1. 词嵌入
词向量就是用来表示词的向量,也可以是词的特征向量或表征。把词映射成向量的技术叫词嵌入。
前几天看到了一篇讲解Word2Vec的推送,讲的超级好,通俗易懂。
一种最简单的词嵌入是one-hot向量,每个词使用非0即1的向量表示。这样构造虽然简单,但不是一个好的选择。因为one-hot词向量无法准确表达不同词之间的相似度,如我们常常使用的余弦相似度,因为任何两个不同词的one-hot向量的余弦相似度都为0,多个不同词之间的相似度很难通过one-hot向量准确表示出来。
word2vec工具的提出正是为了解决上面的问题。2013年Google团队发表了word2vec工具。它将每个词表示成一个定长的向量,并使得这些向量可以较好地表达不同词之间的相似和类比关系。word2vev包含了2个模型:跳字模型(skip-gram)和连续词袋模型(continuous bag of words CBOW)。以及2种高效训练的方法:负采样(negative sampling)和层序softmax(hierarchical softmax)。
skip-gram是给定一个中心词,计算周围词出现的概率。在skip-gram中每个词被表示成2个d维向量。当它为中心词时向量被表示成$v_i\in\mathbb{R}^d$,当它为背景词时向量被表示成$u_i\in\mathbb{R}^d$。给定中心词生成背景词的条件概率可以通过softmax运算得到:
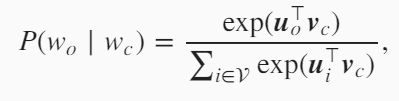
假设中心词是loves,判断根据loves生成背景词son的概率,分子是loves的中心词向量和son的背景词向量做内积,分母是除去loves的所有词的背景词向量分别和loves的中心词向量做内积,再相加。然后分子/分母得到根据loves生成son的概率。
假设给定一个长度为$T$的文本序列$w^{(t)}$。假设给定中心词的情况下背景词的生成相互独立,当背景窗口大小为$m$时,跳字模型的似然函数即给定任一中心词生成所有背景词的概率。
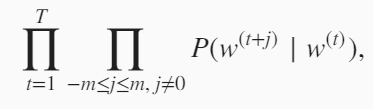
文本序列是预先给定的,已经有一句话了。首先时间$t=1$,确定一个中心词,然后根据这个中心词计算背景词的概率,把2m个概率相乘。然后t+1,再找下一个中心词,再计算这个中心词生成背景词的概率,再把2m个概率相乘,直到中心词到最后一个。
训练skip-gram模型就是为了得到每个词的中心词向量和背景词向量,每个词所对应的的中心词向量和背景词向量是skip-gram的模型参数。训练中通过最大化似然函数来学习模型参数,即最大化似然估计。训练结束后,我们可以得到字典中所有词的中心词向量和背景词向量。在自然语言处理应用中,一般使用skip-gram的中心词向量作为词的表征向量。
连续词袋模型基于背景词来生成中心词。比如一个句子the man - his son,根据前后4个词预测中间的词。也是通过最大化似然函数来训练得到字典中每个词的中心词向量和背景词向量。和跳字模型不一样的是,我们一般使用连续词袋模型的背景词向量作为词的表征向量。
但是skip-gram和CBOW的计算开销都比较大,下面介绍2个近似训练法:负采样和层序softmax.通过这2种方法可以减小训练开销。
1.1. 负采样
跳字模型的核心在于使用softmax运算得到给定中心词$w_c$来生成背景词的概率。
由于softmax运算考虑了背景词可能是词典$\mathcal{V}$中的任一词,在计算损失函数时计算了所有背景词的损失。不论是跳字模型还是连续词袋模型,由于条件概率使用了softmax运算,每一步的梯度计算都包含词典大小数目的项的累加。对于含几十万或上百万词的较大词典,每次的梯度计算开销可能过大。为了降低该计算复杂度,本节将介绍两种近似训练方法,即负采样(negative sampling)或层序softmax(hierarchical softmax)。
在CBOW模型中,已知词$w$的上下文$Context(w)$,需要预测$w$,因此对于$Context(w)$,词$w$就是一个正样本,其他词就是一个负样本。从所有的负样本中选择一个负样本子集。训练的目标就是增大当上下文为$Context(w)$时,中心词$w$出现的概率,并且同时降低负样本的概率。
对于一个给定的词$w$,怎么生成这个词的负采样子集$NEG(W)$?
