这样数据就会出现热点问题。
2.1. 错误的预分区
后来采用预分区的方式,按照秒进行预分区,splitKeys={“01|”,”02|”,…”59|”},在设计行键的时候在原先的时间上再添加当前的秒数,例如原先的行键是2018-01-21 12:23:06,现在的行键是062018-01-21 12:23:06,这样在存储的时候行键的前2个字符06,我这里的region是01|到59|开头的,因为hbase的数据是字典序排序的,行键开头为06,06大于05,并且06后面字符的ASCII码小于|,则当前这条数据就会保存到05|~06|这个region里。rowkey组成:秒数+messageId,因为我的messageId都是字母+数字,“|”的ASCII值大于字母、数字。
下图展示了HBase的分区情况。第一个分区没有startKey,endKey为01|,表示比01|小的行键都存储在这里,那就是以00和01开头的行键都存储在这里,最后一个分区的startKey是59|,表示比59大的存储在这个分区里,但是一分钟内的秒数没有比59大的,所以request一直是0。这份分区是不对的,正确的分区是splitKeys={“00|”,”01|”,…”58|”}
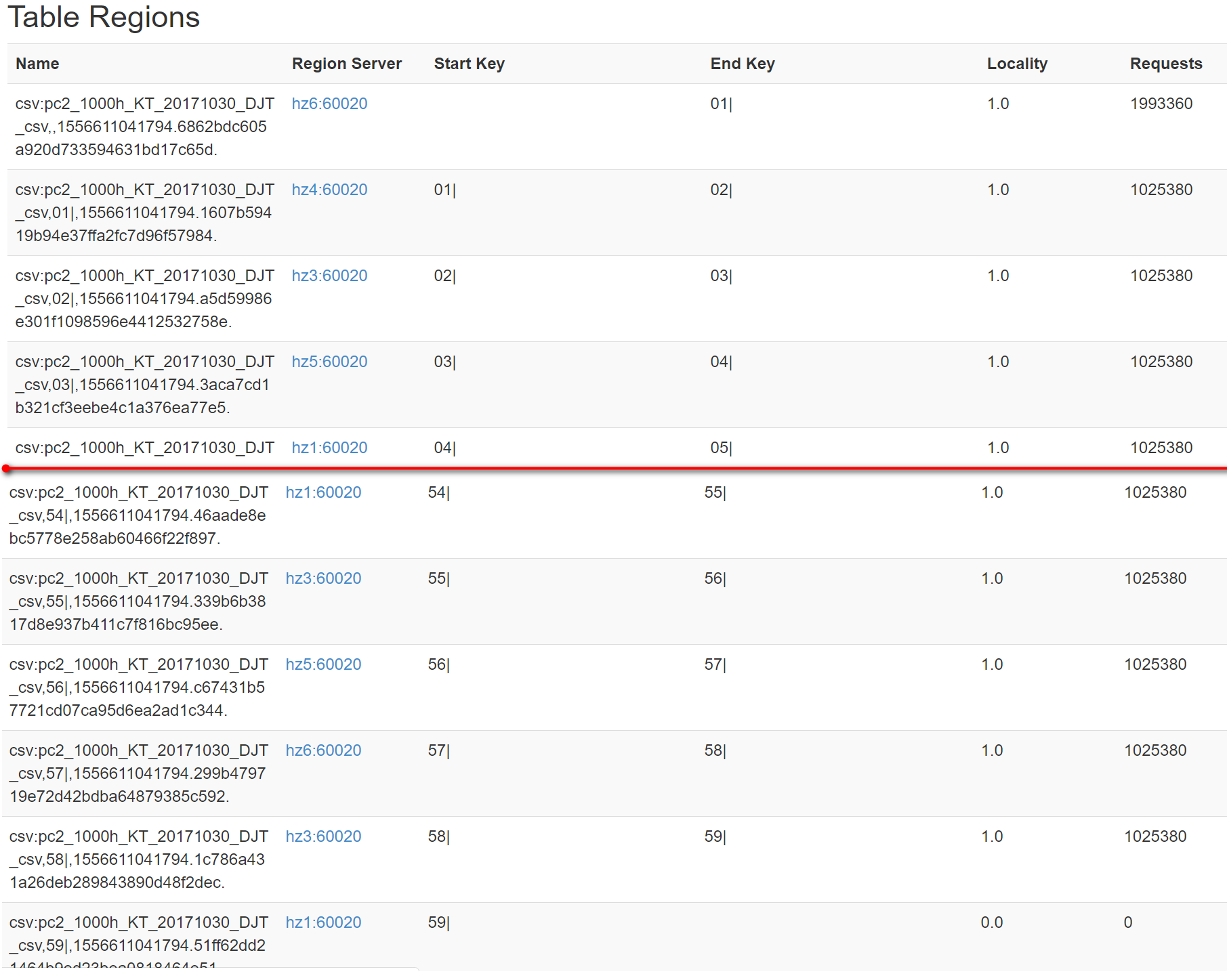
2.2. 正确的预分区
需要注意的是,行键分配值按照rowkey的前几个字符进行匹配的,并不是按照数的大小。例如分区是 -10,10-20,20-30,30-40,40-50,50-60,60-70,70-80,80-90,90-,如果插入的数据rowkey是80 60 22这种两位数,肯定会落到某个分区,如果rowkey是100 333 9955 555544 66910 这种大于两位值,都会落在最后一个分区,还是只取rowkey的前两位与startkey/endkey对应?答案是:是按前两位匹配rowkey的。
1 | private byte[][] getSplitKeys() { |
需要注意的是,在上面的代码中用treeset对rowkey进行排序,必须要对rowkey排序,否则在调用admin.createTable(tableDescriptor,splitKeys)的时候会出错。创建表的代码如下:
1 | /** |
HBase中出现热点问题带来的影响是:(1)在我们的项目中,原先使用一个分区,等到这个分区容量达到阈值时,这个分区开始split,然后数据来的时候就会向第二个分区写数据,不会向第一个region中写数据,所以在某一时候只能向一个region中写数据,这样写的速度会变慢。(2)在读数据的时候,因为行键设置的时间,连续的时间一般存储在一个region中,所以读数据的时候也是从一个region中读取数据,读取的速度也会变慢。项目原先应对取数据慢的问题解决方案使用HBase的scan函数,设置起始和终止的行键,使用scan查询数据。