词典中的词出现的次数有高有低,对于那些高频词,被选为负样本的概率就比较大,对于那些低频词,被选中负样本的概率就小,本质上就是一个带权采样问题。对于一对中心词和背景词,随机采样K个负样本,论文中的建议K=5,负样本采样的概率$P(w)$设为$w$词频与总词频之比的$3/4$次方。

在训练中,首先给出所有的句子。对于skip-gram模型负采样,给定一个中心词预测周围的词。对于一个句子,首先把语料分割成(context(w),w)样本,对于每一个中心词,都可以在这个句子中找出这个中心词的背景词(周围词),并在词典中找出这个中心词的负样本(非背景词),一个中心词的负样本论文建议个数为5,就是对于一个中心词找出5个负样本。对语料进行预处理形成以下数据集:一个样本包括一个中心词,它所对应的n个背景词,m个噪声词(负样本)。每个样本的背景词窗口大小可能不一样,即每个中心词的背景词和噪声词的个数可能不一样。
负采样通过考虑同时含有正类样本和负类样本的相互独立事件来构造损失函数。其训练中每一步的梯度计算开销与采样的噪声词的个数线性相关。
1.2. 层序Softmax
使用哈夫曼二叉树来存储词典,叶子节点就是字典$\mathcal{V}$中的每个词,非叶子节点就是一些隐藏向量。
层序Softmax使用了二叉树,并根据根节点到叶结点的路径来构造损失函数。其训练中每一步的梯度计算开销与词典大小的对数相关。
1.3. 实现步骤
给定一个训练集,首先对数据进行处理,给定一个背景词窗口大小,对于每一个中心词,找到中心词在句子中的背景词、噪声词。这就是训练集,其中一个样本是(第i个中心词,n个背景词,m个噪声词),使用这些样本作为训练。
嵌入层不需要自己写,直接使用Embedding来定义,根据嵌入层可以获取一个词的词向量。嵌入层有一个嵌入矩阵,输入是词典的大小(词的个数),输出是词向量的纬度。所以嵌入矩阵的维度为(词典大小,词向量维度)。嵌入层的输入是语料库中的词的索引[0,1,2,3…],输入一个词的索引i,嵌入层返回权重矩阵的第i行作为它的词向量。
skip-gram的输入是包含中心词索引向量,背景词和噪声词索引向量。这2个向量先通过嵌入层得到词向量,然后输出中心词向量与背景词向量噪声词向量的内积作为中心词的词向量。
发展
在word2vec提出来之后,之后又有了新的发展。在2014年Stanford团队提出了GloVe,在2017年Facebook提出了fastText。其中GloVe提出两个词共现的概率,用词向量表达共现词频的对数。fastText提出每个词都是由子词提出来的,把中心词向量表示成所有子词的词向量的和。
2. Seq2Seq
原先都是给定一个不定长的序列,输出一个定长的序列。比如给定一个不定长的序列预测下一个词。在自然语言处理中,输入和输出都可以是不定长序列。以机器翻译为例,输入可以是一段不定长的英语文本序列,输出也可以是一段不定长的法语文本序列。当输入和输出都是不定长序列时,我们可以使用编码器-解码器(encoder-decoder)或者seq2seq模型。这两个模型本质上都用到了两个循环神经网络,分别叫做编码器和解码器。编码器用来分析输入序列,解码器用来生成输出序列。
Seq2Seq就是RNN Encoder-Decoder,其中的RNN通常是LSTM。 序列到序列模型就像一个翻译模型,输入是一个序列,输出也是一个序列。这种结构最重要的是输入和输出序列的长度是可变的。
图10.8描述了使用编码器—解码器将上述英语句子翻译成法语句子的一种方法。在训练数据集中,我们可以在每个句子后附上特殊符号“\
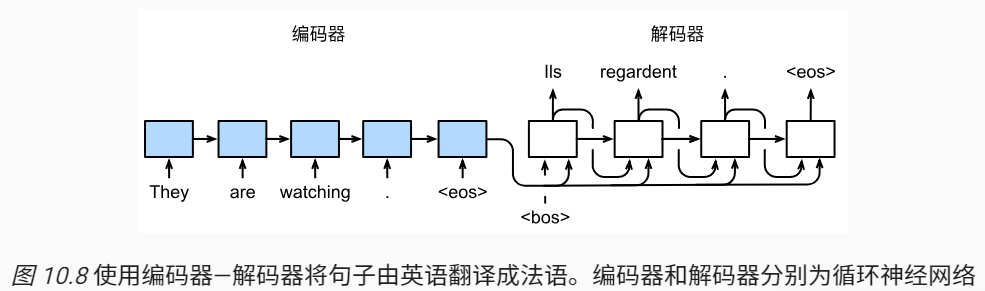
2.1. 编码器
编码器的作用是把一个不定长的输入序列变成一个定长的背景变量$c$,并在该背景变量中编码输入序列信息。常用的编码器是循环神经网络。背景变量$c=q(h_1,…h_T)$,编码器通过自定义函数$q$将各个时间步的隐藏状态变换成背景变量
2.2. 解码器
编码器输出的背景变量$c$编码了整个输入序列$x_1,…x_T$的信息。给定训练样板中的输出序列$y_1,…y_{T’}$,对每个时间步$t’$,解码器输出$y_{t’}$的条件概率将基于之前的输出序列$y_1,…y_{t’-1}$和背景变量$c$,即$P(y_t’|y_1,…y_{t’-1},c)$。为此,我们可以使用另一个循环神经网络作为解码器。在时间步$t’$,解码器根据背景变量$c$,上一时间步的输出$y_{t’-1}$和上一时间步的隐藏变量$s_{t’-1}$来生成当前时间步的隐藏变量$s_{t’}$。有了解码器的隐藏状态后,我们可以使用自定义的输出层和softmax运算来计算生成当前时间步的输出$y_{t’}$。即计算的顺序是:先根据背景变量$c$,上一时间步的输出$y_{t’-1}$和上一时间步的隐藏变量$s_{t’-1}$来生成当前时间步的隐藏变量$s_{t’}$,然后再根据当前时间步的隐藏状态$s_{t’}$生成当前时间步的输出$y_{t’}$。
3个小trick:
- 解码器什么时候停止?当预测的下一个词是\
时停止。 - 对于解码器,当生成第一个隐藏状态$s_1$时,需要给定$s_0,y_0和c$,其中$y_0=
$对应的词向量 - 对于编码器,生成第一个隐藏状态$h_1$时,需要给定当前的输入$x_1和上一时刻的隐藏状态h_0$,$h_0$可以初始化为全零的向量。对于编码器,$s_0$也可以初始化为全零向量。也可以初始化为$s_0=tanh(W\overleftarrow{h_1})$,编码器从右向左输入,最后得到第一个词的隐藏向量,然后用来初始化解码器的$s_0$
2.3. 优缺点
encoder-decoder模型虽然非常经典,但是局限性也非常大。最大的局限性就在于编码和解码之间的唯一联系就是一个固定长度的语义向量C。也就是说,编码器要将整个序列的信息压缩进一个固定长度的向量中去。但是这样做有两个弊端,一是语义向量无法完全表示整个序列的信息,还有就是先输入的内容携带的信息会被后输入的信息稀释掉,或者说,被覆盖了。输入序列越长,这个现象就越严重。这就使得在解码的时候一开始就没有获得输入序列足够的信息, 那么解码的准确度自然也就要打个折扣了
3. Attention
Attentions详细讲解
Attention一般有2种,(1):Location-based Attention,这里的attention没有其他额外需要关注的对象,即多个$h_i$内部做attention。(2)Concatenation-based Attention:有额外需要关注的对象,即多个$h_i$对$h_t$的attention。我们平时用第2种比较多一些。