按秒对表进行预分区时,就相当于把数据均匀分布在60个region中,存储一段时间的数据时,会同时向60个region中写入数据,取数据的时候也会同时从60个region中取数据。这样取数据的时候就不能使用起止行键用scan来查询数据了,只能使用getRow来查询数据,但是这样查询的性能也不会很差,因为是从60个region中同时查询数据,使用scan的时候是从1个region中查询数据。
HBase行健设计原则
HBase是面向列的存储结构,实际存储单元里存储的都是KeyValue结构。
KeyValue的整体结构为:Key Length + Value Length + Key + Value
其中Key包括以下7部分。
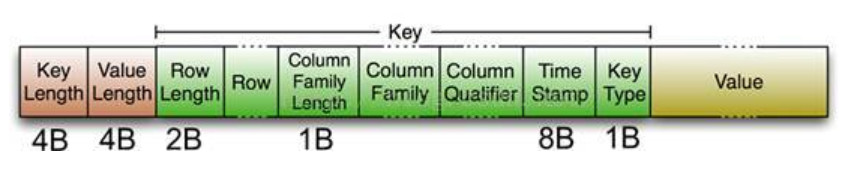

在HBase中,每一个单元格都是用KeyValue存储,对于一行数据,有n个列,则会有n个KeyValue数据结构来存储。虽然这n个列的行健是一样的,所以行健会存储n份。
HBase中的数据按照行健的ASCII字典顺序进行全局排序的。举例说明:假如有 5 个 Rowkey:”012”, “0”, “123”, “234”, “3”,按 ASCII 字典排序后的结为:”0”, “012”, “123”, “234”, “3”。
- 行健长度原则:建议在10~100个字节
- 行健散列原则:在行健的开始几个字符作为散列字段,用来分区使用。设计的行健应该使数据均匀的分布在各个HBase的节点上。
- 行健唯一性原则
Rowkey避免热点的方法
- 加盐
如果行健前面几个字符相等,导致数据往一个region中存储,我们可以在Rowkey前面随机添加一个字符串。加盐是在Rowkey前面添加随机数,使得数据分布在不同的region中。 - Hash散列或Mode取模
将行健做散列,可以将负载分散到整个集群中。
如果行健是数字,可以用取模的方式。 - 反转
将rowkey反转,增加rowkey的随机性,但是牺牲了rowkey的有序性。 - 时间戳反转
比如使用Long.Max_Value - timestamp作为行健,这样第一条数据就是最后录入的数据。
行健设计经验
- 可枚举较少的值放在rowkey前面
数量较少,可控的属性放在rowkey的前面 - 业务经常访问的属性放在前面
例如业务经常访问某一天内所有的URL,经常使用date来查询,则在主键中,可以将date放在前面 - 时间属性经常在rowkey中使用