在上面的编码器-解码器中,从编码器传到解码器的背景变量$c$是不变的。就是说解码器在翻译第一个词和第二个词是c是不变的。但是实际情况中,比如英语they are watching。翻译成法语是:IIs regardent。比如在翻译IIS时,和they are更相关,在翻译regardent和watching更相关,所以希望把背景变量$c$设置成一个变化的值。当翻译IIS时,对编码器的隐藏变量$h_1,h_2$更看重,当翻译regardent对隐藏变量$h_3$更看重,所以就需要在解码器中,在不同时间步时,对编码器的隐藏变量$h_1,h_2,h_3$分配不同的权重,加权平均得到背景变量$c$。
原先解码器隐藏层变量的计算是上一时刻的输出$y_{t’-1}$,上一时刻的隐藏状态$s_{t’-1}$以及背景变量$c$,在加入attention机制后,这里的背景变量变成了$c_{t’}$,每一步的背景变量都不一样。
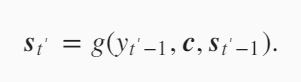
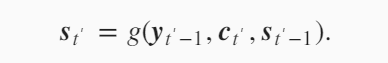
下面看一下$c_{t’}$是怎么设计的。 就是编码器的不同时刻的隐藏状态的加权平均。只是这里的权重$\alpha_{t’t}$在每一个时刻是一个变化的值。 注意这里的$t’$是输出(解码器)的时间戳,$t$是输入(编码器)的时间戳。首先我们先固定$t’$,下面的式子中$t’$是不变的。在计算$c_{t’}$时,变化$t从1到T$,遍历所有的$h_t$,然后给定一个$h_t$,怎么求$h_t$对应的权重$\alpha_{t’t}$。
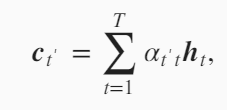
下面我们看一下$\alpha_{t’t}$是怎么来表示。加权平均就要使所有的权值加起来为1,所以用到softmax运算。softmax中的每一个值是
$e$,这个是怎么计算的.$e_{t’t}$通过解码器上一时刻的隐藏变量$s_{t’-1}$和当前编码器的隐藏变量$h_t$计算得到。
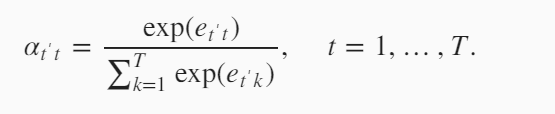
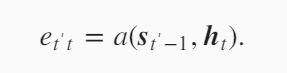
注意力机制对函数$a$设计有很多。下面是一种设计方法。首先一定要有$s_{t’-1}$和$h_t$。然后引入了3个模型参数$v^T,W_s,W_h$,这3个参数通过训练得到。对$s_{t’-1}$做一个projection,对$h_t$做一个projection,使得projection之后的向量长度相等,这样就可以加在一起,然后使用tanh激活函数,这时的向量长度还是projection之后的长度,但是我们希望$e_{t’t}$是一个标量,那就再引入向量$v^T$,和右边的向量做一个点乘得到一个标量。其实注意力可以通过多层感知机(全连接层)得到。

下面介绍计算解码器的隐藏变量时的函数$g$是什么?g可以看到是一个GRU单元

这里总结一下模型的参数都有哪些:编码器中的W和b,上式中解码器中的W和b,还有计算attention中的$v^T,W_s,W_h$。

